语言学家重出江湖!从「发音」开始学:这次AI模型要自己教自己
![]()
新智元报道

新智元报道
【新智元导读】AI模型不光要学会理解语言,还得成为语言学家!
试图让计算机理解人类的语言一直是人工智能领域迈不过的难关。
早期的自然语言处理模型通常采用人工设计特征,需要专门的语言学家手工编写pattern,但最终效果却并不理想,甚至AI研究一度陷入寒冬。
每当我开除一个语言学家,语音识别系统就更准确了。
Every time I fire a linguist, the performance of the speech recognizer goes up.
——Frederick Jelinek
有了统计模型、大规模预训练模型以后,特征抽取是不用做了,但仍然需要对指定任务进行数据标注,而且最关键的问题在于:训练得到的模型还是不懂人类的语言。

所以,我们是不是该从语言最初的形态开始重新研究:人类到底是怎么获得语言能力的?
最近来自康奈尔大学、麻省理工学院和麦吉尔大学的研究人员在Nature Communications上发表了一篇论文,提出一个算法合成模型的框架,在人类语言的最基础部分,即词法音位学(morpho-phonology)上开始教AI学习语言,直接从声音中构建语言的词法。

论文链接:https://www.nature.com/articles/s41467-022-32012-w
词法音位学是语言学分支之一,主要关注语素(即最小的意义单位)在组合成词时发生的音变,试图给出一系列规则,以预判语言中音素的规律变声。
比如说英语中的复数语素写作-s或是-es,但读音却有三种[s]、[z] 及 [әz],比如cats的发音为/kæts/, dogs的发音为/dagz/, horses的发音为/hɔrsәz/。
人类在学习复数发音转换时,首先根据词法学(morphology),意识到复数后缀实际上是/z/;然后根据音位学(phonlogy),将后缀基于词干中的声韵,如清辅音等转换成/s/或/әz/

其他语言也有同样的音位词法规律,研究人员从58种语言的音位教科书上收集得到了70个数据集,每个数据集只包含几十到几百个单词,并且只包含少数语法现象,实验表明在自然语言中寻找语法结构的方法也可以模拟婴儿学习语言的过程。
通过对这些语言数据集执行分层贝叶斯推理(hierarchical Bayesian inference),研究人员发现该模型仅从一个或几个样例中就可以获取新的词法音位规则,并且能够提取出通用的跨语言模式,并以紧凑的、人类可理解的形式表达出来。
让AI模型做「语言学家」
让AI模型做「语言学家」
人类的智能主要体现在建立认知世界理论的能力,比如自然语言形成后,语言学家总结了一套规则来帮助儿童更快速地学习特定语言,而当下的AI模型却无法总结规则,形成一套其他人可理解的理论框架。
在建立模型之前要解决一个核心问题:「如何描述一个词」,比如说一个词的学习过程包括了解词的概念、意图、用法、发音以及含义等。
在构建词表时,研究人员把每个词表示为一个<音标,语义集合>对,例如open表示为</opεn/, [stem: OPEN]>, 过去式表示为</d/, [tense: PAST]>,组合得到的opened表示为</opεnd/, [stem: OPEN, [tense: PAST]]>

有了数据集以后,研究人员建立了一个模型,通过最大后验概率推理来解释在一组pair集合上生成语法规则,对词的变化进行解释。
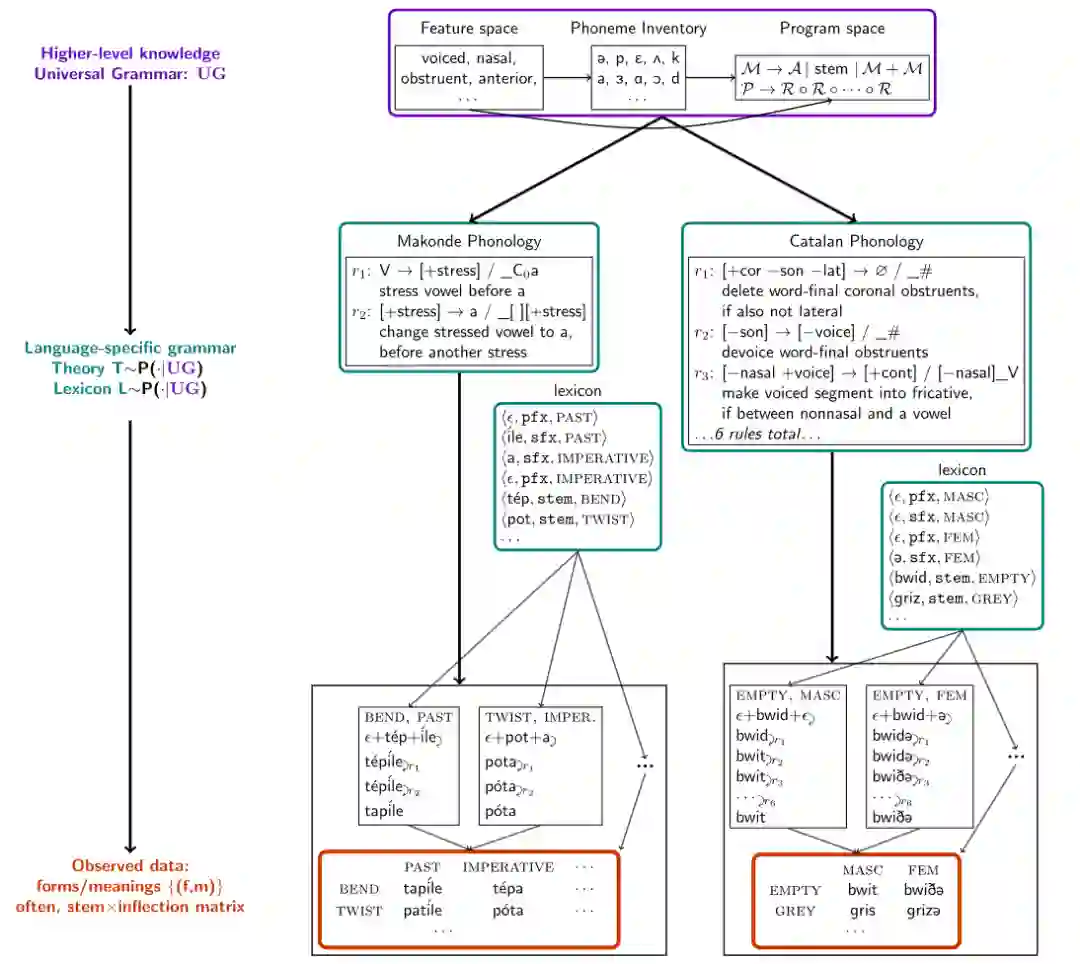
在声音的表示上,音素(原子音)被表示为二元特征的向量,比如/m/,/n/,是鼻音,然后基于该特征空间定义语音规则。
研究人员采用经典的规则表述方式,即情境相关记忆(context-dependent),有时也称之为SPE-style规则,其广泛应用于英语的音型(Sound Pattern of English)表示。
每个规则的写法是
(focus)→(structural_change)/(left_trigger)_(right_trigger),意思是只要左/右触发环境紧靠focus的左/右,焦点音素就会根据结构变化进行转换。

触发环境指定了特征的连接(表征音素的集合),例如在英语中,只要左边的音素是[-sonorant],在词末的发音就会从/d/变成/t/,写成规则就是[-sonorant] → [-voice]/[-voice -sonorant]_#,比如说walked应用这一规则后,发音就从/wɔkd/转化为/wɔkt/。
当这种规则被限制为不能循环应用于自己的输出时,规则和词法学就对应于双向有理函数(2-way rational functions),又对应于有穷状态转换器(finite-state transductions)。有人认为有穷状态转换器的空间有足够的表现力来涵盖形态语音学中已知的经验现象,并代表了对语音学理论实际使用的描述能力的限制。
为了学习这种语法,研究人员采用了贝叶斯程序学习(Bayesian Program Learning, BPL)的方法。将每个语法规则T建模为一种编程语言中的程序,这种语言捕捉了问题空间的特定领域的约束。所有语言共同的语言结构被称为通用语法(universal grammar)。该方法可以被看作是语言学中一个长期存在的方法的现代实例,并采用人类可理解的生成性代表来正式确定通用语法。

在定义好BPL需要解决的问题后,在所有程序的搜索空间都是无穷大,不给出如何解决这个问题的任何指导方向,且缺乏像梯度下降或马尔科夫链蒙特卡洛这样局部优化算法所利用的局部平稳性的情况下,研究人员采用了一种基于约束的程序合成的策略,将优化问题转化为组合约束满足问题,并使用布尔可满足性(SAT)求解器来解决。
这些求解器实现了详尽但相对有效地搜索,并保证在有足够时间的情况下,会找到一个最优解。使用Sketch程序合成器可以解决与某些数据一致的最小的语法,但必须符合语法大小的上限。
但在实践中,SAT求解器所采用的穷举搜索技术无法扩展到解释大型语料库所需的海量规则。
为了将求解器扩展到大型和复杂的理论,研究人员从儿童获得语言能力和科学家建立理论的一个基本特征中得到了启发。
儿童并不是一蹴而就地学习语言,而是通过语言发展的中间阶段,逐步丰富他们对语法和词汇的掌握。同样地,一个复杂的科学理论可能从一个简单的概念内核开始,然后逐渐发展到涵盖越来越多的语言现象。
基于上述想法,研究人员又设计了一种程序合成算法,从一个小程序开始,然后反复使用SAT求解器来寻找小的修改点,使其能够解释越来越多的数据。具体来说,就是找到一个对当前理论的反例,然后使用求解器详尽地探索可以容纳这个反例的理论的所有小修改的空间。
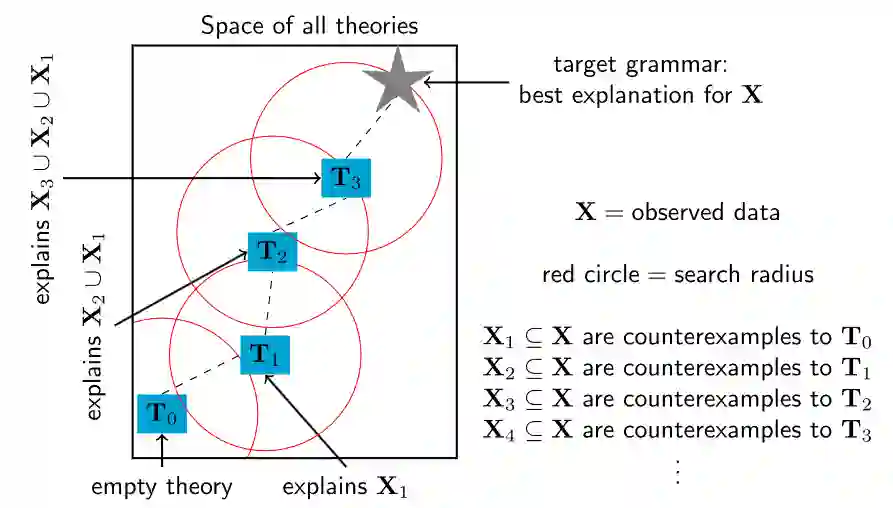
但这种启发式的方法缺乏SAT求解的完整性保证:尽管重复调用一个完整的、精确的SAT求解器,但它并不能保证找到一个最优解,不过每一次重复调用都比直接对整个数据进行优化要难得多。因为约束每个新的理论在理论空间中接近其前一个理论会导致约束满足问题的多项式缩小,从而使搜索时间呈指数级增长,而SAT求解器在最坏的情况下是以指数级增长的。
在实验评估阶段,研究人员从语言学教科书中搜集了70个问题,每个问题都要求对一些自然语言中的一些形式的理论进行综合分析。这些问题的难度范围很广,涵盖了多种多样的自然语言现象。
自然语言也多种多样,包括音调语言,例如,在Kerewe语(坦桑尼亚的一种班图语)中,to count是/kubala/,但to count it是/kukíbála/,其中重音标记高音调。
也有元音和谐(vowel harmony)的语言,例如土耳其有/el/,/t∫an/,分别表示手,钟,以及/el-ler/,/t∫an-lar/,分别表示手和钟的复数;还有许多其他语言现象,如同化和外延式。
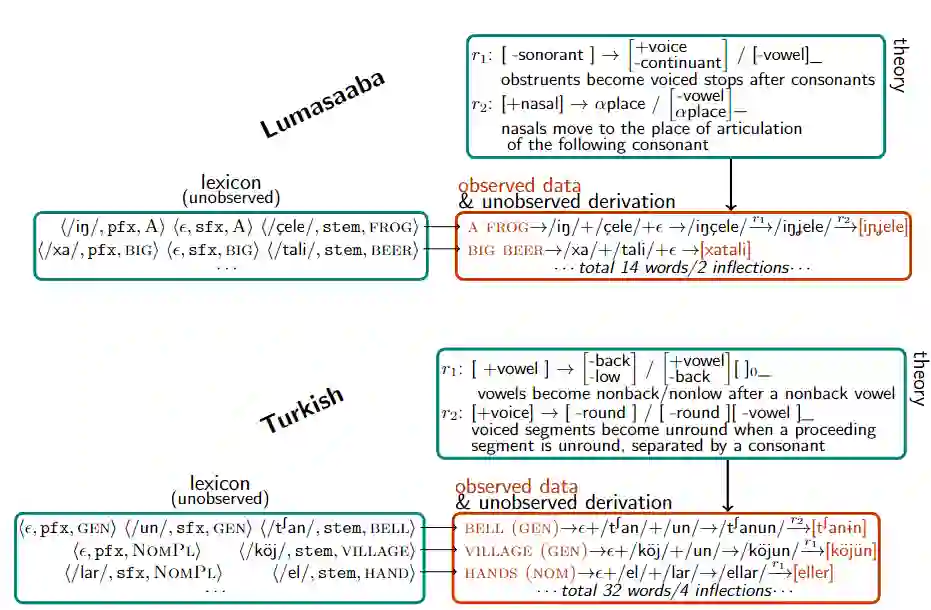
在评估上,首先衡量该模型发现正确的词表的能力。与ground-truth词表相比,该模型在60%的基准中发现了与问题的全部词库正确匹配的语法,并在79%的问题中正确解释了大部分的词库。
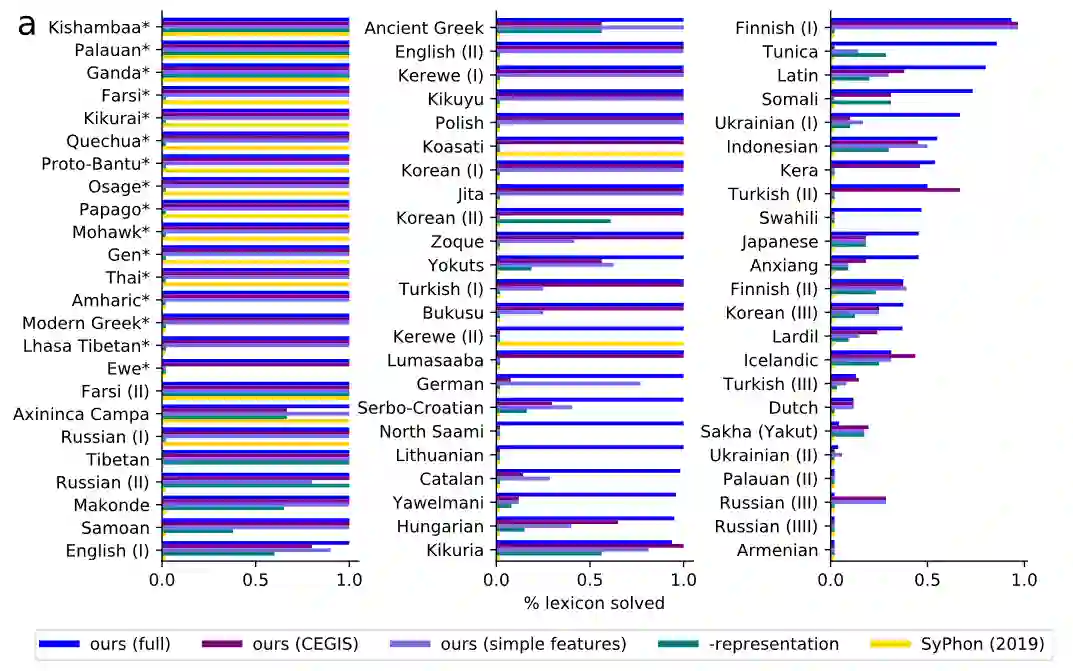
通常情况下,每个问题的正确词库比正确的规则更明确,任何从正确的词库中产生完整数据的规则必须与模型可能提出的任何基础规则具有观察上的等效性。因此,与基础真理词库的一致性应该作为一个指标来衡量同步化的规则在数据上是否有正确的行为,该评估与规则的质量相关。
为了测试这个假设,研究人员随机抽取了15个问题,并与一位专业语言学家协商,对发现的规则进行评分。同时测量召回率(正确恢复的实际语音规则的比例)和精确度(恢复的规则中实际出现的比例)。在精度和召回率的指标下,可以发现规则的准确性与词库的准确性呈正相关。
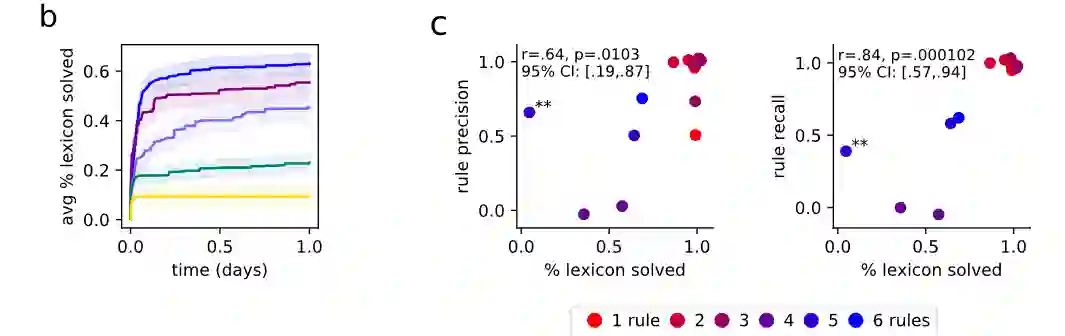
当系统得到所有词库的正确性时,它很少引入无关的规则(高精度),而且几乎总是得到所有正确的规则(高召回率)。



