GCNv2-SLAM:用CNN提取特征点取代ORB
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:夏天
https://zhuanlan.zhihu.com/p/71515279
本文已由作者授权,未经允许,不得二次转载
论文:
V1:Geometric Correspondence Network for Camera Motion Estimation
Jiexiong Tang, 2018, IEEE ROBOTICS AND AUTOMATION LETTERS
V2:GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
https://github.com/jiexiong2016/GCNv2_SLAM
主要思想:
用CNN学习特征点和描述子的提取,利用RGB-D深度信息、相机真实相对位姿,通过3D-2D投影关系进行监督学习。
V1版本采用CNN+RCNN得到原图尺寸(resize成ResNet可接受大小320\*240)中每个像素点为keypoint的概率,以及每个像素点的描述子向量(256\*1)
在V2版本中借鉴SuperPoint思想,简化网络结构,并构建与ORBSLAM2相同的二进制描述子来加速匹配,并结合ORBSLAM2,替换掉特征提取部分,构建了TX2上实时的GCNv2-SLAM.
做法:
V1:
1. 输入:
两张有重叠部分的图像,输出:图像中每个像素是特征点的概率和像素点的描述子向量。
2. 监督信息的产生
训练数据:
通过Harris角点对A图像进行检测,为了生成足够的特征点,运行两次检测过程,第一次用全图进行检测,第二次将图像分割成4\*4的小块进行检测。
对于A图中检测到的角点,利用AB图之间的相对位姿关系,进行warp
$y_i^*=\pi ^{-1}(R ·\pi(x_i, d_i) + t)$,得到在B图中的真实对应关系,对于无深度值可投影后超出边界的特征点丢弃,好处在于对于图像中比较相似的地方但非真实匹配的地方不会误判,也能保证相同的特征点在两张图中都能出现(可借鉴,但由于采用Harris角点,所以检测出的特征点应该来说比较密集)。
如上,真实特征点和真实匹配点对均得到了,但由于不可避免的噪声(深度信息的噪声,Ground truth的误差,相机内参标定误差,),可能导致warp keypoint的匹配精度受损,故在计算Loss的时候寻找近邻的阈值放宽,认为在5个像素的以内都是真值。
3. 网络结构 & LOSS
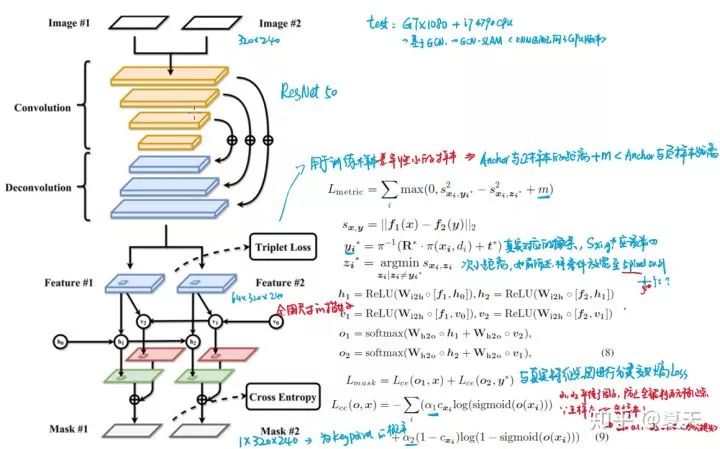
V2:
1. 输入:两张有重叠部分的图像,输出:图像中每个像素是特征点的概率和像素点的**二进制**描述子向量。拥有和GCN相近的精度,推理用时更短,并在板载无人机上(TX2)上能达到20Hz-40Hz的运行速度。
6. 监督信息的产生
训练数据:
不同于V1,采用SHI-Tomasi角点,检测16\*16的图像块,其他操作如V1。
This leads to better distribution of keypoints and the objective function directly reflects the ability to track the keypoints based on texture。
7. 网络结构 & LOSS
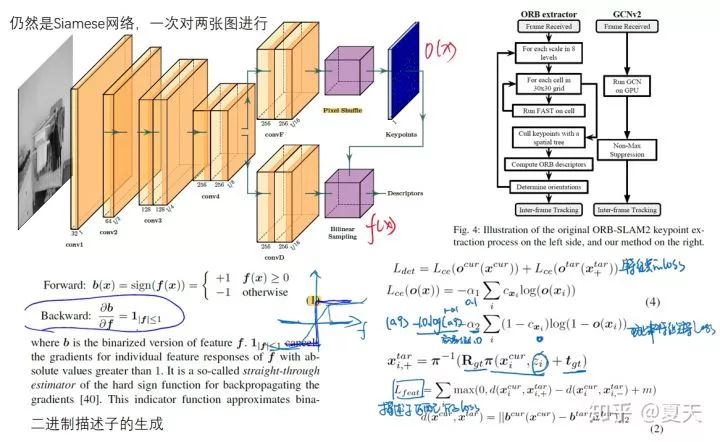
效果:
V1:
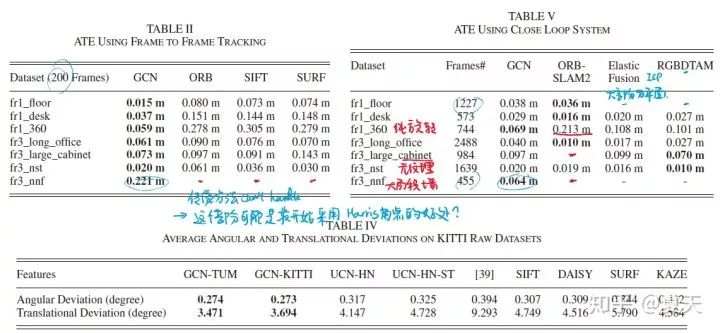
且在长时间的序列中没有发生跟踪丢失的现象。
V2:
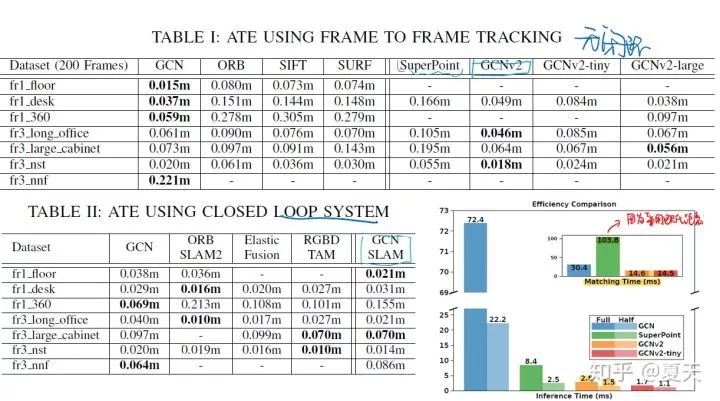
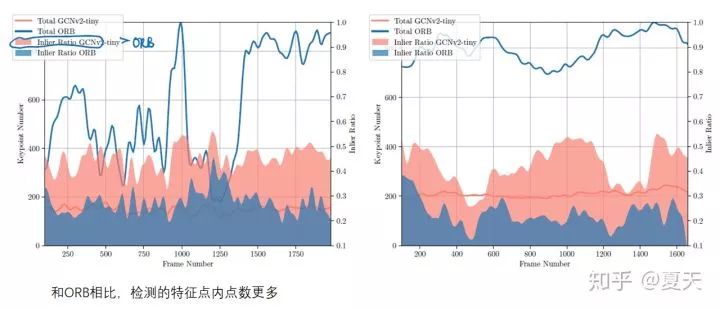
总结:
在V1中作者提到的展望在V2基本完成了(更高效/二进制描述子)。
孪生网络训练方式借鉴,可以考虑结合语义之类,用Harris或其他角点检测方法,提取的还是低维度信息,而且通篇都是利用3D投影变换进行的学习,不是单纯的像Superpoint着眼于特征点提取上,尽管在outdoor数据上也取得了较好的效果,但其他泛化效果有待考察(利用RGB-D局限于室内尺度),但任务驱动型思想很好。(emm..我都想到了就是还没做出来)
重磅!CVer-SLAM交流群成立啦
扫码添加CVer助手,可申请加入CVer-SLAM学术交流群。一定要备注:研究方向+地点+学校/公司+昵称(如SLAM+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



