【泡泡一分钟】利用相对位姿信息进行辅助学习的视觉定位和里程估计方法
每天一分钟,带你读遍机器人顶级会议文章
标题:Deep Auxiliary Learning for Visual Localization and Odometry
作者:Abhinav Valada 、 Noha Radwan 、 Wolfram Burgard
来源:2018 IEEE International Conference on Robotics and Automation
播音员:Sophie
编译:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——利用相对位姿信息进行辅助学习的视觉定位和里程估计方法,该文章发表于ICRA 2018。
定位是机器人自主运行必备的一项功能,它可以确定机器人在当前环境中所处的位置,同时也是进行路径规划或其他任务的前提条件。于传统的方法相比,尽管卷积神经网络在视觉定位方面有出色的表现,但它仍是基于局部特征实现的。在本文中我们提出VLocNet,一种新的卷积神经网络架构,来实现从连续的单目图像中进行6-DoF全局位姿和里程估计。我们的多任务模型融合了一些难以共享的参数,因此除了可以进行端到端的可训练之外,还可以实现紧凑的实时推断。文章中提出了一种新的损失函数,在训练期间使用辅助学习对相对位姿信息加以利用,从而约束了搜索空间以获得一致的姿态估计。我们在室内数据集和室外数据集上对VLocNet进行了评估,实验结果表明即使是单一任务模型,在全局定位方面也比现有的最先进的深度神经网络性能优异,同时还具备视觉里程计功能。此外,我们使用所提出的几何一致性损失进行了广泛的实验评估,来证明VLocNet在多任务学习方面的有效性,同时实验结果表明在某些情况下,VLocNet的表现优于一些基于SIFT的方法。
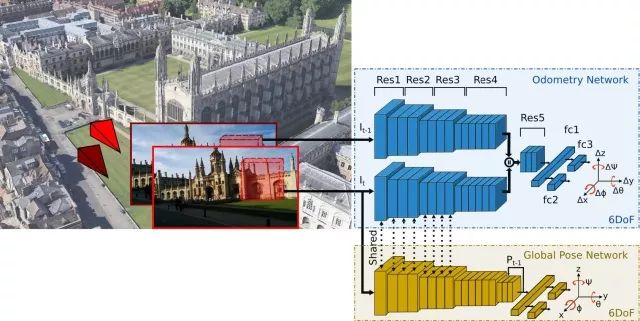
图1 本文中的多任务深度卷积神经网络
该网络将两张连续的单目图像作为输入,同时进行全局的6-DoF位姿和里程估计。
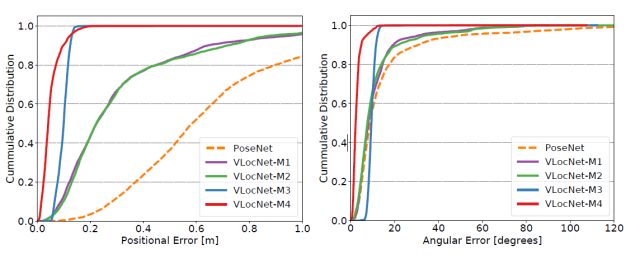
图2 VLocNet和PoseNet的定位效果对比
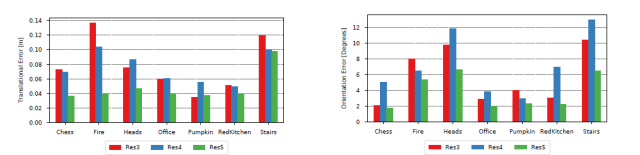
图3 VLocNet的定位误差
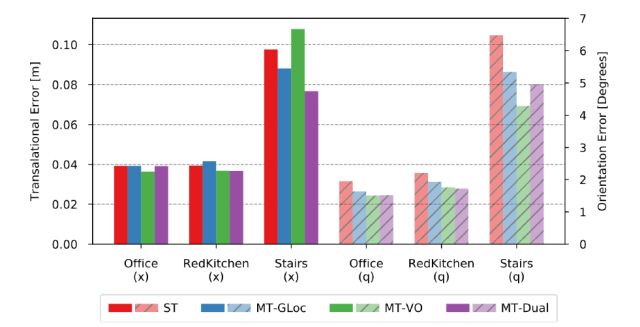
图4 单一任务模型和使用不同权重初始化的具有多任务能力的VLocNet的效果对比,(该实验使用7-Scenes数据集)

Abstract
Localization is an indispensable component of a robot’s autonomy stack that enables it to determine where it is in the environment, essentially making it a precursor for any action execution or planning. Although convolutional neural networks have shown promising results for visual localization, they are still grossly outperformed by state-of-the-art local feature based techniques. In this work, we propose VLocNet, a new convolutional neural network architecture for 6-DoF global pose regression and odometry estimation from consecutive monocular images. Our multitask model incorporates hard parameter sharing, thus being compact and enabling real-time inference, inaddition to being end-to-end trainable.We propose a novel loss function that utilizes auxiliary learning to leverage relative pose information during training, thereby constraining the search space to obtain consistent pose estimates. We evaluate our proposed VLocNet on indoor as well as outdoor datasets and show that even our single task model exceeds the performance of state-of-the-art deep architectures for global localization, while achieving competitive performance for visual odometry estimation. Furthermore, we present extensive experimental evaluations utilizing our proposed Geometric Consistency Loss that show the effectiveness of multitask learning and demonstrate that our model is the first deep learning technique to be on par with, and in some cases outperforms state-of-the art SIFT-based approaches.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


