题目: Pose-Assisted Multi-Camera Collaboration for Active Object Tracking
关键词:协作 多相机 主动目标追踪
简介
对相机进行智能控制从而实现目标追踪是一项非常具有挑战性的任务。由于环境的复杂性,相机所接收到的视觉信息常常是不完美的,比如环境中存在的障碍物对目标极容易造成遮挡,目标距离远的情况下形态变得不够清晰,相似的背景容易导致目标的混淆等等。传统的方法只靠视觉信息做追踪,在视觉信息质量不够高的情况下很容易导致相机追踪的失败。因此,本文提出引入相机姿态的多相机协同合作机制进行监控场景下的目标追踪,通过对比不同测试环境上的实验结果,本文证实了这种合作机制的有效性和可拓展性。
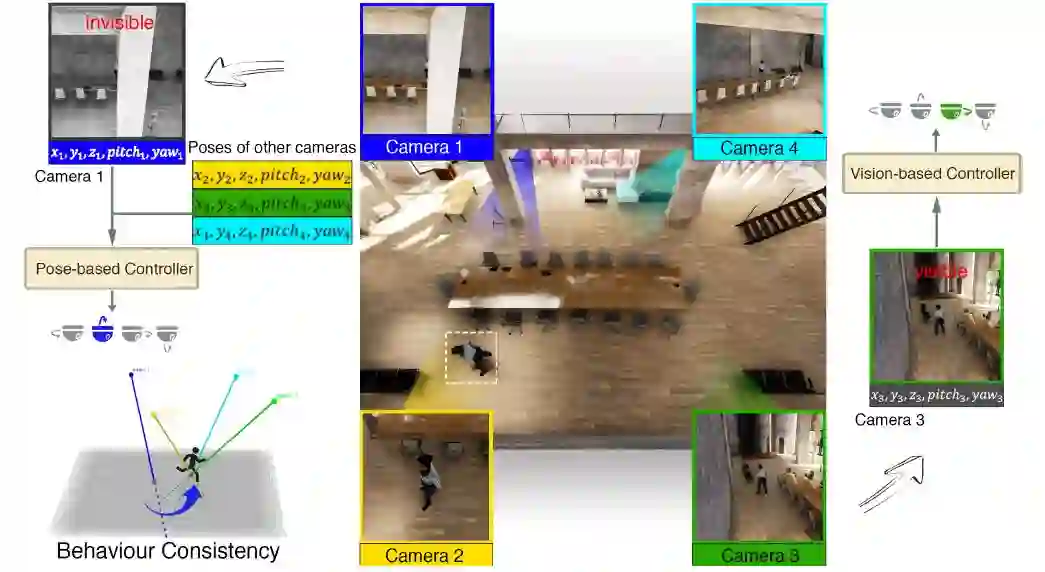
▲ 图1:多相机协作追踪
方法介绍
在本文设计的多相机合作机制下,每个相机均有一个基于视觉信息的控制器,一个基于姿态信息的控制器和一个转换器。基于视觉的控制器使用图片作为输入,输出相机智能体的动作。基于姿态的控制器使用所有相机的姿态信息即所有相机的位置,视角及转换器的二分类标签作为输入,输出相机的动作。而转换器负责在两个控制器之间进行切换,当相机的视觉信息不足以进行追踪即基于视觉信息的控制器失败时,如图1中的1号相机,转换器将会使用辅助的基于姿态的控制器进行相机行为控制,从而保证多相机系统进行稳定的合作追踪。
如图2所示,基于视觉信息的控制器模块由 CNN(卷积神经网络)进行特征提取,后续接入 LSTM(长短期记忆神经网络)进行历史信息的处理,最后由 FC(全连接网络)输出动作;同时,LSTM 输出的特征会被转换器中的 FC 处理后输出二分类概率,相机的最终执行动作为最大概率的对应控制器所输出的动作。基于姿态的控制器通过 GRU(门控递归神经网络)进行多相机姿态信息的融合,然后由后续的 FC 网络输出每一个相机的动作。转换器由一个 FC 网络构成,输入为 LSTM 处理后的特征,输出为二分类的概率。
通过这种合作机制,相机可以学到在视觉信息不足以支撑其决策时使用有效的姿态信息进行行为指导。
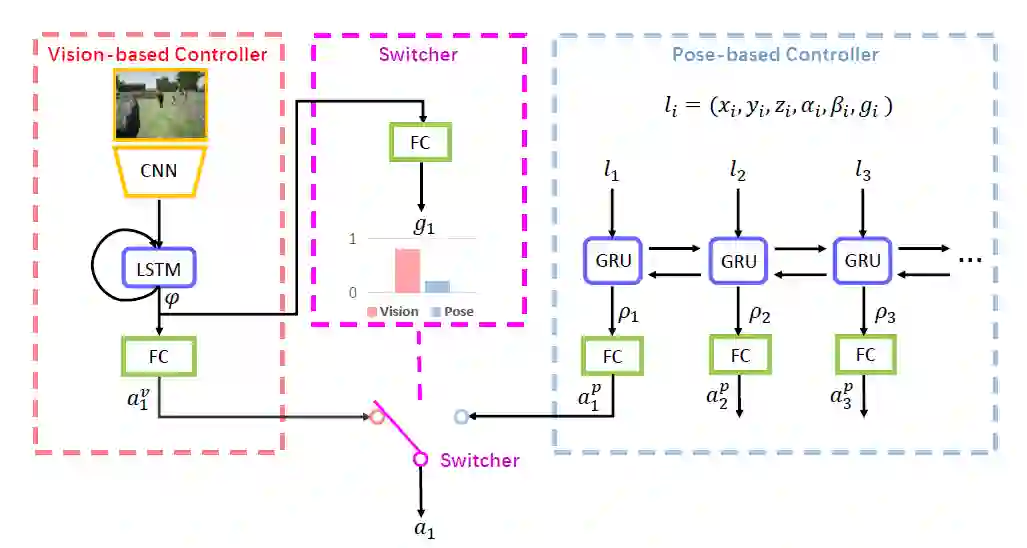
▲ 图2:网络结构
实验结果
本文的方法使用强化学习的A3C算法进行两个控制器的训练,同时在基于视觉信息的控制器的训练过程中,把转换器的分类任务作为辅助任务协同训练。训练环境为虚拟环境 UnrealCV 中的 RandomRoom 场景(如图3的前两行所示),在训练环境中,我们改变了房间的背景,目标人物的形态,并对场景中放置不同的障碍物等等。我们在新环境 Garden(如图3的第三行所示)和 Urban City(如图3的最后一行所示)中进行测试。

▲ 图3:训练环境和测试环境 从上到下代表不同环境,从左到右代表不同相机
对于实验结果的衡量,本文使用了平均角度误差和成功率来度量多相机系统的追踪性能,其中平均角度误差为长度为 T 的追踪时长下所有相机俯仰角和偏航角的误差平均:
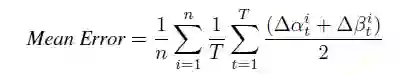
成功率指标(S)为所有相机长度为 T 的追踪时长下的成功率平均值:
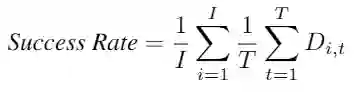
我们和传统方法 TLD,BACF 及 DasiamRPN 进行对比,由于传统方法在追踪过程中没有对相机的控制,我们对传统方法增加了基于规则的动作控制器,即相机基于检测边框的位置进行相应旋转。
实验中,我们发现传统方法在人物形态变化较大及障碍遮挡较大等情况中容易追踪失败,而我们的方法在相机丢失目标时,可以根据姿态信息的指导重新追踪回目标,如图4所示,3号相机的图片中失去了目标信息,其行为由基于视觉的控制器转为由基于姿态的控制器控制,通过保持和其他相机目标一致,基于姿态的控制器正确输出3号相机的动作使其寻回目标,保证了长期追踪的良好性能。实验的具体量化结果(平均角度误差和成功率)见表格1。

▲ 图4:追踪示例
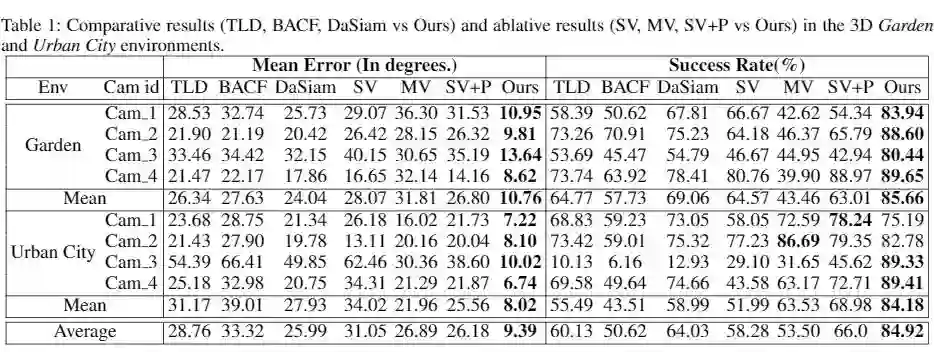
▲ 表格1:实验结果
为了验证本文设计的合作机制的有效性,我们设计了一系列消融实验,对比了各相机单独追踪(SV),使用 Bi-GRU,进行多相机的视觉信息融合(MV),使用 FC 网络进行视觉信息和姿态信息的融合(SV+P)的方法。其中我们的方法取得了最低的误差结果和最高的成功率,证明了使用转换机制对视觉信息和姿态信息进行结合可以达到最好的合作追踪效果。
结论
对于监控场景下的多相机主动追踪任务,本文提出一种新的多相机合作机制利用相机姿态辅助追踪,可以在视觉信息不完善的情况下保证追踪性能,给出了优于以往方法的结果。在全新测试环境(Garden/UrbanCity)上的结果展示了本文方法可以有效地拓展到更多场景。
参考文献
[1] Bertinetto, L.; Valmadre, J.; Henriques, J. F.; Vedaldi, A.; and Torr, P. H. 2016. Fully-convolutional siamese networks for object tracking. In European conference on computer vision,850–865. Springer. [2] Littman, M. L. 1994. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994. Elsevier. 157–163. [3] Luo, W.; Sun, P.; Zhong, F.; Liu, W.; Zhang, T.; and Wang, Y. 2018. End-to-end active object tracking via reinforcement learning. In International Conference on Machine Learning, 3286–3295.