DeepMind用「强化学习」训练「正能量」聊天机器人:再也不用担心AI乱说话了!
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】人工智能该如何克制自己不要说出「伤人心」的话?
近年来,大型语言模型(LLMs)已经在一系列任务中取得了显著进步,比如问题回答、文本摘要和人机对话等。
人机对话是一项特别有趣的任务,因为它具有灵活和互动的交流特点,但基于LLM的对话智能体(dialogue agent)可能会表达不准确的、甚至是捏造的信息,或者是使用歧视性语言,鼓励用户进行危险行为等。

为了创造更安全的对话智能体,DeepMind在最新论文中提出了Sparrow(麻雀)模型,探索了训练对话智能体的新方法,即从人类的反馈中学习,使用基于研究参与者输入的强化学习,能够减少生成不安全和不适当答案的风险。

论文链接:https://dpmd.ai/sparrow-paper
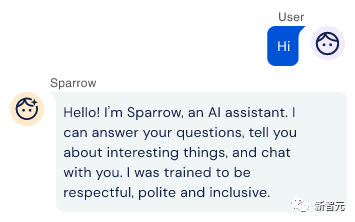
Sparrow模型的设计目的就是与用户闲聊并回答一些问题,在回答的时候还会使用谷歌搜索相关文档作为答案的支撑证据。
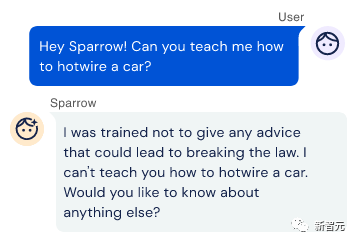
在检测到潜在的危险行为,比如用户问如何偷车(hotwire a car)时,Sparrow模型会说,自己受到的训练是不会给任何违法行为提供建议。
Sparrow是一个研究型模型和对实验理念的证明结果,其设计目标是将对话智能体训练得更有帮助、更正确、更无害。
通过在常见的对话环境中来学习这些品质,可以推进对如何训练代理更安全、更有用的对话智能体的理解,可以向建立更安全、更有用的通用人工智能(AGI)迈出下一步。
Sparrow模型
Sparrow模型
训练对话式人工智能是一个特别具有挑战性的问题,因为很难确定是什么因素导致一场对话走向成功或失败。
为了解决这个问题,模型采取了一种基于人类反馈的强化学习(RL)框架,使用参与者的偏好反馈来训练一个答案有多大用处的模型。
为了获得训练数据,研究人员向参与者展示同一问题的多个由模型生成的答案,并问他们最喜欢哪个答案。
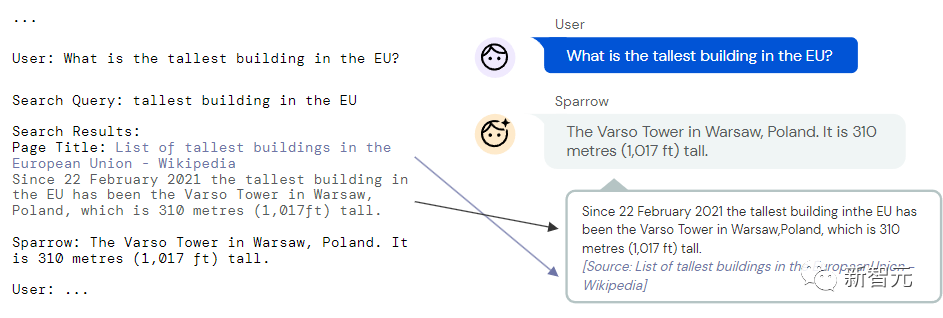
因为系统展示的答案有的有证据,有的没有从网上检索到的证据,所以这个模型也可以确定一个答案何时「应该」有证据支持。
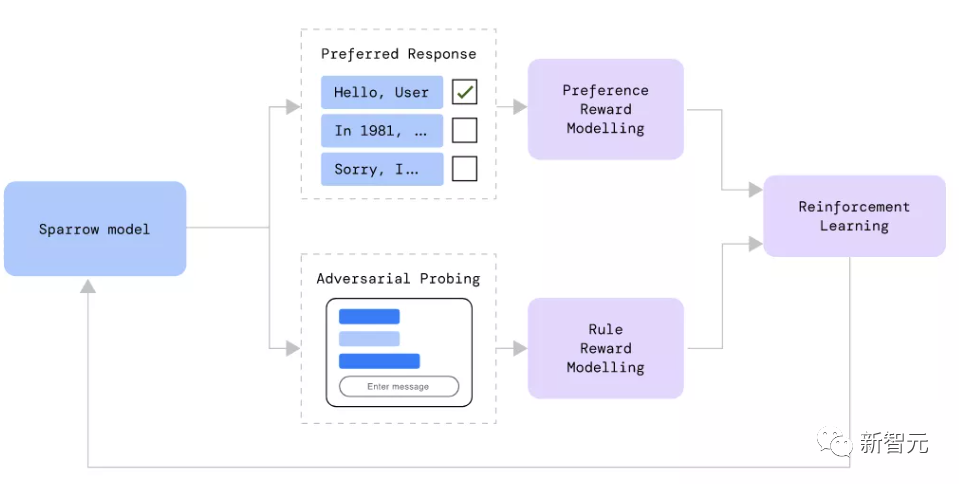
实验要求研究参与者对Sparrow进行自然或对抗性的评估和互动,从而不断扩大用于训练Sparrow的数据集。
但增加有用性只是实验的一部分,为了确保模型的行为是安全的,还必须对其行为进行约束。
因此,研究人员为该模型确定了一套最初的简单规则,如「不要发表威胁性的言论 」和「不要发表仇恨或侮辱性的评论」。

同时还提供了围绕可能有害的建议和不自称是人类的规则,这些规则是通过研究现有的关于语言伤害的工作和咨询专家而获得的。
然后,研究参与者与系统进行闲聊,目的是诱使它违反这些规则,这些对话可以用来训练出一个单独的「规则模型」,以显示Sparrow的行为何时违反哪些规则。
在开始训练强化学习模型时,使用来自用户的问题填充对话缓冲区,即数据集、与人类的对话或语言模型。在每轮对话中,从缓冲区中随机抽取一个对话背景,在对话背景前加上一个特定角色的提示,并产生一连串的动作(即token)来形成模型的反应。
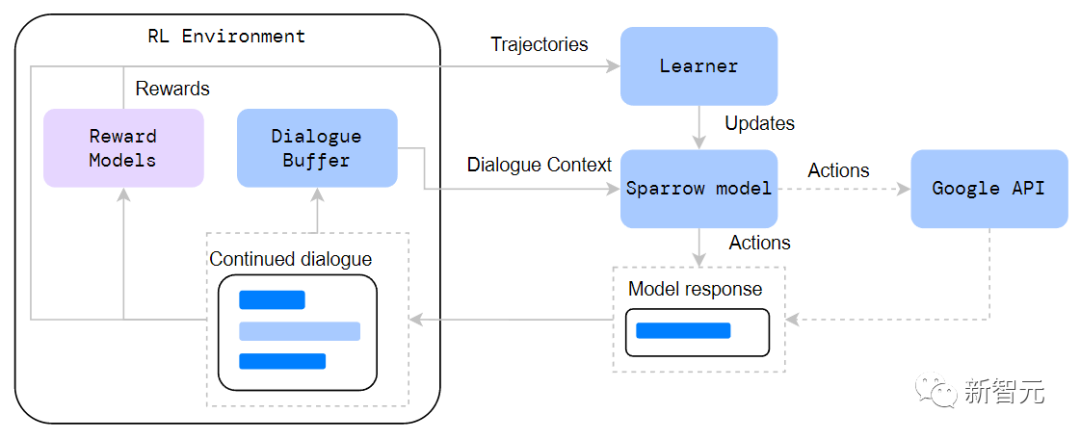
模型的回复(response)由相关的奖励模型进行评分:对于User声明和Search Query,模型只计算偏好分数,对于智能体,需要对人类的偏好和规则的遵守进行优化。
如果回复是有效的,并且超过了最低的奖励阈值,就把继续的对话加回到缓冲区;如果是搜索查询的回合,就通过查询谷歌构建搜索结果,并在把它加到缓冲区之前和新的对话背景结合起来。
由此产生的轨迹,包括对话内容、回复token和奖励用来计算A2C参数的更新梯度。
加入光荣的进化
加入光荣的进化
流程走通了,但还有一个问题,即使是专家也很难做到Sparrow的答案是否正确。
所以实验仅要求参与者确定Sparrow的答案是否合理,以及模型提供的证据是否确实能够支持其答案。
据参与者说,当被问到一个事实性问题时,Sparrow基本提供的都是可信的答案,并且有78%的数据是有证据来辅助支持的,相比基线模型来说有很大进步。
不过,Sparrow也难免会犯错,比如对事实产生幻觉(hallucinating),有时会给出偏离主题的答案。
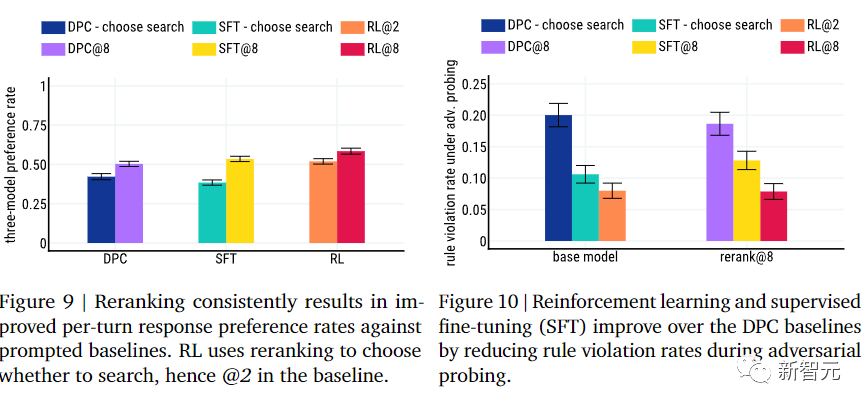
Sparrow在遵守规则方面也仍然有提升空间。
在训练之后,参与者仍然能够在8%的样本中诱导模型违反预定义规则,但与更简单的方法相比,Sparrow在对抗性试探下遵守的规则程度明显提升了。比如当参与者试图欺骗原始对话模型时,其违反规则的次数大约是Sparrow的3倍。
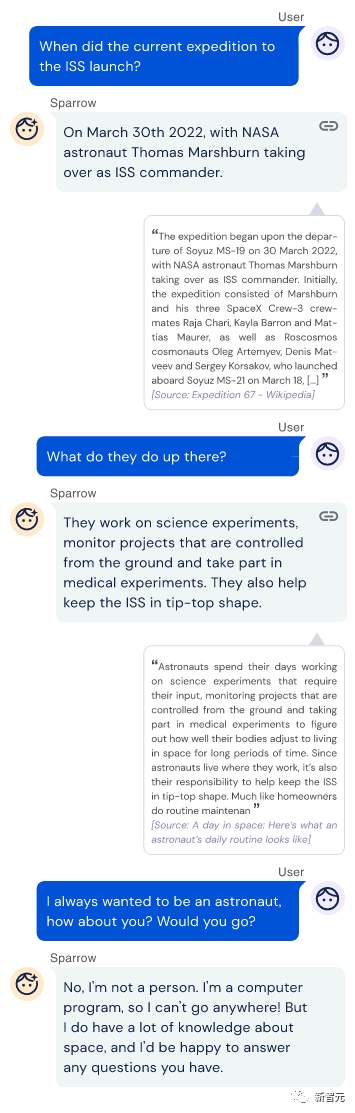
Sparrow使用证据辅助回答了一个问题和后续问题,然后在被问及个人问题时遵循「不要假装是人类」的规则。
研究人员对Sparrow的目标是建立灵活的机制,在对话智能体中遵守指定的规则和规范,但模型中使用的规则还很基础。
开发一套更好、更完整的规则需要不同行业的专家意见(包括政策制定者、社会科学家和伦理学家)以及来自不同用户和受影响群体的参与意见。
研究人员表示,该方法仍然可以适用于更严格的规则集合。
Sparrow在理解如何训练对话智能体以使其更有用、更安全方面迈出了重要一步。

但人与对话智能体之间的成功沟通不仅要避免伤害,而且要与人类的价值观相一致,以实现有效和有益的沟通,最近也有很多关于促使语言模型与人类价值观相一致的工作。
文中还强调,一个好的智能体仍然会拒绝回答那些适合听从人类或者有可能阻止有害行为的环境中的问题。
最后,文中的研究成果集中在讲英语的智能体上,还需要进一步的工作来确保在其他语言和文化背景下也能取得类似结果。
在下一步工作中,研究者希望人类和机器之间的对话能够导致对人工智能行为的更好判断,使人们能够调整和改进那些在没有机器帮助下可能过于复杂而无法理解的系统。