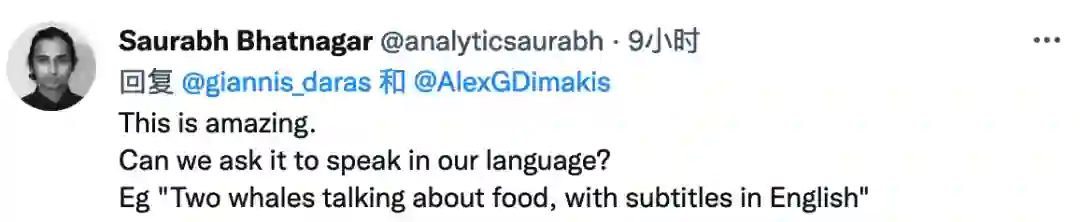以下文章来源于AI科技评论,作者为李梅,刘冰一。
![]()
万一DALL·E-2是在向人类发出什么了不得的信号呢?这门语言快学起来!
编辑|陈彩娴
DALL·E 和 DALL·E-2从文本生成图像的魔力,想必大家都已经见识过了。作为深度生成模型,它们能够将文本作为输入,生成匹配给定文本的超逼真图像。
不过,DALL·E-2 的一个众所周知的局限性是它在生成
带文本的图像
时很吃力。
例如,给出文本提示:Two farmers talking about vegetables,with subtitles.(两个农民在谈论蔬菜,有字幕)
谁能告诉我这张图上的文字是什么语言?什么意思???
在DALL·E-2所生成的带有文本的图像中,DALL·E-2显然在说一种我们人类看不懂的语言。其实这一点在最初的DALL·E-2论文以及Marcus等人对该模型的初步评估中就已经发现了。
而最近有人发现,
这些让人无法理解的文本并不是随机的!
来自德克萨斯大学奥斯汀分校的博士生Giannis Daras 和 Alexandros G. Dimakis教授,发现DALLE-2背后竟然有一套秘密语言,模型内部似乎有一套隐藏的词汇表,从这些隐藏的词汇中,模型会学习一些单词,并创造一些荒谬的文本提示来生成图像。
比如,在DALL·E-2的语言系统里,Apoploe vesrreaitais意思是鸟类,Contarra ccetnxniams luryca tanniounons则表示昆虫或害虫。
当你输入这个句子作为文本提示时:Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons
DALL·E-2生成了下面这些图像,图像内容翻译成英语,显然是“A bird is eating a bug”(一只鸟在吃虫子)
Daras 和 Dimakis 采用了一种简单的方法来破解DALL·E-2的词汇库。
比如,假设我们想找到在DALL·E-2的语言系统中,“ vegetables(蔬菜)”这个英语单词对应的词是什么,就可以用下面这些句子来提示DALL·E-2:
-
A book that has the word vegetables written on it.(上面写着“蔬菜”一词的书。)
-
Two people talking about vegetables, with subtitles.(两个人在谈论蔬菜,有字幕。)
-
The word vegetables written in 10 languages.(以10种语言书写的“蔬菜”一词。)
然后,DALL·E-2就会生成带有表示“蔬菜”义的文本的图像,比如在上面那张“两个农民在谈论蔬菜”的图片中,DALL·E-2给出了自己的翻译文本:Avcopinitegoos Vicootes, Apoploe vesrreaitais。
下一步,我们就可以输入DALL·E-2自己的词汇,来看它会生成什么图像。比如下图(左)是从单词“vicootes” 生成的图像,下图(右)是从短语 “apoploe vesrreaitais” 生成的图像:
懂了懂了,所以“vicotes”的意思是“蔬菜”,“apoploe vesrreaitais”的意思是”鸟类”~ 只是这些鸟看起来倔强而自由,仿佛正盯着对农民的蔬菜准备搞破坏。
DALL·E-2:所以这张图什么意思,不用我说了吧。
好玩真好玩,我已经迫不及待想要学会DALL·E-2的这门语言了!
再看一个例子。输入文本“Two whales talking about food, with subtitles”(两只鲸鱼在谈论食物,有字幕),DALL·E-2 给出了如下的图片回执(左)~ 上面写着 “Wa ch zod ahaakes rea.”
谁看的懂??可能人类不懂就对了——我猜这两头鲸鱼正在用DALLE-2 的语言谈论它们的食物。紧接着,把这句话作为输入,DALL·E-2生成的图像(右)是......一堆海鲜美食!
这真是不可思议。我们能要求它用我们的语言说话吗?例如 “两只鲸鱼在谈论食物,有英文字幕”。
伟大的工作!这些输出让我想起了我一直在训练的GANs,它们产生了以前没有听说过的新词。有些是英语单词,有些可能是但不是。它们会赋予这些新词有意义的表述。
我要吹毛求疵一下。如果农民谈论的是 “Apoploe vesrreaitais”,而 “Apoploe vesrreaitais的3D效果图 ”,或 “线条艺术,Apoploe vesrreaitais ”可以指昆虫(或如他们所说的更普遍的 “会飞的东西”),那我认为农民更可能是在说昆虫而不是鸟。
我不太相信我们在“farmers with subtitles”的图片中看到的文字和推断的单词含义之间有很强的相关性。我们不知道这个农民的例子是如何“偷梁换柱”的,而且它甚至不起作用:如果这个假设是真的,“Apoploe vesrreaitais ”就对应“蔬菜”,但它对应的却是“鸟”。而且由于某种原因,我们看到的是 “vicootes ”的输出,而不是 “vicootess”。这看起来很似是而非。
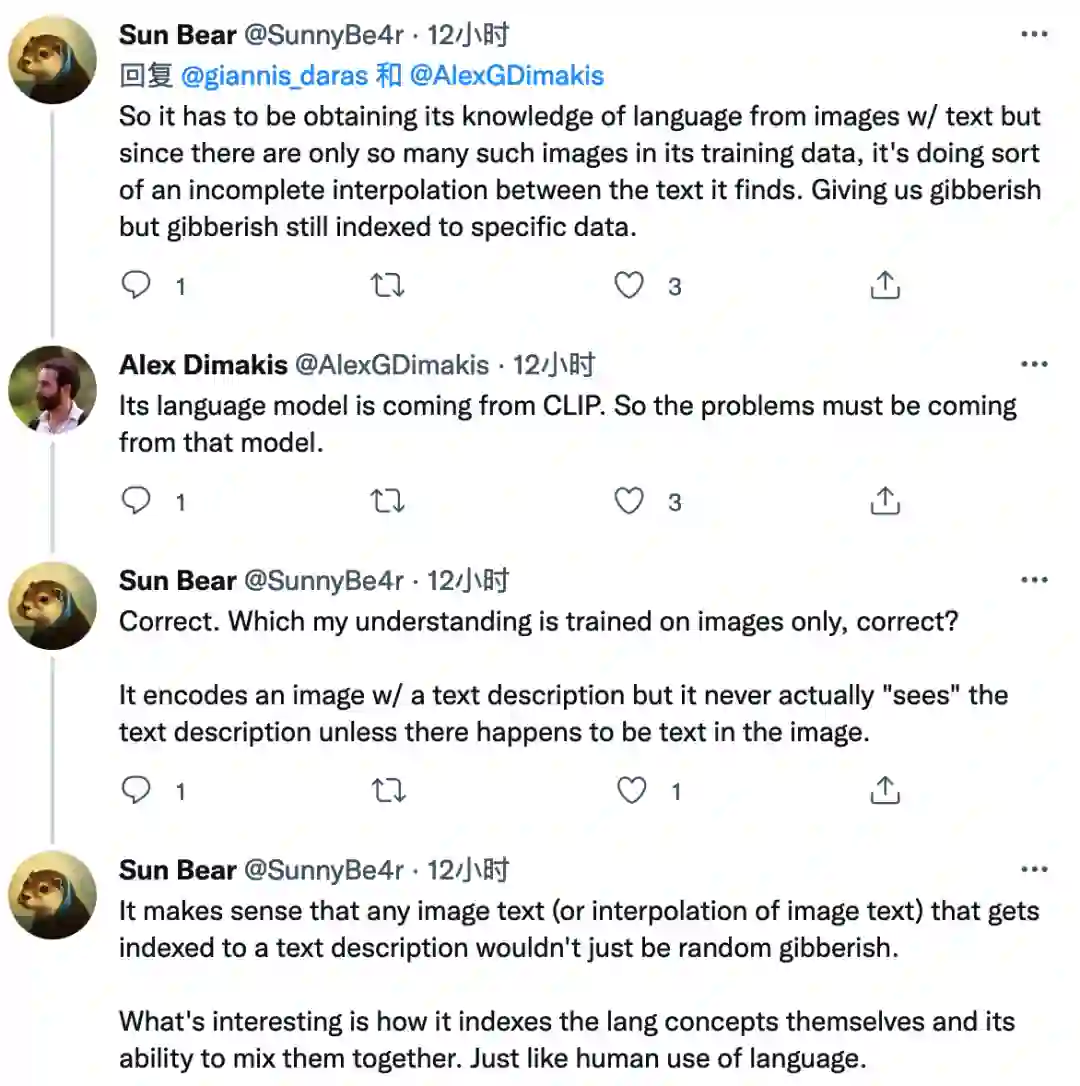
令人难以置信的结果!我猜想,由于CLIP从未在纯语言任务上接受过训练,它从未被激励“不”去将胡言乱语与概念联系起来(不像Imagen中使用的常规语言模型)。
-所以它必须从带有文字的图像中获得语言知识,但由于其训练数据中只有这么多这样的图像,它在找到的文字之间做了某种不完整的插值。虽然给我们的是胡言乱语,但胡言乱语仍然是以特定数据为索引的。
-它的语言模型是来自CLIP,所以问题一定是来自那个模型。
-我的理解是,它只在图像上进行训练,对吧?它用文本描述对图像进行编码,但它实际上从未 “看到 ”文本描述,除非图像中恰好有文本。
-任何被索引到文本描述的图像文本(或图像文本的插值)都不会只是随机的胡言乱语,这很有道理。有趣的是它如何对语言概念本身进行索引,以及它将它们混合在一起的能力。就像人类对语言的使用一样。
两位作者对DALL·E-2的词汇库做了进一步的研究。
先来瞅瞅它的 Compositionality(组合性)。
从前面的例子中,我们知道 "Apoploe vesrreaitais" 指“鸟类”。通过重复有关农民的提示的实验,我们还可推测 “Contarra ccetnxniams luryca tanniounons”表示“害虫或虫子”。
那么一个有趣的问题就来了,DALL·E-2能否把这两个概念组成一个句子呢?
如下图所示 ,DALL·E-2可以将词和短语组合成句子,根据 "Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons" 生成了鸟类在吃虫子的图像。不过这种情况不是发生在所有的生成图像中,所以一致性并不是十分稳健。
DALL·E-2 能够根据提示中指定的风格,生成一些相关概念的图像。
例如,预设我们想得到一个苹果的逼真图像,或苹果的线条艺术。要先测试单词(如Apoploe vesrreaitais)是否对应于视觉概念,这些概念能否根据提示的上下文转化为不同的风格。
DALL·E-2 生成的不同风格的 “Apoploe vesrreaitais”,形态虽异,但“会飞的东西 ”这一视觉概念得到了保持。
结果,既发现有蔬菜、也发现有鸟的存在。两个农民谈论鸟类是非常合理的,这就提出了一个非常有趣的问题:DALL·E-2 的文本输出是否与文本条件和生成的图像一致?
实验表明,
有时我们得到的胡言乱语的文本翻译成视觉概念,与首先产生胡言乱语文本的标题一致。
有点绕口,简单一点,就是种瓜得瓜种豆得豆,管它是印象派还是写实派,结出的瓜和豆和最初的瓜豆种子(废话文学快住嘴),能看的出还是有联系的。
例如,"Two whales talking about food, with subtitles"(两只鲸鱼在谈论食物,有字幕)产生了一个带有文字 "Wa ch zod ahaakes rea" 的图像。把这段文字作为提示输入模型,在生成的图像中看到了海鲜。
结合上图“不同风格的鸟”看来,胡言乱语的文本确实有其含义,有时与产生它的文本条件相一致。
在鲸鱼图中,生成图像中不明所以的文字 "Wa ch zod ahaakes rea",与产生的图像、标题和第一幅图像的视觉输出是相关的。
有一种可能是,这些非人类现有语言的单词是不同语言中正常单词的拼写错误,但两位作者在搜索中没有发现任何这样的例子,所以这些词的来源仍然令人困惑。而且在他们的初步实验中,有些词并不像其他词那样具有一致性,也就是说,
目前DALL·E-2 的这套语言在从文本生成图像时的稳健性可能不足。
初步研究表明,像“Contarra ccetnxni ams lurycat anni ounons”这样的提示有时会产生包含虫子和害虫的图像(约占生成图像的一半),每次还会产生不同的图像,大部分是动物。而“Apoploe vesrreaitais”这个短语的一致性明显更强,可以以各种方式组合来生成具有一致性的图像。
如果要测试更多提示语的稳健性,则需要大量的实验。论文作者表示,如果一个系统表现出疯狂的不可预测性,即使这种情况很少发生,也仍然是一个重要的问题,特别是对于一些应用程序而言。
另一个有趣的问题是,
Imagen是用语言模型训练的,而不是CLIP,它是否也会有一个类似的隐藏词汇库呢?
无论如何,生成图像的荒谬提示挑战了我们对这些大型生成模型的信心。显然,在理解这些现象和创建稳健的、与人类预期相一致的语言和图像生成模型方面还需要更多的基础研究。
论文地址:https://giannisdaras.github.io/publications/Discovering_the_Secret_Language_of_Dalle.pdf
参考链接:
https://twitter.com/giannis_daras/status/1531693111755149312
https://www.reddit.com/r/MachineLearning/comments/v1zzh8/d_dalle_2_has_its_own_secret_language/
![]()
![]()
![]()
举一反三:示例增强的(example augmented)自然语言处理
![]()