【泡泡一分钟】一种自监督学习遮挡的方法来提高城市环境中单目视觉里程计的鲁棒性
每天一分钟,带你读遍机器人顶级会议文章
标题:Driven to Distraction: Self-Supervised Distractor Learning for Robust Monocular Visual Odometry in Urban Environments
作者:Dan Barnes, Will Maddern, Geoffrey Pascoe and Ingmar Posner
来源:2018 IEEE International Conference on Robotics and Automation (ICRA) May 21-25, 2018, Brisbane, Australia
编译:董文正
审核:颜青松 陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

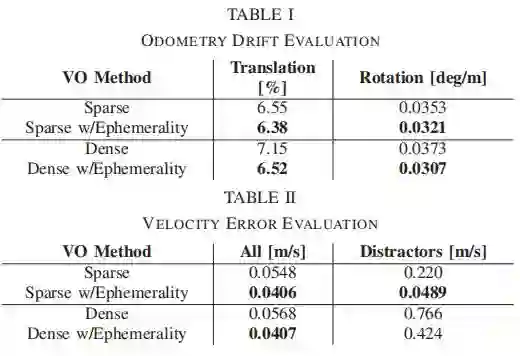
我们提出了一种可以忽略相机图像中“干扰物”的自监督方式,用来在杂乱的城市环境中更鲁棒地估计汽车的运动。我们利用离线的多场景建图的方法为每个输入的图片自动形成每个像素短暂的遮挡和深度地图,我们用它来训练深度卷积网络。在运行时,我们使用预测的短暂性和深度作为单目视觉里程计(VO)生成的输入,使用稀疏特征或者稠密的光度匹配。我们的方法仅使用一台相机即可产生公尺制的VO,即使动态、独立移动的物体遮挡了90%的图像信息,也可以恢复出正确的运动。我们在牛津机器人汽车数据集中仿真驾驶超过400km里程来评价我们VO的鲁棒性,证明了我们的方法在城市行驶中,能够使大型车辆减少里程计漂移和极大地提高运动估计的精度。

图1:使用单个相机和学习的短暂遮挡在城市环境中进行鲁棒的运动估计。 当左转弯到主要道路上时,一辆大型公共汽车经过车辆前方(绿色箭头)遮挡了场景视图(左上角)。 我们学习的短暂掩模正确地将总线识别为图像的不可靠区域以用于运动估计(右上)。 由于公交车的主导运动(左下),传统的视觉测距(VO)方法将错误地估计向右的强平移运动,而我们的方法正确地恢复车辆运动(右下)
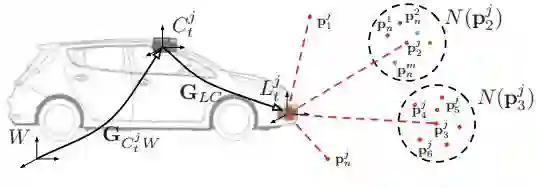
图2:多场景建图和3D点云熵计算。 对于每个遍历j,我们计算在每个时间戳t处的车辆GCjt W的全局姿势并且将点p投影到全局帧W中。然后我们分析每个点pji的邻域N; 在诸如N(pj2)之类的遍历{1···j}之间的点均匀分布的邻域中,在场景很可能是静态的,并且其中点主要来自诸如N(pj3)之类的一个遍历,该结构是短暂的。 我们使用应用于每个邻域N(p)的熵度量来量化静态场景。

图3:先前的3D映射确定静态3D场景结构。 路线的多次遍历(左上)的对齐将产生仅在单次遍历中出现的大量点,例如, 交通或停放的车辆,这里显示为白色。 这些点会破坏合成深度图(右上角)。我们的基于熵的方法会移除仅在某些遍历中观察到的3D点,并保留在数据收集期间保持静态的结构(左下角),从而导致高质量合成深度图(右下)。
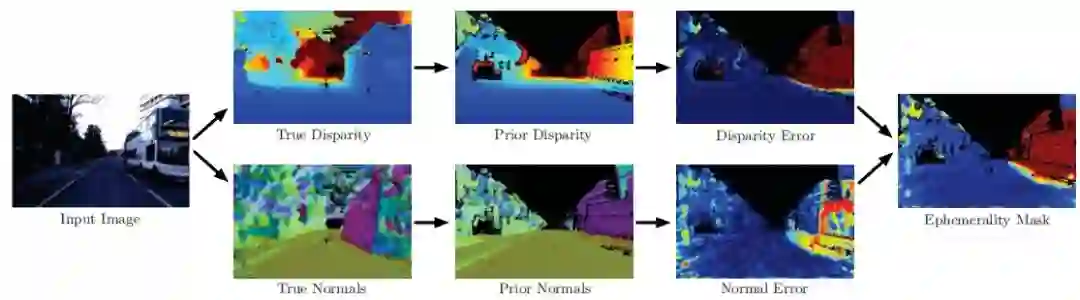
图4:短暂标记过程。 从输入图像(左)我们使用离线密集立体方法计算真实视差di和法线ni。 然后,我们将先前的3D点云pS投影到图像中以形成先前的视差dSi和先前的正常nSi。 将差异和正常误差项组合以形成短暂遮挡(右)
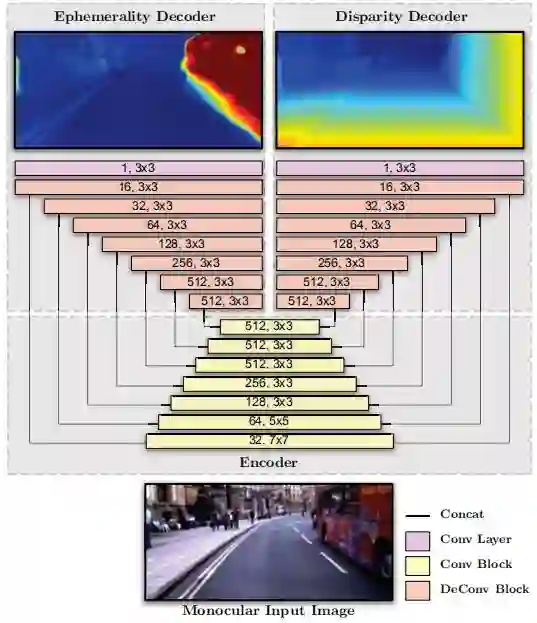
图5:用于短暂性和视差学习的网络体系结构。每个块的宽度表示特征图的空间维度,其在块之间变化2倍。 每个块还详细说明了输出通道的数量和滤波器尺寸。

图6:输入短暂感知视觉测距的数据。 对于给定的输入图像(左上角),网络预测密集的深度图(右上)和短暂的掩模。 对于稀疏VO方法,短暂掩模用于选择哪些特征用于优化(左下),对于密集VO方法,光度误差项由短暂掩模直接加权(右下)。

图7:在充满挑战的城市环境中生成的短暂遮挡。 这些遮挡可靠地突出了各种各样的动态物体(汽车,公共汽车,卡车,骑自行车者,行人,婴儿车),其距离和方向变化很大。尽管缺乏其他场景背景,即使是几乎完全遮挡相机图像的公共汽车和卡车也会被成功掩盖。使用短暂的强大VO方法可以提供正确的运动估计,即使超过90%的静态场景被独立移动的对象遮挡也是如此。
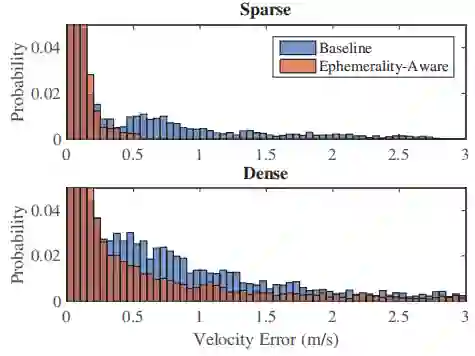
图8:在干扰物存在的情况下的速度估计误差。 稀疏的短暂感知方法明显优于基线方法,产生的异常值远低于0.5 m/s。 密集的短暂感知方法表现不佳,但仍然优于基线。缩放垂直轴以突出显示异常值。

图9:短暂遮挡广泛适用于自动驾驶车辆。在上述场景中,短暂掩模可用于仅针对静态场景(左下)通知定位,同时仅将物体检测引导至短暂元素(右下)。

Abstract
We present a approach to ignoring “distractors” in camera images for the purposes of robustly estimating vehicle motion in cluttered urban environments. We leverage offline multi-session mapping approaches to automatically generate a per-pixel ephemerality mask and depth map for each input image, which we use to train a deep convolutional network. At run-time we use the predicted ephemerality and depth as an input to a monocular visual odometry (VO) pipeline, using either sparse features or dense matching. Our approach yields metric-scale VO using only a single camera and can recover the correct egomotion even when 90% of the image is obscured by dynamic, independently moving objects.We evaluate our robust VO methods on more than 400km of driving from the Oxford RobotCar Dataset and demonstrate reduced odometry drift and significantly improved egomotion estimation in the presence of large moving vehicles in urban traffic.
如果你对本文感兴趣,请点击点击阅读原文下载完整文章,如想查看更多文章请关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
百度网盘提取码:mri7
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



