【泡泡图灵智库】密集相关的自监督视觉描述学习(RAL)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Self-Supervised Visual Descriptor Learning for Dense Correspondence
作者:Tanner Schmidt, Richard Newcombe, and Dieter Fox
来源:IEEE ROBOTICS AND AUTOMATION LETTERS 2017
编译:皮燕燕
审核:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——密集相关的自监督视觉描述学习,该文章发表于IEEE ROBOTICS AND AUTOMATION LETTERS 2017。
图像像素之间的对应关系的高鲁棒性估计是机器人领域中的重要问题,其可应用于跟踪、建图和目标、场景以及其他事物的识别。长期以来,上述问题一直靠手工标识的特征进行估计计算,但最近深度学习的兴起使得基于原始数据学习获得特征成为了可能。后一种方法的缺点是学习需要大量(标记的,典型的)训练数据。本文提出了一种新的方法来学习稠密对应估计的视觉描述符,其中文章利用强大的三维生成模型自动标记RGB-D视频数据中的对应关系。使用对比损失训练完全卷积网络以产生视点和光照不变描述符。为了证明文章提出的方法,文章收集了两个数据集:第一个描述了在不同环境中同一个人的上半身和头部,第二个描述了在多日内看到的办公室,其中重新摆放了办公室内的物品。文章给出的数据集侧重于对相同对象和环境的再次访问,并且通过仅从本地跟踪数据训练CNN来证明,文章学习的视觉描述符通用于识别跨视频的非标记对应关系。进一步的实验结果表明,文章描述符学习方法可用于在MSR 7场景数据集上实现最先进的单帧定位结果,而无需使用任何标识在训练时识别相同场景的单独视频之间的对应关系。
主要贡献
1、 文章的方法允许机器人收集他们自己的训练数据并学习更好地了解他们所处的环境,而无需任何人为输入。
2 、在处理已见过以及已经到过的环境时,文章提出的方法比AlexNet功能更强大且更具辨别力。
算法流程
1、卷积神经网络结构
文章采用得是Long等人的全卷积网络架构,但是对输出维数进行了修改。
2、训练数据
假设有一组V视频,每个视频有K帧。鉴于描述符函数f(x)被参数化为卷积神经网络,文章将将像素级对比度损失函数定义为
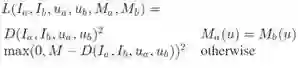
文章的网络使用流行的Caffe架构从头开始训练,修改后的对比度损失层将两个图像,两个顶点图和样本点对作为输入,计算上述等式中定义的损失。在反向传播期间,每个采样对的损失被添加到密集梯度图中的适当位置,使得所有样本的损失同时向网络反向传播。除非另有说明,否则文章的网络训练采用D = 32。
主要结果
1、 定性结果
如图1所示,文章展示了来自视频的帧,这些帧的网络输出以及融合到模型表面上的平均网络输出。
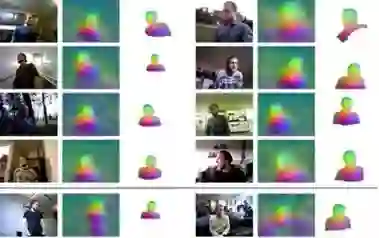
图1 使用R3输出对人类数据集进行训练的特征可视化
2、定量结果
SIFT基线:如图2所示,在两个数据集上,使用文章的描述符比使用密集SIFT以及AlexNet描述符时误报率低。
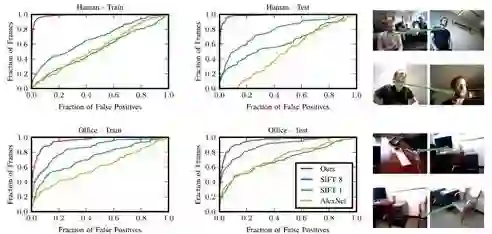
图2 人类数据集(上图)和办公室数据集(下图)的定量结果
MSR 7-Scenes结果如表1所示。
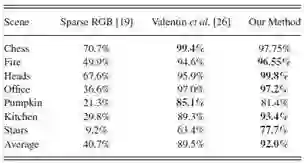
表1 MSR 7-scenes 中误差在5cm以及5°以内的百分比
如图3所示用R32表示。通过选择与强视觉特征不一致的点,显示文章提出的模型具有使用上下文来消除纹理差的图像区域中的点的歧义的能力。

图3 左侧,突出显示7场景数据集中“办公室”场景的图像中的三个点。 在右侧,办公场景的所有视频(包括测试视频)中的这三个点的所有32维描述符显示在平行坐标图上,线的颜色对应于点的颜色。
3、可变形模型的重定位应用
文章提出的方法还可用于训练对重定位可变形模型的姿态有用的网络。 结果如图4所示。
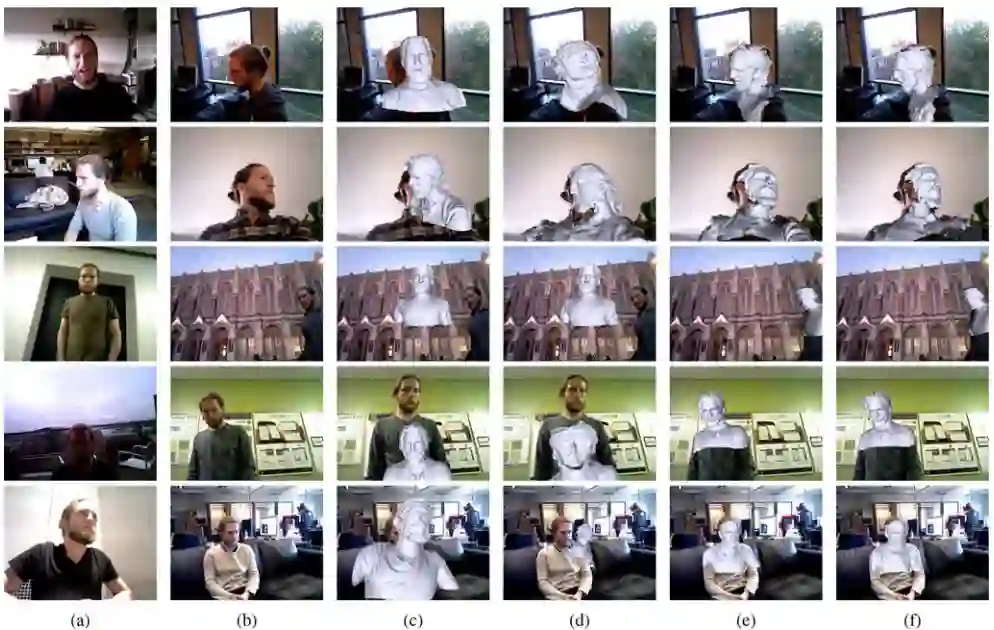
图4 每行代表尝试在另外一个视频中定位视频构建的DynamicFusion模型,采用和不采用文章提出的学习的描述符的结果

Abstract
Robust estimation of correspondences between image pixels is an important problem in robotics, with applications in tracking, mapping, and recognition of objects, environments, and other agents. Correspondence estimation has long been the domain of hand-engineered features, but more recently deep learning techniques have provided powerful tools for learning features from raw data. The drawback of the latter approach is that a vast amount of (labeled, typically) training data are required for learning. This paper advocates a new approach to learning visual descriptors for dense correspondence estimation in which we harness the power of a strong three-dimensional generative model to automatically label correspondences in RGB-D video data. A fully convolutional network is trained using a contrastive loss to produce viewpoint- and lighting-invariant descriptors. As a proof of concept, we collected two datasets: The first depicts the upper torso and head of the same person in widely varied settings, and the second depicts an office as seen on multiple days with objects rearranged within. Our datasets focus on revisitation of the same objects and environments, and we show that by training the CNN only from local tracking data, our learned visual descriptor generalizes toward identifying nonlabeled correspondences across videos.We furthermore show that our approach to descriptor learning can be used to achieve state-of- the-art single-frame localization results on the MSR 7-scenes dataset without using any labels identifying correspondences between separate videos of the same scenes at training time.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



