
主题: Multi-View Learning for Vision-and-Language Navigation
摘要:
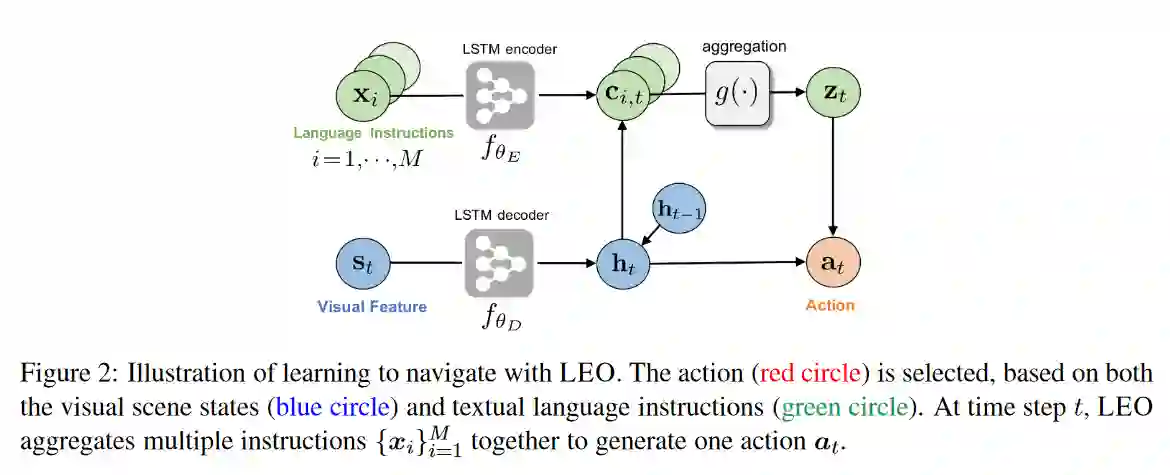
学习遵循自然语言指令在视觉环境中导航是一项具有挑战性的任务,因为自然语言指令具有高度的可变性、模糊性和欠指定性。在本文中,我们提出了一种新的训练模式,从每个人身上学习(LEO),它利用多条指令(作为不同的视图)来解决同一轨迹下的语言歧义,提高泛化能力。通过在指令之间共享参数,我们的方法可以更有效地从有限的训练数据中学习,并在不可见的环境中更好地推广。在最近的Room-to-Room(R2R)基准数据集上,LEO在路径长度加权的成功率(SPL)方面比贪婪的代理(25.3%-41.4%)提高了16%(绝对)。此外,LEO是对大多数现有视觉和语言导航模型的补充,允许与现有技术轻松集成,从而导致LEO+,这创造了新的技术水平,将R2R基准推高到62%(9%的绝对改善)。 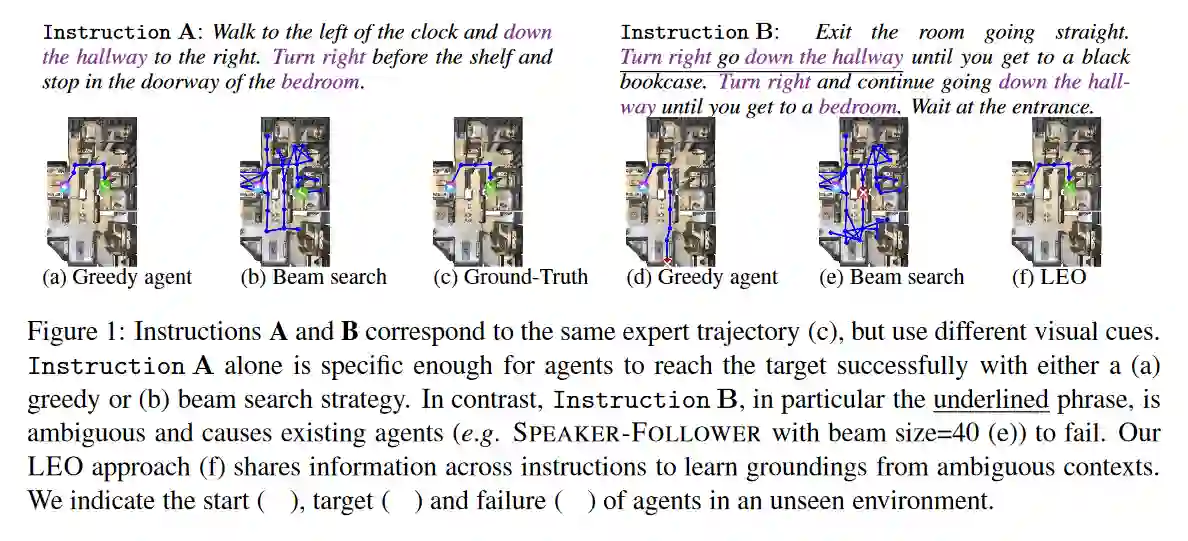
成为VIP会员查看完整内容
相关内容

华盛顿大学(University of Washington)创建于1861年,坐落在美国最适宜居住和工作的城市西雅图,是美国西海岸最古老的大学,是一所世界顶尖的著名大学,长期保持世界大学财政支出和研究经费前三位。华盛顿大学拥有世界最顶尖的教师队伍,拥有29,804名教职员工,包括5803名教师,师生比例为 1:7.3 ,其中众多教授为所在学术领域的世界领导者。
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
13+阅读 · 2020年3月12日


相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
13+阅读 · 2020年3月12日
相关资讯
相关论文