
UniLMv2:统一预训练伪掩码语言模型
UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
论文链接:https://www.zhuanzhi.ai/paper/a6628400809ab320e597b1d4d1fca177
基于大规模语料的预训练语言模型在各种自然语言处理任务带来了巨大的提升。受UniLMv1 ([NeurIPS-19]Unified Language Model Pre-training for Natural Language Understanding and Generation)的启发,本篇论文提出“伪掩码语言模型”(PMLM),可以同时对两种不同的语言建模目标进行高效训练,从而使其更好地适用于语言理解(如文本分类、自动问答)和语言生成(如文本摘要、问题生成)任务。
我们将语言模型预训练目标分为三类。第一类依赖于自编码语言建模(Autoencoding, AE)。例如在 BERT 中使用的掩码语言建模(MLM)随机的在文本序列中遮盖一部分单词,在 Transformer 的双向编码结果之上,对每个被遮盖的单词进行分别还原。第二类方法基于自回归建模(Autoregressive, AR)。不同于 AE,目标单词被依次预测,且依赖于先前的结果。第三类是我们提出的半自回归语言建模(Partially Autoregressive, PAR),对短语级别进行依赖建模,从而避免了 AR可能带来的过度局部依赖问题。
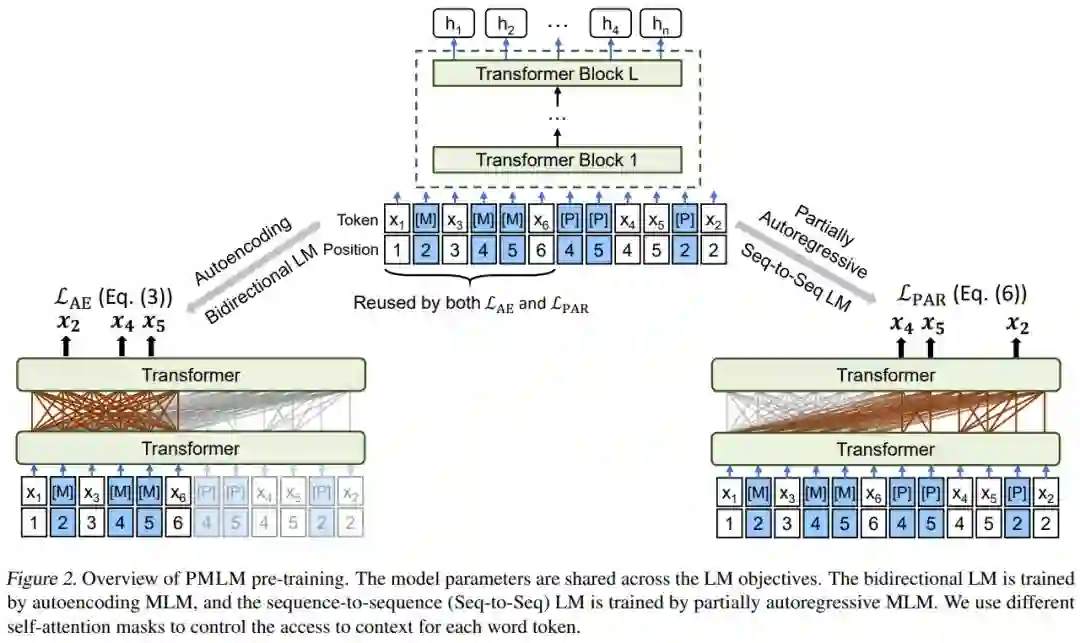
伪掩码语言模型(PMLM)
在新提出的伪掩码语言模型(PMLM)中,我们对 AE 以及 PAR 这两个语言建模目标进行了融合。在共享模型参数的基础上,尽可能对上下文的编码结果进行了复用,以达到高效训练的目的。通过构造合理的自注意力模型掩码与位置编码,PMLM 可以在一次计算中同时对两种语言建模任务进行训练,且无需进行上下文编码的冗余计算。
在自动问答、复述判别、情感分类、文本摘要、问题生成等一系列任务上的测评,说明了这一方法的有效性。
