

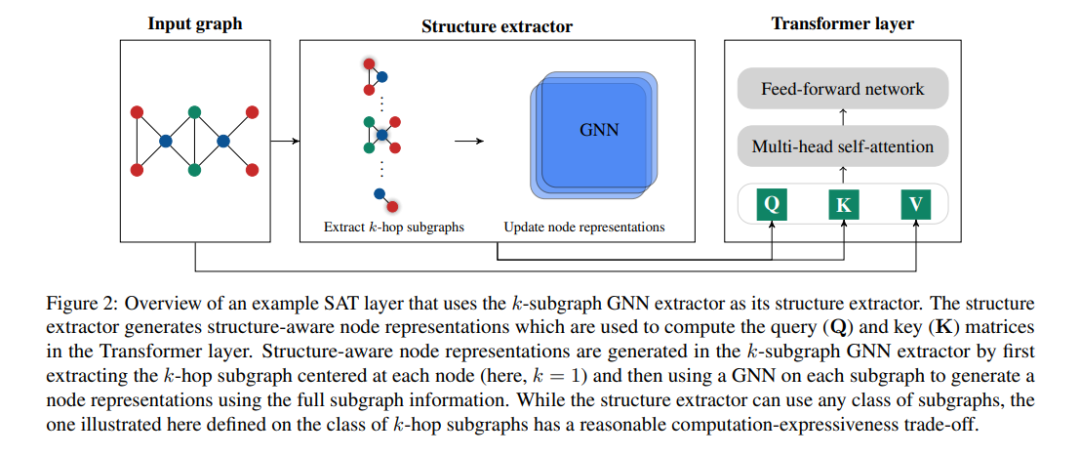
Transformer架构最近在图表示学习中获得了越来越多的关注,因为它通过避免图神经网络(GNN)的严格结构归纳偏差,而只通过位置编码对图结构进行编码,从而自然地克服了图神经网络(GNN)的一些限制。在这里,我们展示了使用位置编码的Transformer生成的节点表示不一定捕获它们之间的结构相似性。为了解决这个问题,我们提出了结构感知Transformer (Structure-Aware Transformer),这是一类建立在一种新的自注意力机制上的简单而灵活的图Transformer。这种新的自注意在计算自注意之前,通过提取基于每个节点的子图表示,将结构信息融入到原始自注意中。我们提出了几种自动生成子图表示的方法,并从理论上表明,生成的表示至少与子图表示一样具有表现力。从经验上讲,我们的方法在5个图预测基准上达到了最先进的性能。我们的结构感知框架可以利用任何现有的GNN来提取子图表示,我们表明,相对于基本GNN模型,它系统地提高了性能,成功地结合了GNN和transformer的优势。我们的代码可以在这个 https: //github.com/BorgwardtLab/SAT. 中找到。
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
相关主题


相关VIP内容
相关资讯
相关论文