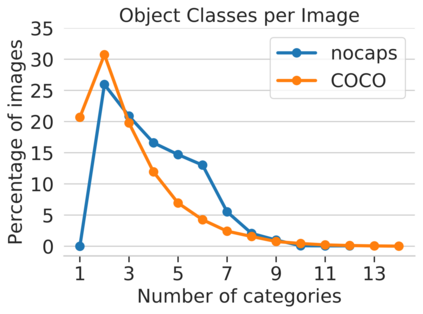
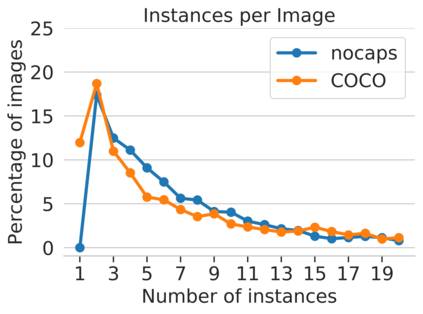
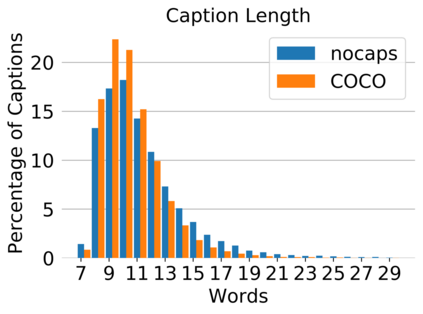
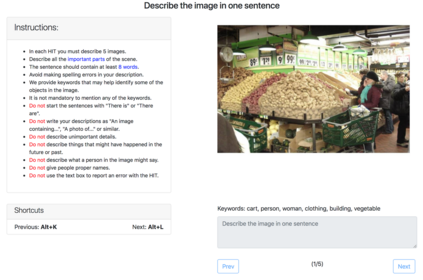
Image captioning models have achieved impressive results on datasets containing limited visual concepts and large amounts of paired image-caption training data. However, if these models are to ever function in the wild, a much larger variety of visual concepts must be learned, ideally from less supervision. To encourage the development of image captioning models that can learn visual concepts from alternative data sources, such as object detection datasets, we present the first large-scale benchmark for this task. Dubbed 'nocaps', for novel object captioning at scale, our benchmark consists of 166,100 human-generated captions describing 15,100 images from the Open Images validation and test sets. The associated training data consists of COCO image-caption pairs, plus Open Images image-level labels and object bounding boxes. Since Open Images contains many more classes than COCO, more than 500 object classes seen in test images have no training captions (hence, nocaps). We evaluate several existing approaches to novel object captioning on our challenging benchmark. In automatic evaluations these approaches show modest improvements over a strong baseline trained only on image-caption data. However, even when using ground-truth object detections, the results are significantly weaker than our human baseline - indicating substantial room for improvement.
翻译:在包含有限视觉概念和大量配对图像描述培训数据的数据集中,图像字幕模型取得了令人印象深刻的成果。然而,如果这些模型要在野生环境中永远发挥作用,则必须学习更多的视觉概念,最好是从较少的监督中学习。为了鼓励开发能够从其他数据源(如物体探测数据集)中学习视觉概念的图像字幕模型,我们为这项任务提出了第一个大型基准。对于规模上的新目标字幕,我们的基准由166 100个人类产生的字幕组成,描述来自开放图像验证和测试组的15 100个图像。相关的培训数据包括COCOCO图像描述配对,加上开放图像级标签和对象捆绑框。由于开放图像包含比COCO更多的课程,在测试图像中看到的500多个对象课程没有培训字幕(hence, nocaps)。我们评估了现有几种关于我们具有挑战性基准的新目标字幕的方法。在自动评估中,这些方法显示,在只对图像描述数据所训练的强基线方面稍有改进。然而,即使使用地面测量的结果也比人类的要弱得多。