【泡泡图灵智库】GeoDesc:整合几何约束的局部特征子学习方法(ECCV)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:GeoDesc: Learning Local Descriptors by Integrating Geometry Constraints
作者:Zixin Luo, Tianwei Shen, Lei Zhou, Siyu Zhu, Runze Zhang, Yao Yao, Tian Fang, Long Quan
来源:ECCV2018
编译:李永飞
审核:尹双双
提取码:7ciu
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——GeoDesc:整合几何约束的局部特征子学习方法,该文章发表于ECCV2018。
基于CNN的局部描述子学习,尽管在基于像素块的数据集上获得了很好的效果,却在最近提出的基于图像的三维重建数据集上没有体现出良好的泛化性能。为克服这一不足,本文提出了一种新的局部描述子学习算法。该算法整合了多视图重构中的几何约束关系,因而在数据生成、数据采样、和损失函数的计算等方面促进局部描述子的学习过程。本文将该描述子称为GeoDesc,并展示了其在不同大规模数据集上的优良性能,特别是其在具有挑战的重构任务中的成功应用。进一步,本文将该描述子整合到SFM中,展现了该描述子在三维重构任务中对于精度和效率的良好的平衡。
主要贡献
本文提出了一种融合了几何约束的局部描述子学习方法,其重要贡献为:
1、提出了一种新的训练数据批量构建方法,该方法能够模拟特征点匹配过程,进而能够生成很好的训练样本;
2、提出了一种新的损失函数以减少过拟合,同时改善几何约束性能;
3、提出了学习的描述子在实际应用中的比率准则、紧凑性和可扩展性准则。
算法流程
PS:本文主要的工作是提出了一种局部特征点的描述子计算方法。与以往方法的不同之处在于,本文考虑了特征点的几何约束信息,该信息是由生成训练数据时,使用的SFM算法提供的。本文的几何约束主要体现在两个方面:一是、训练数据的构建过程中,通过使用几何信息,计算局部像素块的相似度,以及图片整体的相似度,从而来衡量样本的“硬度”。这里的“硬”指的是“同一三维点对应的不同像素块差异尽可能大,不同三维点对应的像素块差异尽可能小”。这样的“硬样本”往往包含更多的有用信息,更加难以训练,因而能够得到更好的泛化性能。二是、通过面片的相似度,构建了几何相似度损失函数,从而能够鼓励同一三维点对应的不同像素块尽可能接近。下面对该算法进行具体的描述:
1、 网络结构
采用和L2-Net相似的网络结构。
2、 训练数据的生成
采用传统SFM方法,得到三维点及其对应的一系列像素块的对应关系。选用的像素块为SFM中使用的特征点,这样能够提高样本的准确性。为了进一步提高样本准确性,本文对得到的三维点云采用Delaunay triangulation方法进行滤波。
在得到三维点和特征点的对应关系后,选取一系列特征点对应的像素块,并通过一个相似变换,将这些像素块变换到同一尺度、同一主方向下:
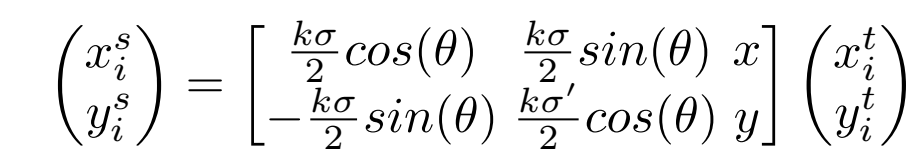
其中的尺度因子和主方向,均来自于SIFT特征点。
3、 几何相似度估计
本文提出了两种几何相似度:像素块对的几何相似度、图片对的几何相似度。这两个指标能够反映视角的变化,从而能够衡量像素块对匹配的难度。
像素块相似度:
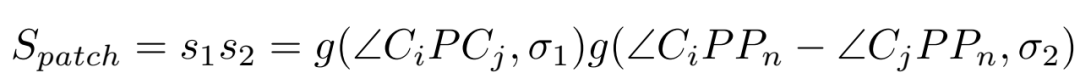
如图1所示,它由视角以及三维点云的法向量决定,能够反映两个像素块的由于视角变化而产生的差异。
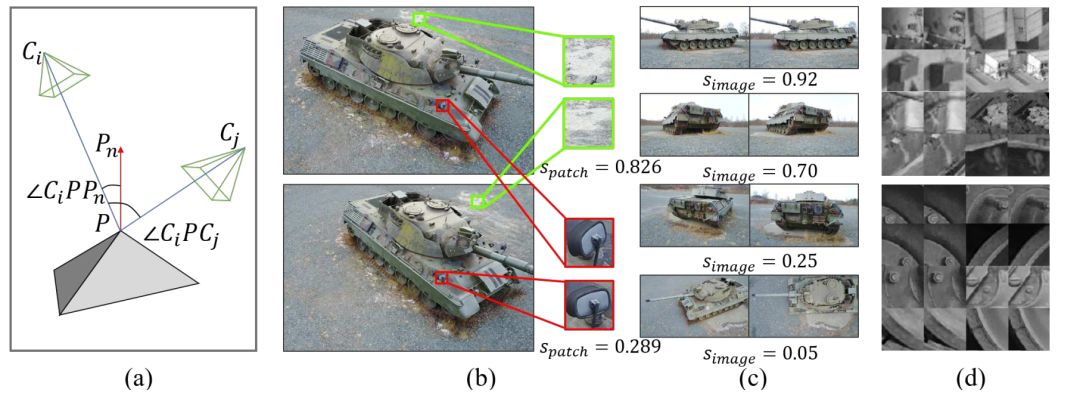
图1. (a)像素块的相似度取决于相机的几何关系以及物体表面的法向量。(b)像素块相似度的作用:能够度量由视角变化引起的匹配难度。(c)图像对相似度:衡量两张图像的视角变化。(d)上部分为由L2-Net和HardNet批量构建方法得到的样本,该样本中不同特征点往往区分度很大,因此在训练中无法产生有效的损失量。下部分为本文提出的批量构建方法产生的样本,不同特征点相似度很高,使得其很难区分,进而增加了训练的难度。
图像对相似度:两帧图像中,所有对应的像素块对的相似度的平均值。反映了两张图像的视角变化。
4、 训练数据批量的构建
由于训练的收敛率依赖于“有用的样本”——能够在学习过程中产生有效损失的样本。本文提出了一种新的训练数据批量的构建方式。以往的方法往往从整个数据集中选取特征点构建批量,本文从两张图片中选取一系列对应的特征点来构建训练数据批量,即:
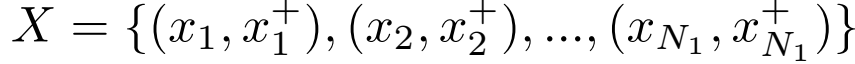
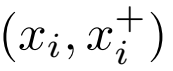
分别为来自第一张图及第二张图的匹配的点。这样做的好处为:一是、这样有效模拟了两张图片匹配的过程;二是、能够产生足够“硬”的样本,这是因为同一张图的特征点往往会由于有相似的纹理等比较接近,使得不同特征点更加难以区分。
5、 损失函数
本文提出的损失函数包含两项:结构损失函数以及几何损失函数。
结构损失函数定义了对应特征点的描述子的相似程度,为提高计算效率,本文采用了夹角余弦值相似度(两个向量夹角的余弦值,对于两个单位向量,即为两个向量的点乘),其计算过程如下:
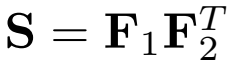
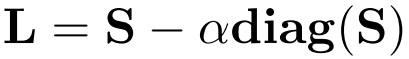
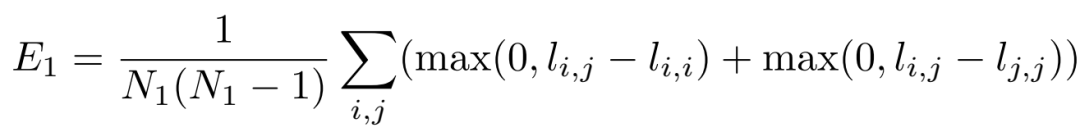
其中,
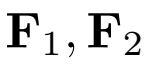
分别为来自第一张图片、第二张图片特征点的描述子矩阵。
该损失函数能够保证匹配的点的相似度远离非匹配的点的相似度。但无法保证匹配点的描述子足够接近,为此,本文提出了几何相似度:
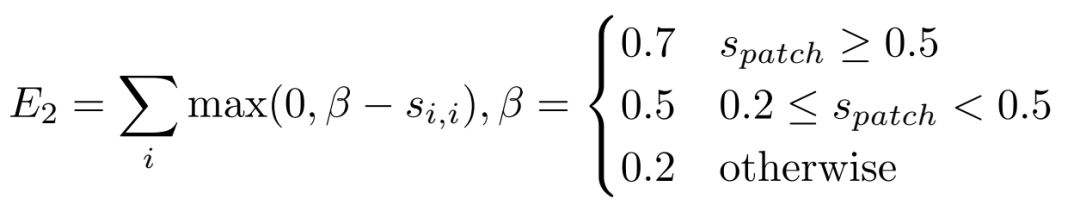
其中,
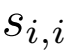
表示匹配的特征点的描述子余弦相似度。
主要结果
本文在三个数据集上测试了本文的方法,并将本文的描述子应用到SFM中,以测试其实际应用性能,实验结果如下:
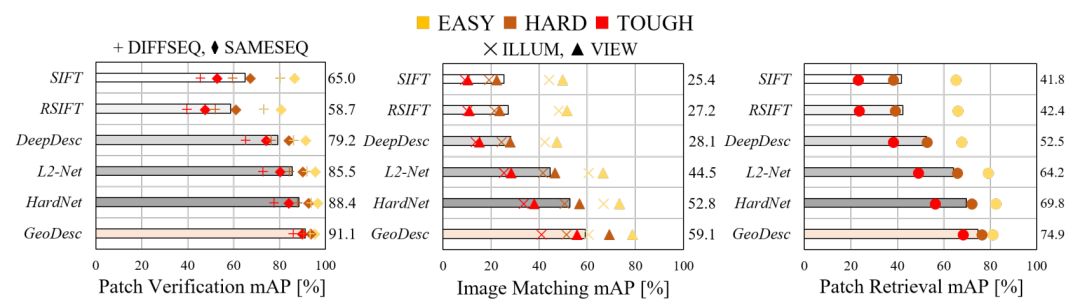
图2. 从左往右依次为:在HPatches数据集上验证、匹配和索引的结果。
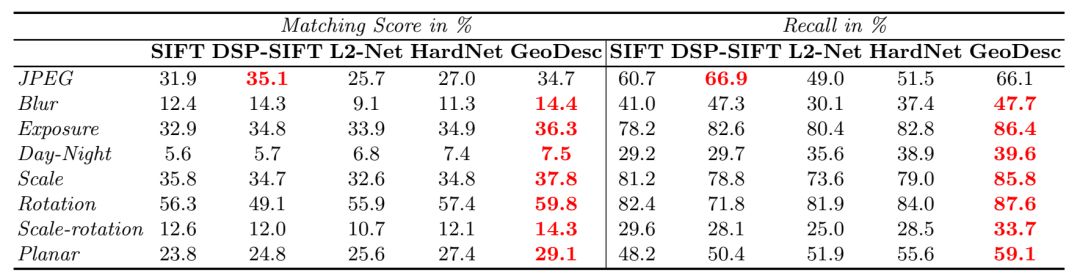
表1:Heinly等人提出的数据集上图片匹配结果。
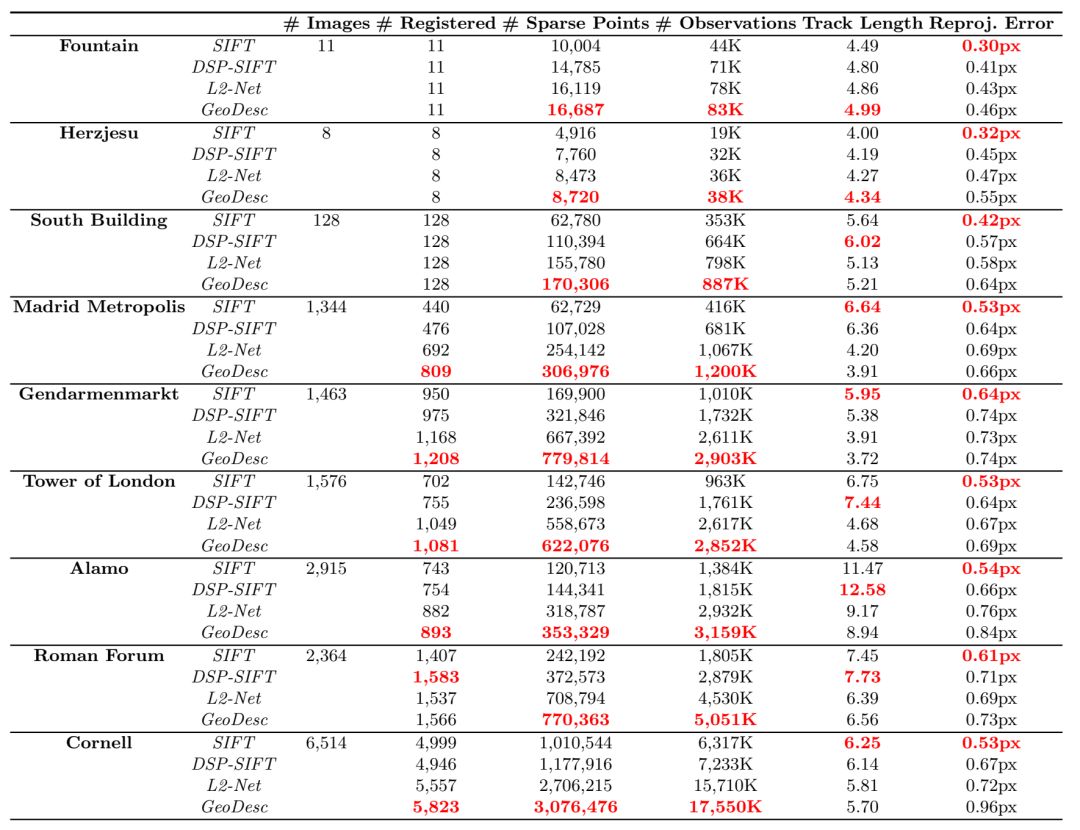
表2. ETH局部特征数据集上SFM任务结果。

图3. 基于SIFT失败,而基于本文方法能够成功的SFM示例。

Abstract
Learned local descriptors based on Convolutional Neural Networks (CNNs) have achieved significant improvements on patch-based benchmarks, whereas not having demonstrated strong generalization ability on recent benchmarks of image-based 3D reconstruction. In this paper, we mitigate this limitation by proposing a novel local descriptor learning approach that integrates geometry constraints from multi-view reconstructions, which benefits the learning process in terms of data generation, data sampling and loss computation. We refer to the proposed descriptor as GeoDesc, and demonstrate its superior performance on various large-scale benchmarks, and in particular show its great success on challenging reconstruction tasks. Moreover, we provide guidelines towards practical integration of learned descriptors in Structure-from-Motion (SfM) pipelines, showing the good trade-off that GeoDesc delivers to 3D reconstruction tasks between accuracy and efficiency.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com

