Reformer:一个高效的 Transformer
文 / Nikita Kitaev, 学生研究员, 加利福尼亚大学伯克利分校与 Łukasz Kaiser, 研究科学家, Google Research

理解语言、音乐或视频之类序列数据 (Sequential Data) 的任务充满挑战,尤其是当这些数据依赖于时间跨度较广的上下文时。
例如,在一个视频中,如果某个人或某个物体在消失很长一段时间后才重新出现,许多模型会忘记它的样子。而在语言领域,长短期记忆 (LSTM) 神经网络会考虑足够多的上下文来执行逐句翻译。在这种情况下,上下文窗口 (Context Window) 的范围(即翻译中考虑的数据范围)会涵盖数十到上百个单词。
最新的 Transformer 模型不仅提高了逐句翻译的性能,而且可以用于通过多文档摘要生成完整的 Wikipedia 文章。由于 Transformer 使用的上下文窗口扩展到了数千个单词,使上述情景得以实现。凭借宽泛的上下文窗口,Transformer 的应用范围从文本扩展到了包括像素、音符在内的其他场景,可以用于生成音乐和图像。
但是,Transformer 的上下文窗口有限制范围。
Transformer 的强大来源于 注意力 (Attention) 机制,通过这一机制,Transformer 将上下文窗口内所有可能的单词对纳入考虑,以理解它们之间的联系。因此,如果文本包含 10 万个单词,Transformer 将需要评估 100 亿单词对(10 万 x 10 万),这显然不切实际。另一个实践问题是如何保存每个模型层的输出。对于使用大型上下文窗口的应用来说,存储多个模型层输出的内存需求会迅速变得过大(从几层模型层的数 G 级别到数千层模型层的数 T 级别)。这意味着,实际使用大量层的 Transformer 模型只能用于生成几小段落的文本或一小段的音乐。
今天,我们推出了 Reformer,一个设计为处理多达 100 万单词的上下文窗口的 Transformer 模型,所有工作在单个加速器上进行且仅使用 16 GB 内存。此模型将综合运用两种关键技术来解决 Transformer 在长上下文窗口的注意力和内存分配问题的应用限制。Reformer 使用局部敏感哈希 (Locality-Sensitive-Hashing, LSH) 来降低长序列的处理复杂度和可逆残差层,从而更有效地使用可用内存。
注意力问题
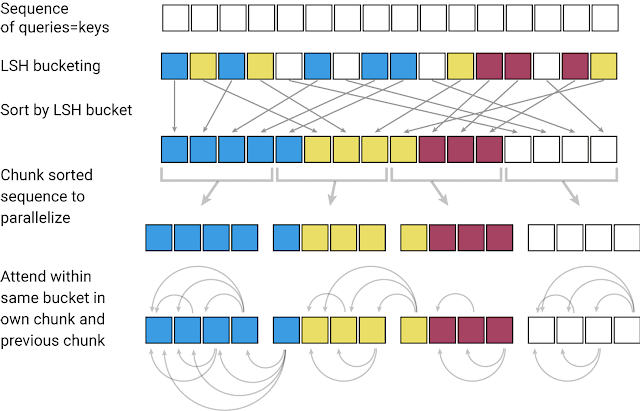
局部敏感哈希:Reformer 接收 Key 的序列,其中每个键值代表首层中每个单词(在图像的情况下为像素)和后续层中大量的上下文向量。将局部敏感哈希应用到序列之后,依照键值的哈希值对其排序并分块。注意力仅针对于单个区块及其直接邻块
内存问题
虽然局部敏感哈希解决了注意力问题,但仍然存在内存问题。
一个单层的网络一般需要多达几 GB 的内存以及单个 GPU,因此,单层能够执行长序列的单模型。但是,当使用梯度下降训练多层模型时,由于需要保存每一层的激活(函数),以用于执行逆推。一个传统的 Transformer 模型具有十几个或更多的层,通过缓存这些层的值,内存将会很快用完。
第二种 Reformer 中实现的新方法是在反向传播期 (Back-Propagation) 间,按需重新计算每个层的输入,而不是将其保存在内存中。这是使用可逆层来实现的,其中来自网络最后一层的激活 (Activation) 用于还原来自任何中间层的激活 (Activation),这相当于反向运行网络。
在典型的残差网络中,通过网络传递的输入将会向堆栈中的每一层不断添加至向量。相反,可逆层中每个层有两组激活。一组遵循刚才描述的标准过程,从一层逐步更新到下一层,但是另一组仅捕获第一层的变更。因此,若要反向运行网络,只需简单地减去每一层应用的激活。
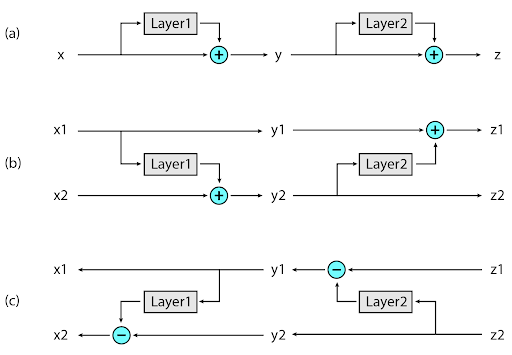
可逆层:(图 a)在标准残差网络中,每一层的激活用于将输入更新到下一层。(图 b)在可逆网络中,将会维持两组激活,只有其中一组逐层更新。(图 c)这种方法可使网络反向运行,以还原所有中间值
Reformer 的应用
这两种新方法能让 Reformer 具有更高的效率,可以在仅有 16GB 内存的单个加速器上处理长达一百万个单词的文本序列。正因为 Reformer 的高效率,可以被直接应用于上下文窗口远大于任何最新 (SOTA) 文本域数据集的数据。借助 Reformer 能处理如此大规模数据集的能力,可促进社区创建大规模数据集的速度。
在不缺乏大规模上下文数据的领域中,我们选择图像生成作为我们实验 Reformer 的对象。在这份 Colab 笔记[1]中,我们提供了一些示例,说明如何使用 Reformer 将部分图像变得“完整”。从下图上行所示的图像片段开始,Reformer 可以逐像素生成全画幅图像(下行)。

上行:用于输入 Reformer 的图像片段。下行:“已完成的”全画幅图像。原始图像来源于 Imagenet64 数据集
Reformer 不仅仅在处理图像和视频任务中的应用有巨大的潜力,其在文本中的应用更加令人兴奋。Reformer 可以在单一设备上一次处理完整部小说。这份 Colab 笔记[2]演示了在单个训练示例中处理《罪与罚》(Crime and Punishment) 的全部内容。将来会有更多的带有长文本的数据集需要训练,诸如 Reformer 之类的技术让生成条理清楚的长篇作品成为可能。
结论
我们相信,无论是在长文本还是自然语言处理之外的应用,Reformer 为将来使用 Transformer 模型提供了基础。
遵循公开研究的传统,我们已经开始探索如何将 Reformer 应用于更长的序列以及如何改善位置编码的处理。阅读这篇 Reformer 论文(选自 ICLR 2020 上的口头演讲),探索我们的代码并生成自己的创意。
虽然深度学习中尚未广泛使用长上下文数据集,但在现实世界中比比皆是。也许这可以激发您找到 Reformer 的新应用,这份 Colab 笔记[3]可作为您的起点,如果遇到任何问题或疑问,欢迎与我们沟通!
致谢
此项研究由 Nikita Kitaev、Łukasz Kaiser 和 Anselm Levskaya 共同完成。另外还要感谢 Afroz Mohiuddin、Jonni Kanerva 和 Piotr Kozakowski 在 Trax 上的工作,并感谢整个 JAX 团队的支持。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
逐句翻译
https://ai.googleblog.com/2016/09/a-neural-network-for-machine.htmlTransformer 模型
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html完整的 Wikipedia 文章
https://arxiv.org/abs/1801.10198音乐
https://magenta.tensorflow.org/music-transformer图像
https://ai.google/research/pubs/pub46840/Reformer
https://github.com/google/trax/tree/master/trax/models/reformer可逆残差层
https://arxiv.org/abs/1707.04585可逆层
https://arxiv.org/abs/1707.04585Colab 笔记[1]
https://colab.research.google.com/github/google/trax/blob/master/trax/models/reformer/image_generation.ipynbImagenet64 数据集
https://arxiv.org/abs/1707.08819Colab 笔记[2]
https://colab.research.google.com/github/google/trax/blob/master/trax/models/reformer/text_generation.ipynb公开研究
https://twitter.com/jekbradbury/status/962121602421829632更长的序列
https://github.com/google/trax/blob/master/trax/models/reformer/reformer.py#L616改善位置编码的处理
https://github.com/google/trax/blob/master/trax/models/research/position_lookup_transformer.pyReformer 论文
https://arxiv.org/abs/2001.04451我们的代码
https://github.com/google/traxColab 笔记[3]
https://colab.research.google.com/github/google/trax/blob/master/trax/intro.ipynb与我们沟通
https://gitter.im/trax-ml/community