
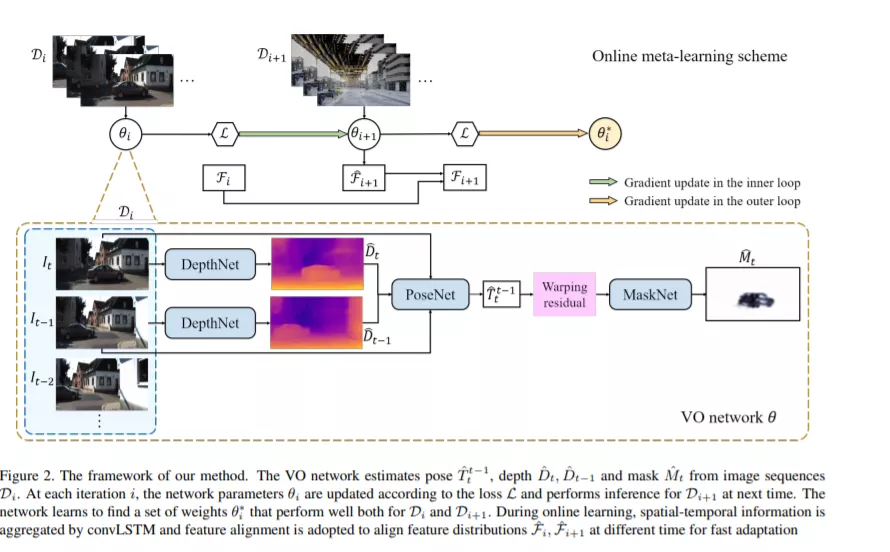
自监督式VO方法在视频中联合估计摄像机姿态和深度方面取得了很大的成功。然而,与大多数数据驱动的方法一样,现有的VO网络在面对与训练数据不同的场景时,性能显著下降,不适合实际应用。在本文中,我们提出了一种在线元学习算法,使VO网络能够以一种自监督的方式不断适应新的环境。该方法利用卷积长短时记忆(convLSTM)来聚合过去的丰富时空信息。网络能够记忆和学习过去的经验,以便更好地估计和快速适应当前帧。在开放环境中运行VO时,为了应对环境的变化,我们提出了一种在线的特征对齐方法,即在不同的时刻对特征分布进行对齐。我们的VO网络能够无缝地适应不同的环境。在看不见的户外场景、虚拟到真实世界和户外到室内环境的大量实验表明,我们的方法始终比最先进的自监督的VO基线性能更好。
成为VIP会员查看完整内容
相关内容

专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
26+阅读 · 2020年2月16日
相关VIP内容
专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
26+阅读 · 2020年2月16日
相关资讯
相关论文