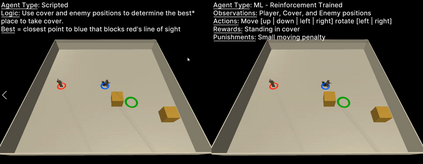
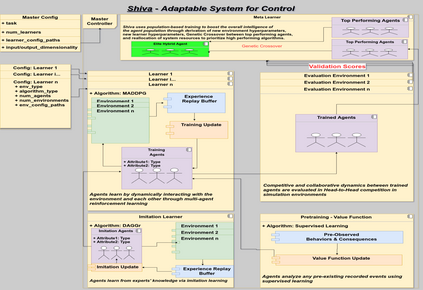
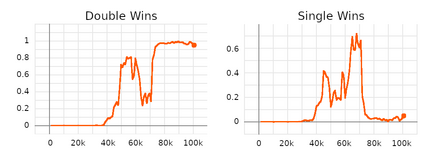
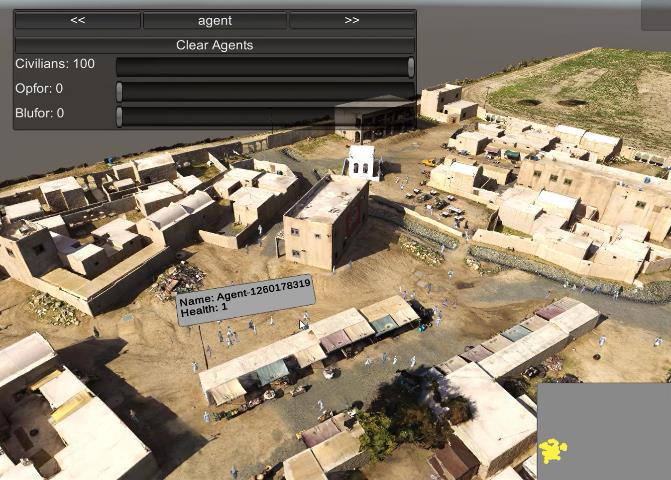
Behaviors of the synthetic characters in current military simulations are limited since they are generally generated by rule-based and reactive computational models with minimal intelligence. Such computational models cannot adapt to reflect the experience of the characters, resulting in brittle intelligence for even the most effective behavior models devised via costly and labor-intensive processes. Observation-based behavior model adaptation that leverages machine learning and the experience of synthetic entities in combination with appropriate prior knowledge can address the issues in the existing computational behavior models to create a better training experience in military training simulations. In this paper, we introduce a framework that aims to create autonomous synthetic characters that can perform coherent sequences of believable behavior while being aware of human trainees and their needs within a training simulation. This framework brings together three mutually complementary components. The first component is a Unity-based simulation environment - Rapid Integration and Development Environment (RIDE) - supporting One World Terrain (OWT) models and capable of running and supporting machine learning experiments. The second is Shiva, a novel multi-agent reinforcement and imitation learning framework that can interface with a variety of simulation environments, and that can additionally utilize a variety of learning algorithms. The final component is the Sigma Cognitive Architecture that will augment the behavior models with symbolic and probabilistic reasoning capabilities. We have successfully created proof-of-concept behavior models leveraging this framework on realistic terrain as an essential step towards bringing machine learning into military simulations.
翻译:合成字符在目前军事模拟中的表现是有限的,因为合成字符在目前军事模拟中的作用是有限的,因为它们通常是由基于规则的和被动的计算模型产生的,而且情报很少。这种计算模型无法适应以反映这些字符的经验,导致甚至对通过成本昂贵和劳力密集的过程所设计的最有效行为模型缺乏情报。基于观察的行为模型的适应,利用机器学习和合成实体的经验,结合适当的事先知识,可以解决现有计算行为模型中的问题,从而在军事培训模拟中创造更好的培训经验。在本文中,我们引入一个框架,目的是创建自主合成字符,能够进行连贯的系列可信赖的行为,同时在培训模拟中了解人类受训人员及其需要。这个框架汇集了三个相辅相成的组成部分。第一个组成部分是基于团结的模拟环境——快速整合和开发环境(REID)——支持一个世界地面(OWTT)模型,能够运行和支持机器学习实验。第二个步骤是Shiva,一个新的多剂强化和模仿学习框架,可以与各种模拟环境相交接,并且能够进一步利用模拟模型的模拟模型,并且可以进一步利用一种象征性的模拟行为演化模型。