

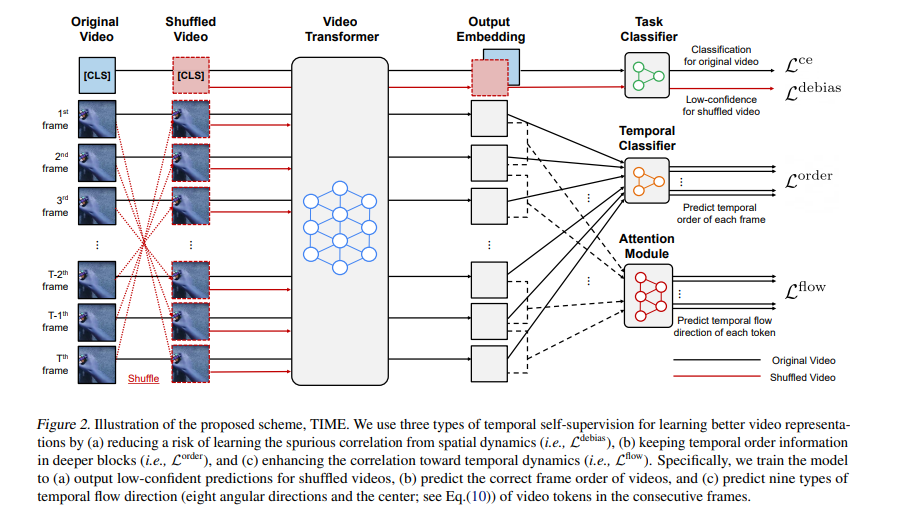
理解视频的时间动态是学习更好的视频表现的一个重要方面。最近,基于transformer的架构设计在视频任务中得到了广泛的探索,因为它们能够捕获输入序列的长期依赖性。然而,我们发现这些视频transformer在学习空间动力学而不是时间动力学时仍然是有偏的,去偏伪相关对它们的性能至关重要。基于观察结果,我们为视频模型设计了简单而有效的自监督任务,以更好地学习时间动态。具体来说,为了消除空间偏差,我们的方法学习视频帧的时间顺序作为额外的自监督,并强制随机洗牌的帧具有低置信输出。此外,我们的方法学习连续帧之间视频标记的时间流方向,以增强与时间动态的相关性。在各种视频动作识别任务下,我们证明了我们的方法的有效性,以及它与最先进的视频transformer的兼容性。
https://www.zhuanzhi.ai/paper/0a5edd1d139682ad788b64f4f65b968e

成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
0+阅读 · 2022年9月19日
Arxiv
0+阅读 · 2022年9月15日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月19日
Arxiv
0+阅读 · 2022年9月15日