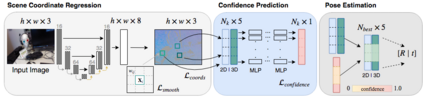
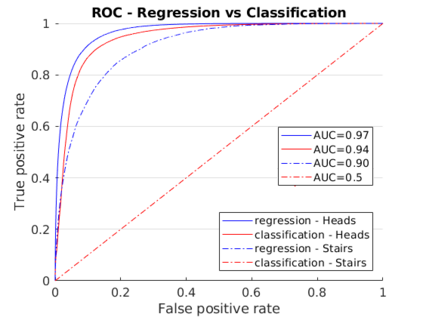
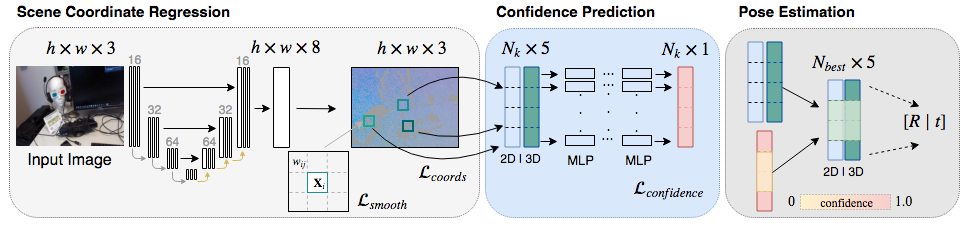
Scene coordinate regression has become an essential part of current camera re-localization methods. Different versions, such as regression forests and deep learning methods, have been successfully applied to estimate the corresponding camera pose given a single input image. In this work, we propose to regress the scene coordinates pixel-wise for a given RGB image by using deep learning. Compared to the recent methods, which usually employ RANSAC to obtain a robust pose estimate from the established point correspondences, we propose to regress confidences of these correspondences, which allows us to immediately discard erroneous predictions and improve the initial pose estimates. Finally, the resulting confidences can be used to score initial pose hypothesis and aid in pose refinement, offering a generalized solution to solve this task.
翻译:场点协调回归已成为当前相机重新定位方法的一个基本部分。 不同的版本,如回归森林和深层学习方法,已被成功应用来估计相应的相机所呈现的单一输入图像。 在这项工作中,我们提议通过深思熟虑的方式,将场景坐标像素回溯到特定的 RGB 图像中。 与最近通常使用RANSAC 来从既定的通信中获取稳健的构成估计的方法相比,我们提议回溯这些通信的信心,从而使我们能够立即放弃错误的预测并改进最初的构成估计。 最后,由此产生的信任可以用来在最初的假设中进行评分,帮助进行推敲,为完成这项任务提供一个普遍的解决办法。