超越Swin!MoA-Transformer:将全局特征聚合到视觉Transformer
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

Aggregating Global Features into Local Vision Transforme r
Local Transformer-based分类模型最近以相对较低的计算成本取得了较好的结果。然而,将全局空间信息聚合到Local Transformer-based架构的效果尚不清楚。本文主要研究了在Local window-based Transformer中应用Multi-Resolution Overlapped Attention(MOA) 的结果。MOA在key中使用了 slightly larger and overlapped patches来实现邻域像素信息的传输,从而获得了显著的性能增益。
此外,作者通过大量的实验深入研究了基本架构组件的维度的影响,并发现了一个最优的架构设计。大量的实验结果CIFAR-10、CIFAR-100和ImageNet-1K数据集表明,所提出的方法在相对较少的参数数量下优于以前的Vision Transformers。
1简介
基于Transformer的体系结构在自然语言处理(NLP)领域取得了巨大的成功。受Transformer在语言领域的巨大成功的启发,Vision Transformer被提出,并在ImageNet数据集上取得了优秀的性能。Vision Transformer就像NLP中的word token一样,将图像分割成patches并输入Transformer之中,并通过Transformer的几个multi-head self-attention层来建立远程依赖关系。
与word token不同,一个高分辨率的图像比段落中的单词包含更多的像素。这导致了计算成本的增加,因为Transformer中的 self-attention具有二次复杂度。为了缓解这一问题,人们提出了各种具有线性计算复杂度的Local Attention-based Transformers。然而,所有提出的方法都不能建模远距离依赖关系,同时其中一些方法非常复杂。
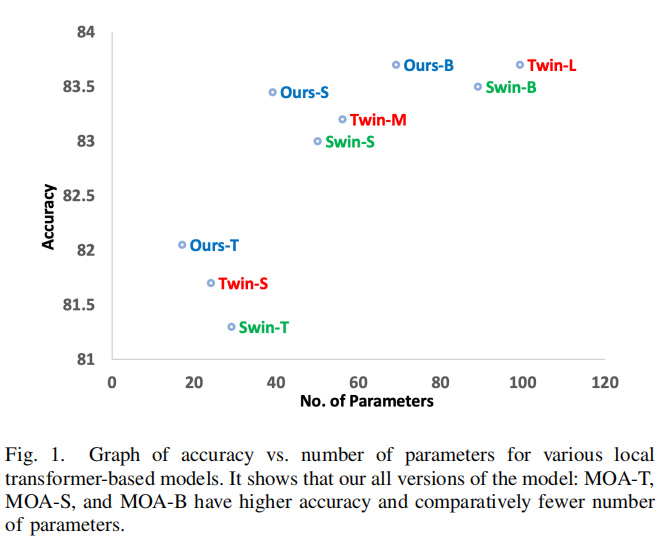
为了克服这些问题,作者开发了一个非常简单的模块,名为多分辨率重叠注意(MOA),以生成全局特征。该模块只包含乘法和加法运算,并在每个Stage后嵌入到下采样操作前的Transformer中。由于模块是在每一阶段后添加的,而不是在每一层Transformer后添加的,所以不会增加太多的计算量和参数数量。实验表明,将此模块的结果特征聚合到Local Transformer建立了长期依赖关系,因此与图1所示的参数总数相比,精度显著提高。
提出的MOA模块以基于局部窗口的注意力组生成的输出作为输入。它首先将其转换为一个二维特征图,并将其投影到一个新的低维特征图中。与ViT类似,投影的特征图被划分为固定数量的Patches。与ViT相比,query和key的patch size不同。query中的patches的分辨率与在Local Transformer层中使用的window size相同。相比之下,key patch的分辨率略大于query patch,且存在重叠。MOA全局注意力模块的隐藏维度与之前的Transformer层保持相同。因此,生成的特征被直接聚合到前一个Transformer层的输出中。
大量的实验表明,由于2个邻域window间的信息交换很小,因此保持key patches且相互重叠可以显著提高性能。
主要贡献
-
提出了一种多分辨率重叠注意(MOA)模块,该模块可以在Local Transformer的每个阶段后插入,以促进与附近windows和所有非局部windows的信息通信
-
利用所提出的MOA模块,深入研究了全局信息对Local Transformer的影响
-
通过大量的实验研究了基本架构组件的维度的影响,并发现了图像分类的最佳架构
-
在CIFAR-10/CIFAR-100和ImageNet-1K数据集上从头开始训练所提出的模型,并使用Local Transformer实现了最先进的精度
2相关工作
2.1 卷积神经网络
随着AlexNet的革命性提升,卷积神经网络(CNN)已经成为所有计算机视觉任务的标准网络,如图像分类、目标检测、目标跟踪、图像分割、目标计数和图像生成等。各种版本的CNN都已经被提出,通过使其更深入和/或更广泛来提高性能,如VGG网络、ResNet、Wide-ResNet、DenseNet等。通过修改单个卷积层,可以提高扩展卷积、深度可分离卷积、组卷积等方法的效率。
在本文的工作中,使用卷积层和Transformer层来减少特征映射的整体尺寸。实验表明,卷积和多头自注意力结合可以进一步提升性能。
2.2 CNN中的自注意力机制
Self-Attention在计算机视觉任务领域中已经无处不在。很多研究使用基于通道或基于位置的自注意力机制来增强卷积网络的性能。
Non-local网络和PSANet对Feature map中所有像素之间的空间关系进行建模,并在CNN中每个Block后嵌入注意力模块,而SENet则是通过全局平均池化对特征进行压缩,在卷积网络中建立通道关系。CBAM、BAM和Dual Attention网络分别采用基于通道和基于位置的注意力机制,然后将2个注意力模块的结果特征进行元素相加或拼接,并在每个阶段后将结果特征用于卷积输出。而GCNet将SENet和 Non-local网络结合在一起,提出了混合注意力机制,将通道和空间关系信息聚集在同一注意力模块中。
2.3 Vision Transformers
与AlexNet类似,Vision Transformer (ViT)改变了研究人员解决计算机视觉问题的视角。从那时起,许多基于Vision Transformer的网络被提出以提高精度或效率。但是ViT需要在大型数据集(如JFT300M)上进行预训练,才可以实现高性能。
-
DeiT通过模型蒸馏的方法、大量扩充和正则化技术解决了这一问题。
-
为了从零开始训练ImageNet-1K等中型数据集上的Transformer;Token-to-Token Vision Transformer递归地将邻近的Token(Patch)聚合为一个Token(Patch),以减少Token的数量;
-
Cross-ViT提出了一种多尺度patch size的双分支方法来产生较为鲁棒的图像特征;
-
Pyramid Vision Transformer(PVT)引入了一种类似于CNN中的FPN的基于多尺度的空间维度设计,并展示了良好的性能。此外,PVT引入了key的空间缩减,以降低多头注意力的计算成本。
各种基于局部注意力的Transformer被引入以缓解二次复杂度问题。HaloNet在局部注意力机制中引入了key window比query window稍大的思想,并通过各种实验证明了其有效性。在本文的模型中,key也是用一个稍大一点的patch来计算的,但在全局注意力的背景下,更大的key的想法与 HaloNet不同。Swin Transformer提出了一种非重叠的基于Window的局部自注意力机制,避免了二次复杂度,并提高了模型的性能。
一些基于局部或全局的Transformer工作已经被提出。Transformer in Transformer (TNT)进一步将局部patch划分为更小的patch。将visual words嵌入的MHA计算并聚合到句子嵌入中,建立全局关系。twin Transformer和本文完全一样。但是,由于每个局部Transformer层后都要进行全局注意力,大大增加了计算成本。相比之下,在每个阶段之后应用它,在多头注意力中有稍微大一点的、重叠的key patches。该网络有效地利用了局部Transformer的全局信息,并且比上述基于Transformer的模型具有更高的精度。
3本文方法
本文的目标是通过增加最小的计算成本和参数,在Local Transformer的所有Window中提供全局信息交换。图2显示了提出的模型的概述,其中显示了每个阶段后的MOA模块。各阶段结构设计相似,除第一阶段外,其余阶段均包括Patch Merge层和Local Transformer Block。第一阶段由Patch Partition、Linear Embedding Layer和Local Transformer Block组成。
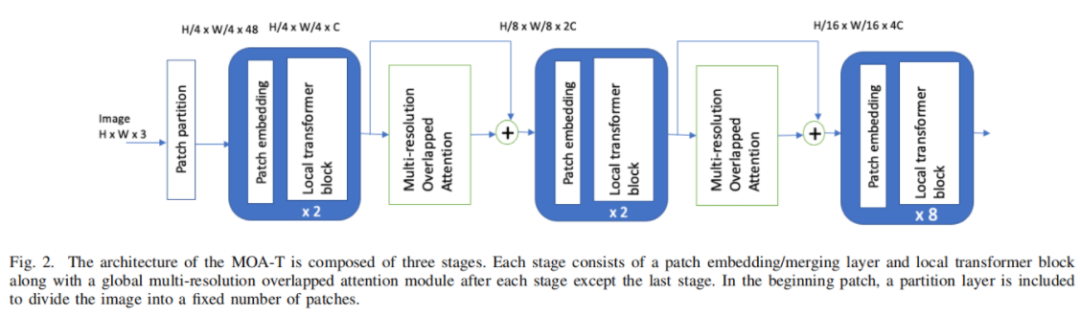
全局MOA模块在Patch Merge层之前的每个阶段之间应用。
具体来说,该模型将一个RGB图像作为输入,并将其分割为固定数量的Patches。在这里,每个Patches都被视为一个Patches。在对ImageNet数据集的实验中,将Patch size设置为4×4,这样每个Patch有4×4×3=48特征维度。
在第一阶段,使用 patch embedding layer将这些行特征投影到一个特定的维度C上。然后,所得到的特征通过连续的阶段,包括patch merging layer、local transformer block和每个阶段之间的MOA模块。与Swin Transformer不同,本文的Transformer Block采用了与ViT相同的自注意力机制,没有任何shifted window方法。
与Swin Transformer类似,在每个阶段结束后,在 patch embedding layer中,输出维数增加了一倍。例如,第一、第二、第三阶段后的分辨率分别为H/2×W/2、H/4×W/4和H/8×W/8。在最后一个阶段结束时插入平均池化层,然后插入一个线性层来生成一个分类分数。
详细说明如下:
1、Patch Embedding Layer
它是一个基本的线性嵌入层,应用于patch的行特征上,将其投影到特定维C上。
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# 直接进行映射
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
2、Patch merging layer
Patch merge层通过拼接2×2个相邻Patch的特征来减少token的数量,并在拼接的4C维特征上应用线性层使隐藏层的维数翻倍。

# 与SWin-Transformer相同的操作
class PatchMerging(nn.Module):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
x = x.view(B, H, W, C)
# 在行和列方向上间隔2选取元素
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
# 拼接到一起作为一整个张量
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
# 展开
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
# 此时通道位数会变成原来的4倍(保持总的不变),此时在通过一个全连接层再调整通道维度为原来的2倍。
x = self.norm(x)
x = self.reduction(x)
return x
3、Local Transformer Block
Local Transformer Block由基于局部窗口的标准多头注意模块和具有GELU非线性的两层MLP组成。在每个多头注意力模块前使用一个层归一化操作,在每个MLP层都进行残差连接。
class LocalTransformerBlock(nn.Module):
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.window_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# 主要是进行Window Attention操作
x_windows = window_partition(x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = x.view(B, H * W, C)
# 残差连接
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
4、多分辨率重叠的注意力
为了充分利用Local Transformer全局信息的优势,在各阶段之间引入了多分辨率重叠注意力(MOA)全局注意力模块。MOA机制除了一些修改,其他的架构与标准的多头注意力相同。与标准MHA类似,它首先将Feature map划分为固定大小的patch。但是,与标准MHA不同的是,用于生成key和value嵌入的patch稍大一些,并且有重叠,而用于query嵌入的patch则没有重叠,如图3所示。
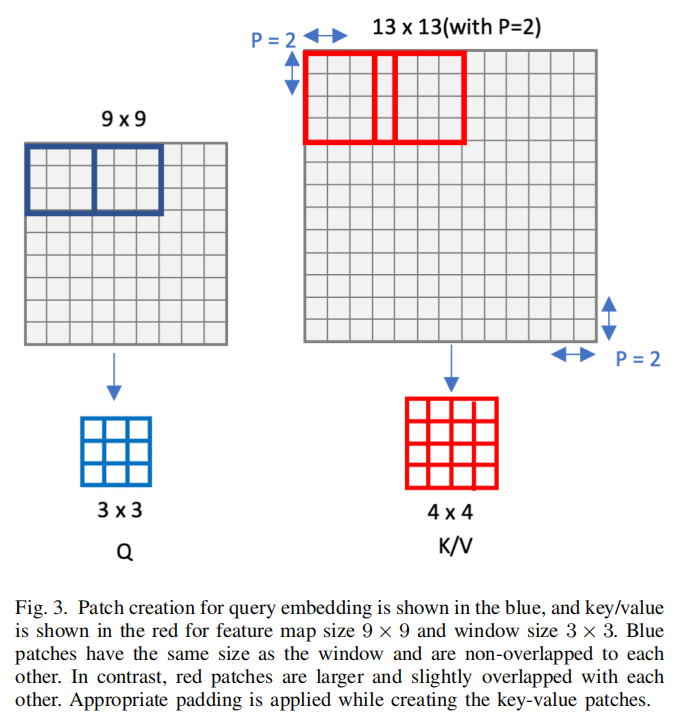
如图3所示,MOA块的输入大小为W×H×隐藏层维度,其中W=W/2、W/4或W/8,H=H/2、H/4或H/8,隐藏层维度=96、192或384。直接从输入计算query、key和value嵌入的计算是相当昂贵的。例如,在与ImageNet数据集的上下文中,第一阶段之后向MOA块输入的特征映射大小为56×56×96。直接从Patch size=14的输入特征派生query嵌入,将得到维度为14×14×96=18816的特征。
因此,首先利用1×1卷积来减少具有因子R的隐藏层维数,从而降低了计算成本。应用卷积后的特征维数为H×W×hiddendim/R。在一个query patch中特征大小为14×14×R被投影到一维向量的大小1×1×R。query的总数为H/14×W/14。类似地,投影key和value向量,但patch size略大于query,如图3所示。
在模型中,将key和value的 patch size设置为16。因此,key和value的数量将根据公式:。对query、key和value嵌入进行多头注意力,然后是中间具有GELU非线性的两层MLP。与Transformer block类似,在每个MOA模块之后应用LN层和残差连接。最后,对合成的特征进行1×1卷积,然后将合成的特征与前一个Transformer block的输出进行广播相加,这样其中则包含了局部信息。
class GlobalAttention(nn.Module):
r""" MOA - multi-head self attention (W-MSA) module with relative position bias.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, input_resolution,num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size[0]
self.key_size = self.window_size[0] + 2
h,w = input_resolution
self.seq_len = h//self.query_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.reduction = 32
self.pre_conv = nn.Conv2d(dim, int(dim//self.reduction), 1)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * self.seq_len - 1) * (2 * self.seq_len - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
#print(self.relative_position_bias_table.shape)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.seq_len)
coords_w = torch.arange(self.seq_len)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.seq_len - 1 # shift to start from 0
relative_coords[:, :, 1] += self.seq_len - 1
relative_coords[:, :, 0] *= 2 * self.seq_len - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.queryembedding = Rearrange('b c (h p1) (w p2) -> b (p1 p2 c) h w', p1 = self.query_size, p2 = self. query_size)
self.keyembedding = nn.Unfold(kernel_size=(self.key_size, self.key_size), stride = 14, padding=1)
self.query_dim = int(dim//self.reduction) * self.query_size * self.query_size
self.key_dim = int(dim//self.reduction) * self.key_size * self.key_size
self.q = nn.Linear(self.query_dim, self.dim,bias=qkv_bias)
self.kv = nn.Linear(self.key_dim, 2*self.dim,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
#trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, H, W):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
#B, H, W, C = x.shape
B,_, C = x.shape
x = x.reshape(-1, C, H, W)
x = self.pre_conv(x)
query = self.queryembedding(x).view(B,-1,self.query_dim)
query = self.q(query)
B,N,C = query.size()
q = query.reshape(B,N,self.num_heads, C//self.num_heads).permute(0,2,1,3)
key = self.keyembedding(x).view(B,-1,self.key_dim)
kv = self.kv(key).reshape(B,N,2,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
k = kv[0]
v = kv[1]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.seq_len * self.seq_len, self.seq_len * self.seq_len, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
5、相对位置索引
在相似性计算过程中,使用了相对位置偏差 :
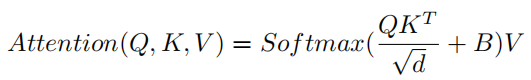
其中 为query矩阵, 为key、value矩阵;d为隐藏层维数, 为队列中patch总数, 为key中patch总数。
query_size = window_size[0]
h,w = input_resolution
seq_len = h//query_size
relative_position_bias_table = nn.Parameter(torch.zeros((2 * seq_len - 1) * (2 * seq_len - 1), num_heads))
coords_h = torch.arange(seq_len)
coords_w = torch.arange(seq_len)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += seq_len - 1 # shift to start from 0
relative_coords[:, :, 1] += seq_len - 1
relative_coords[:, :, 0] *= 2 * seq_len - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_bias = relative_position_bias_table[relative_position_index.view(-1)].view(seq_len * seq_len, seq_len * seq_len, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = softmax(attn)
attn = attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = proj(x)
x = proj_drop(x)
6、Architecture详细配置
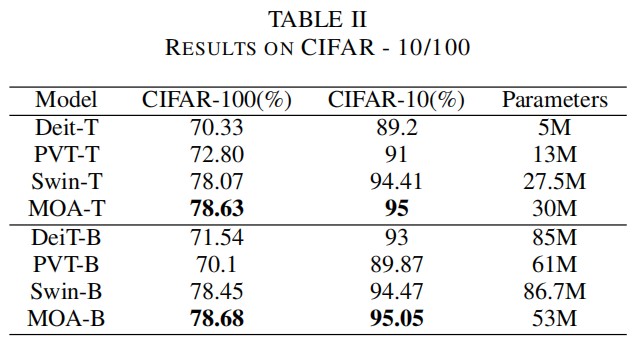
根据之前的工作,为ImageNet数据集构建了3个版本的模型:MOA-T、MOA-S和MOA-B,而为CIFAR -10/100数据集构建了2个版本的模型:MOAT和MOA-B,因为它非常小。
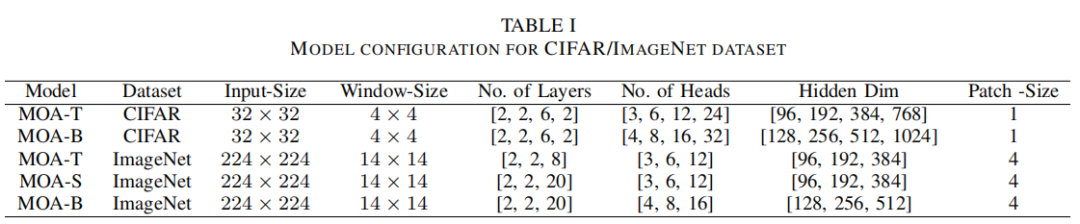
表1显示了CIFAR和ImageNet数据集的架构配置。在基于CIFAR的模型中,MOA-T和MOA-B包含相同数量的Transformer层:12层,但隐藏层维数不同。在基于ImageNet的模型中,MOA-T和MOA-S的总层数分别为12层和24层,但隐藏层保持不变,而MOA-S和MOA-B的Transformer层数相同:24层,对比隐藏层分别为96层和124层。
4实验
4.1 消融实验
1、Window size
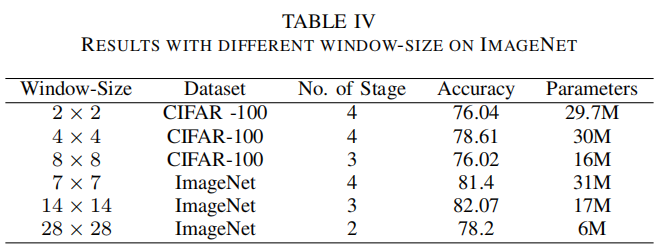
Local-Transformer的序列长度是影响计算成本的重要因素之一。随着序列长度的增加,自注意力机制的计算量也随之增加。在局部可视化Transformer中,序列长度取决于Window-size。在计算精度和计算成本之间总是要根据序列长度进行权衡。
作者在模型中实验各种window size,发现4 x4和14 x14 window size适用cifar-100和ImageNet数据集,分别如表4所示。此外,删除window size大于的阶段特征图大小显著降低参数的数量。
2、Overlapped Portion
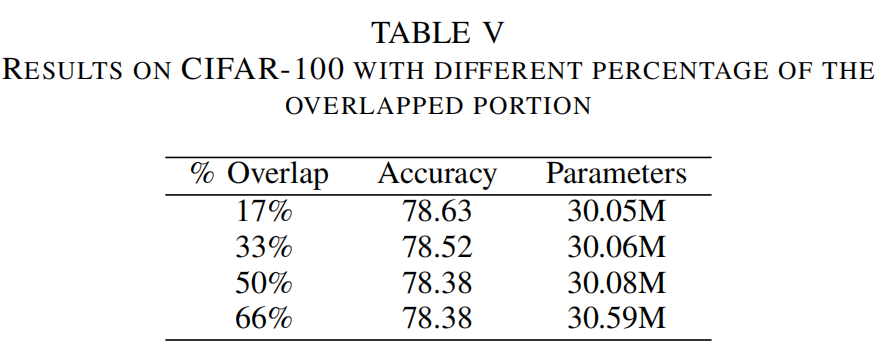
为了邻域信息传输,建议使用稍大且重叠的key。为了考察重叠区域的影响,作者用不同比例的key进行实验,如表5所示。从结果可以看出,随着比例的降低,在准确率方面的性能有所提高,这意味着在相邻的Windows之间只需要少量的信息交换就可以提高性能。此外,更少的重叠部分减小了序列长度,从而减少了参数和GFLOPs的数量。
3、Reduction
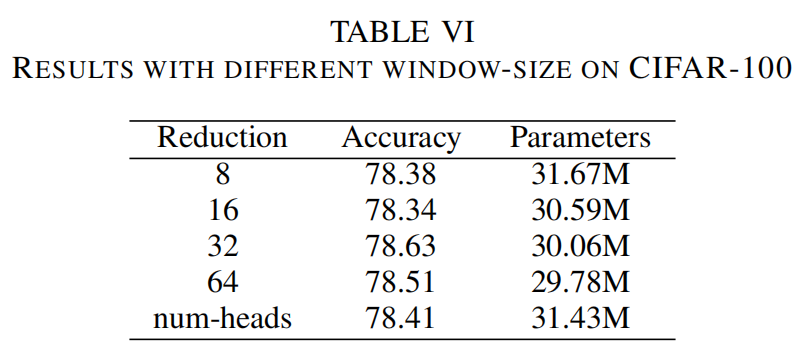
在MOA全局注意力之前,通过降低隐藏层维数来降低参数数量和计算成本。表VI显示了模型在不同R值下的性能。从结果中可以看出,与R值较小的情况相比,R=32的参数数量和计算代价相对较少,得到的结果最好。
4、 Overlapped Key-Value的影响
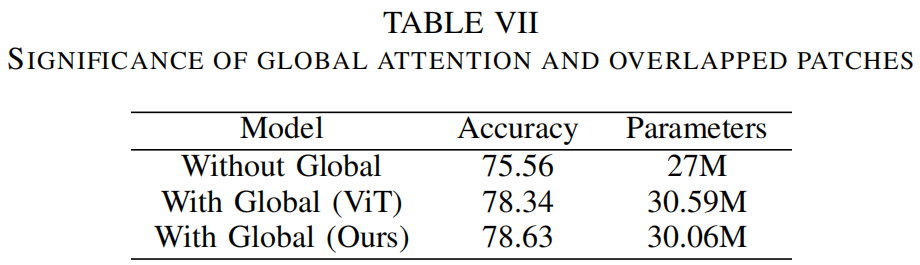
为了验证重叠和较大的key-value patches的效果,作者对没有重叠patches的模型进行训练并比较结果。此外,还进行了一个实验,在每个阶段之间不使用全局注意力来验证全局信息交换的意义。从表7的结果可以看出,包含全局注意力和重叠key-value patches的效果最好。
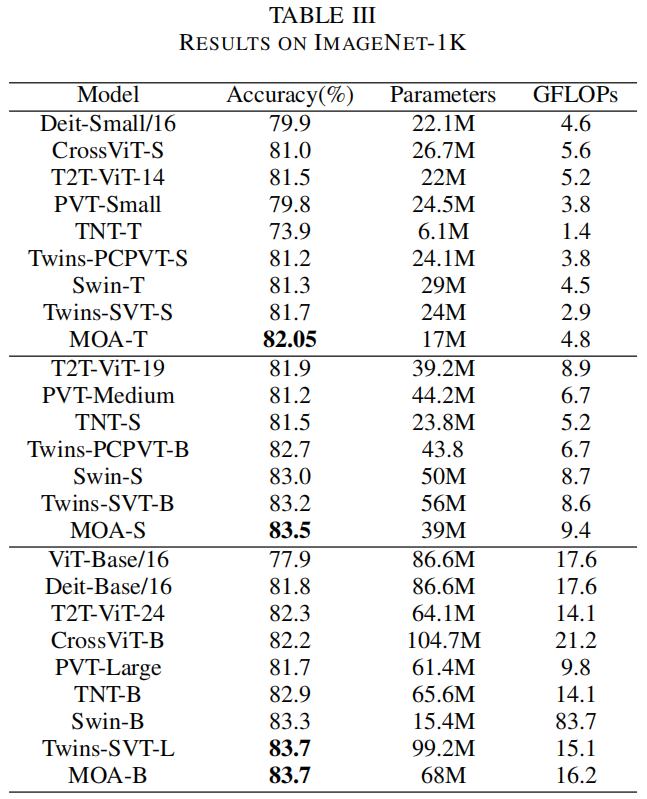
4.2 SOTA效果
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号





