
题目
知识增强的常识性故事生成预训练模型,A Knowledge-Enhanced Pretraining Model for Commonsense Story Generation
关键字
知识增强,故事生成,预训练,机器学习,神经网络,语言模型
简介
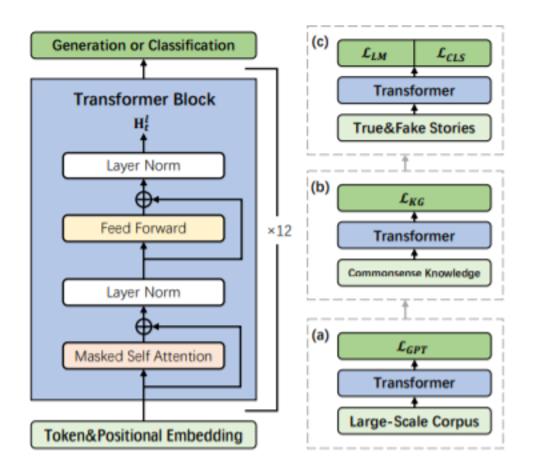
故事生成,即从主导语境中生成真实的故事,是一项重要而富有挑战性的任务。尽管成功建模流畅性和本地化,现有的神经语言生成模型(例如,GPT-2)仍然遭受重复,逻辑冲突,缺乏长期连贯性在生成的故事。我们推测,这是由于关联相关常识知识、理解因果关系、规划实体和事件具有适当的时间顺序等方面的困难,本文设计了一个常识故事生成的知识增强预训练模型,并提出了利用常识知识的方法来自外部知识库的知识,以生成合理的故事。为了进一步捕捉可推理故事中句子之间的因果关系和时间依赖关系,我们采用了多任务学习法,在微调过程中结合辨别目标来区分真假故事。自动和手动评估表明,我们的模型可以生成比艺术基线状态更合理的故事,特别是在逻辑和全局一致性方面。
作者
Jian Guan, Fei Huang, Xiaoyan Zhu, Minlie Huang,来自人工智能研究所,智能技术与系统国家重点实验室;北京国家信息科学技术研究中心;清华大学计算机科学与技术系。 Zhihao Zhao,来自北京航空航天大学软件学院。
成为VIP会员查看完整内容
相关内容

专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
37+阅读 · 2020年4月10日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
26+阅读 · 2019年12月5日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
专知会员服务
95+阅读 · 2019年11月8日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
3+阅读 · 2018年1月2日




相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
37+阅读 · 2020年4月10日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
26+阅读 · 2019年12月5日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
专知会员服务
95+阅读 · 2019年11月8日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
3+阅读 · 2018年1月2日