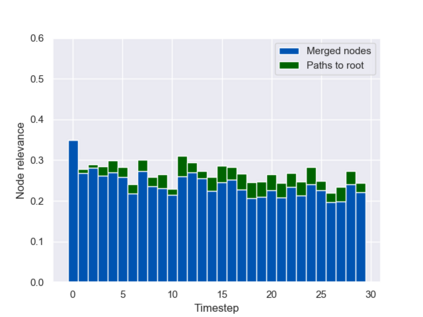
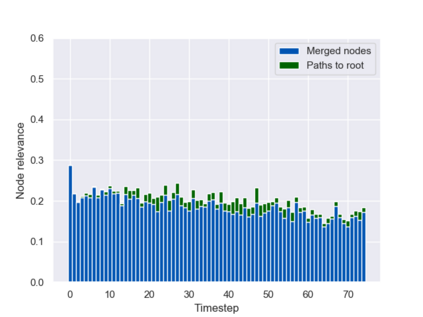
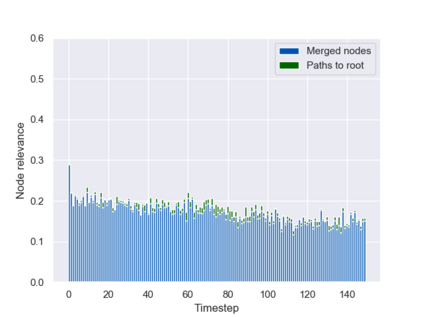
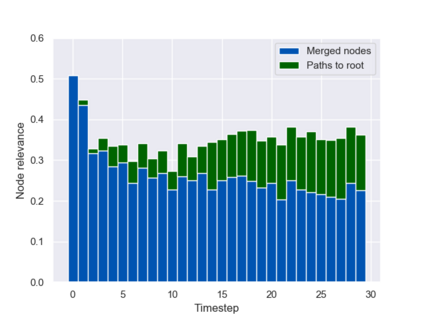
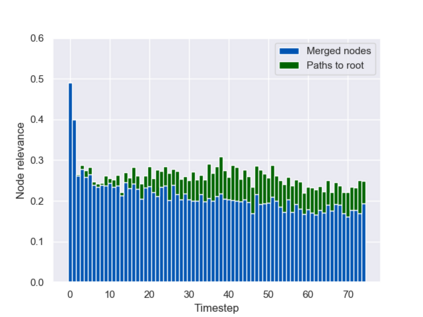
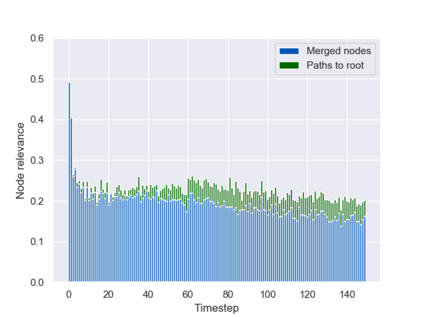
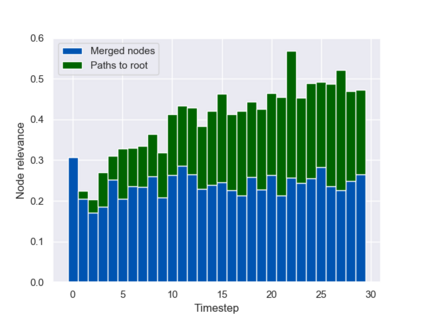
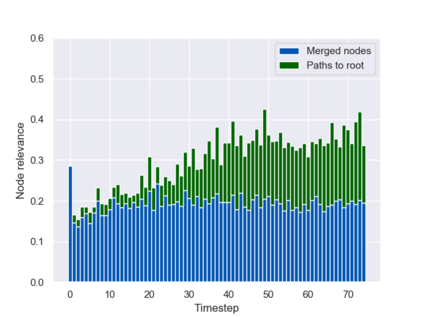
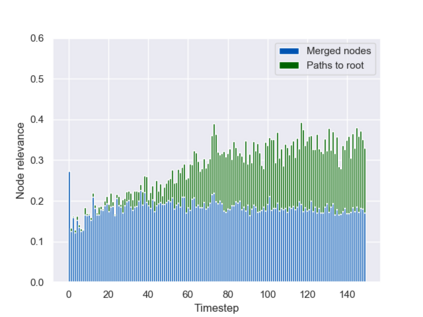
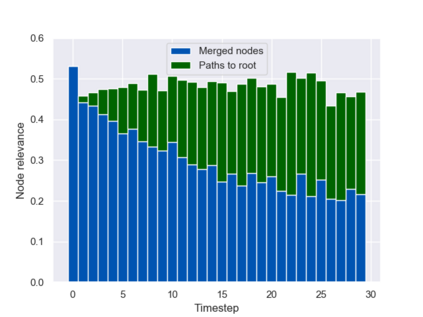
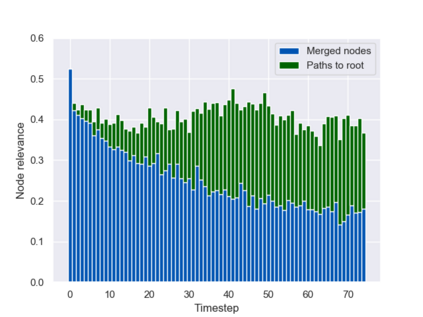
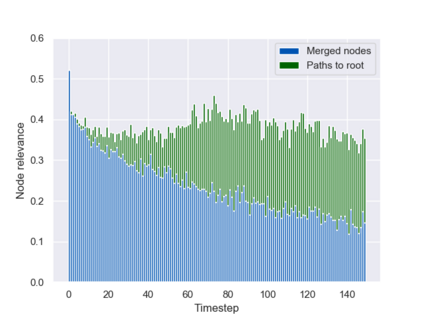
Graph neural networks (GNNs) are typically applied to static graphs that are assumed to be known upfront. This static input structure is often informed purely by insight of the machine learning practitioner, and might not be optimal for the actual task the GNN is solving. In absence of reliable domain expertise, one might resort to inferring the latent graph structure, which is often difficult due to the vast search space of possible graphs. Here we introduce Pointer Graph Networks (PGNs) which augment sets or graphs with additional inferred edges for improved model expressivity. PGNs allow each node to dynamically point to another node, followed by message passing over these pointers. The sparsity of this adaptable graph structure makes learning tractable while still being sufficiently expressive to simulate complex algorithms. Critically, the pointing mechanism is directly supervised to model long-term sequences of operations on classical data structures, incorporating useful structural inductive biases from theoretical computer science. Qualitatively, we demonstrate that PGNs can learn parallelisable variants of pointer-based data structures, namely disjoint set unions and link/cut trees. PGNs generalise out-of-distribution to 5x larger test inputs on dynamic graph connectivity tasks, outperforming unrestricted GNNs and Deep Sets.
翻译:静态输入结构通常纯粹通过机器学习实践者的洞察力来告知另一个节点,然后通过这些指示器传递信息。这种可调整的图形结构的宽度使得学习具有可移动性,同时仍然对模拟复杂算法具有足够清晰的表达力。关键是,指示机制直接监督到典型数据结构的长期操作序列模型中,包括理论计算机科学中有用的结构诱导偏差。从性质上看,我们证明PGNs可以学习基于点的数据结构的平行变体,即不同步的组合和连接/连接到更深层的GGNS树。