

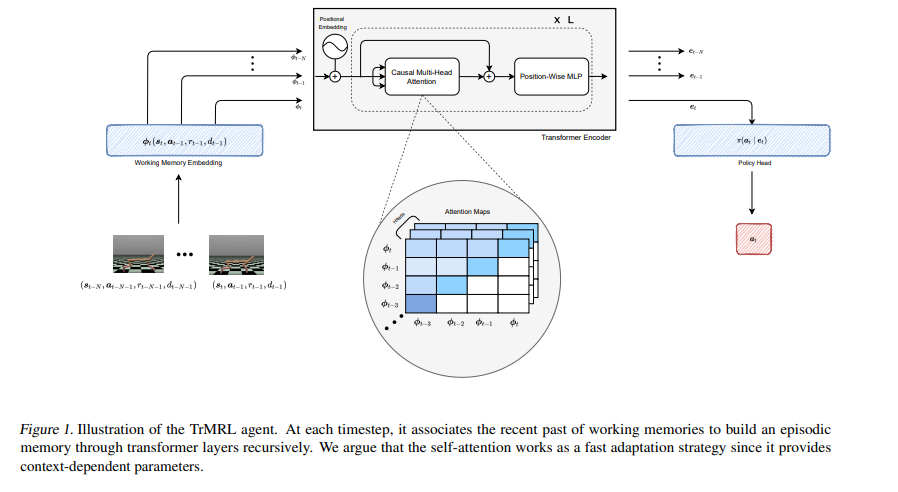
近年来,Transformer架构和变体在许多机器学习任务中取得了显著的成功。这种成功本质上与处理长序列的能力以及注意力机制中上下文相关的权重的存在有关。我们认为这些能力符合元强化学习算法的核心作用。事实上,元强化学习代理需要从一系列轨迹推断任务。此外,它需要一个快速适应策略来适应新的任务,这可以通过使用自我注意机制来实现。在这项工作中,我们提出了TrMRL(transformer 元强化学习),一个元强化学习l代理,模仿记忆恢复机制使用transformer 架构。它将最近过去的工作记忆联系起来,递归地通过transformer层建立情景记忆。我们展示了自注意力计算出一种共识表示,在每一层将贝叶斯风险降到最低,并提供了有意义的特征来计算最佳行动。我们在运动和灵巧操作的高维连续控制环境中进行了实验。结果表明,在这些环境中,与基线相比,TrMRL具有可比或更好的渐近性能、样本效率和分布外泛化。
https://www.zhuanzhi.ai/paper/1a6668cdd5003fa2b3f7803489661a0d
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
相关主题

相关VIP内容
相关资讯