【泡泡图灵智库】CNN-SVO 提升半直接视觉里程计的建图效果(arXiv)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:CNN-SVO Improving the Mapping in Semi-Direct Visual Odometry
作者:Shing Yan Loo, Ali Jahani Amiri, Syamsiah Mashohor, Sai Hong Tang,Hong Zhang
来源:arXiv 2018
编译:李伟
审核:SR
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——CNN-SVO Improving the Mapping in Semi-Direct Visual Odometry,该文章发表于arXiv 2018。
视频帧间可靠的特征匹配是视觉里程计和视觉SLAM的重要一步。半直接法的视觉里程计(SVO)有两大优势:直接的像素匹配和高效的概率建图方法的实施。本文通过采用单一图像预测网络去初始化深度的均值和方差,从而提升了SVO的建图效果。该方法可以带来两大优势:1、可靠的特征匹配;2、快速收敛到真实的深度值。本文在KITTI和Oxford Robotcar两个室外数据集上进行了验证。结果表明该方法提升了建图的鲁棒性和相机追踪的精确性。代码链接:https://github.com/yan99033/CNN-SVO
主要贡献
1.将一种深度估计网络与SVO结合。
2.提升了SVO建图的鲁棒性和精确性。
算法流程
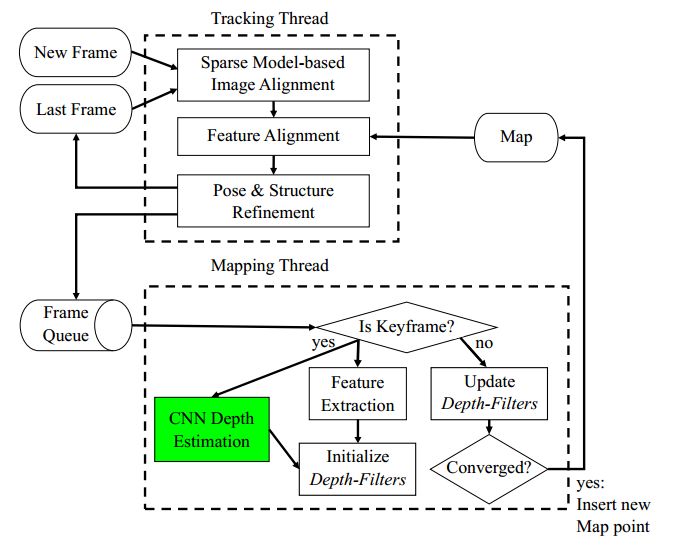
图1 CNN-SVO算法框架
1.SVO算法回顾
提取相邻两帧的ORB特征,通过使用李群最小化流形上的代价函数:SVO包含两个线程同时运行,追踪线程和建图线程。在追踪线程中,相机的位姿通过最小化参考帧图像块和新帧图像块的光度误差获得,然后通过逆成分公式优化。在建图线程中,初始化新的地图点和将合适的新地图点插入地图中。
但是,SVO在初始化新的地图点时具有很大的不确定性,并且将平均深度设置为参考帧的平均深度。因此,大的深度不确定性会带来以下两个问题:1.更大的极线特征匹配误差;2、更多的深度测量值才能收敛到真实的深度值,如图2所示。
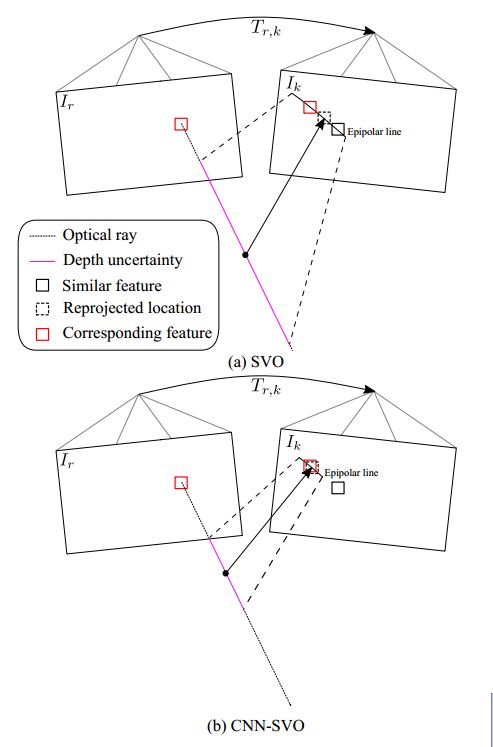
图2 两种地图点初始化策略对比
2、CNN-SVO:
如图1所示,绿色的框为增加的CNN深度估计预测。CNN-SVO通过单一图像深度估计作为先验知识去获得均值和方差更小的深度滤波器。SVO的深度滤波器的采用Gaussian + Uniform混合模型。
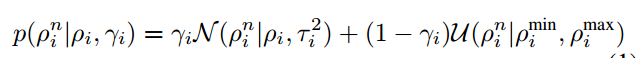
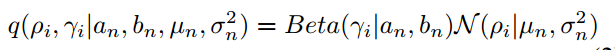
因此每一个深度滤波器可以通过以下参数进行初始化:逆深度的均值µn,逆深度的方差σn2,内点率 an 和bn.如表1所示,为SVO和CNN-SVO初始化参数的比较。
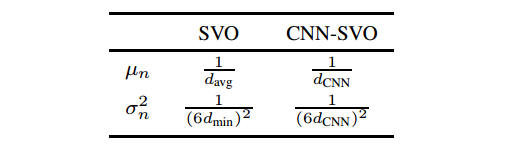
表1. SVO和CNN-SVO初始化参数的比较
主要结果
1、准确度分析
KITTI数据集:如图3所示为ORB-SLAM(无闭环检测),DSO和CNN-SVO,路径轨迹比较的定性分析。表2为关键帧轨迹的RMSE。
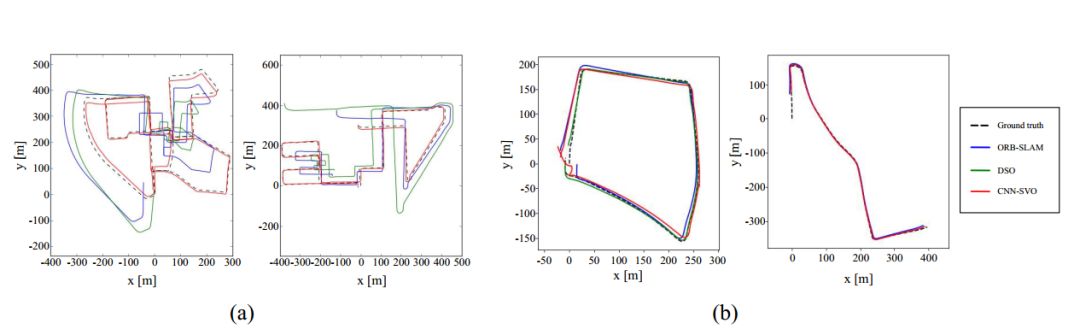
图3 KITTI-相机轨迹比较

表2. KITTI-RMSE比较
Oxford Robotcar 数据集:表3为关键帧轨迹的RMSE。
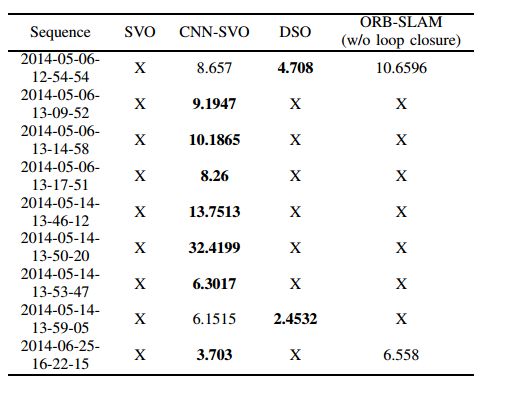
表3. Oxford Robotcar-RMSE比较
2、运行时间分析
CNN-VSO在KITTI上可以超过10FPS, Oxford Robotcar 数据集16FPS。对于更少的关键帧来说,可以达到实时的计算。
3、尺度漂移分析
如表4所示,为VO输出的尺度相对于绝对尺度的比率。
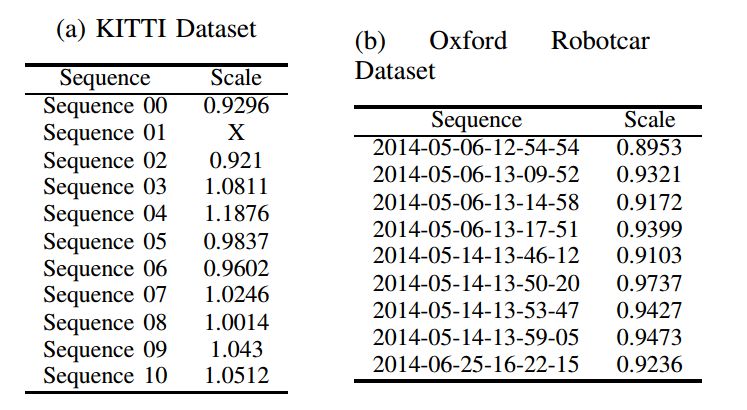
表4. VO输出的尺度相对于绝对尺度的比率
Abstract
Reliable feature correspondence between frames is a critical step in visual odometry (VO) and visual simultaneous localization and mapping (V-SLAM) algorithms. In comparison with existing VO and V-SLAM algorithms, semi-direct visual odometry (SVO) has two main advantages that lead to stateof-the-art frame rate camera motion estimation: direct pixel
correspondence and efficient implementation of probabilistic mapping method. This paper improves the SVO mapping by initializing the mean and the variance of the depth at a feature location according to the depth prediction from a singleimage depth prediction network. By significantly reducing the depth uncertainty of the initialized map point (i.e., small variance centred about the depth prediction), the benefits are twofold: reliable feature correspondence between views and fast
convergence to the true depth in order to create new map points. We evaluate our method with two outdoor datasets: KITTI dataset and Oxford Robotcar dataset. The experimental results indicate that the improved SVO mapping results in increased robustness and camera tracking accuracy.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



