【华为诺亚新论文】基于图上下文知识融入的预训练语言模型
知识图谱中的复杂节点交互是常见的,这些交互也包含了丰富的知识信息。然而,传统的方法在知识表示学习过程中往往将三元组作为一个训练单元,而忽略了知识图谱中节点的上下文化的信息。我们将建模对象推广到一个非常一般的形式,该形式理论上支持从知识图谱中提取的任何子图,并将这些子图输入到一个新的基于Transformer的模型中学习知识嵌入。为了扩展知识的使用场景,我们通过预训练好的语言模型来建立一个包含了学习的知识表示的模型。实验结果表明,此模型在多种医学自然语言处理任务中取得了较好的效果,并通过对传统方法的改进,证明了该方法能有效地捕获图上下文信息。


介绍

提出了一种能够对任意子图进行建模的知识表示学习方法。该方法极大地丰富了知识表示中的信息量,探索了实体和关系的联合学习。
图上下文化的知识被整合到一起来提高预训练的语言模型的性能,这些模型在医学领域的几个NLP任务上比最先进的模型表现得更好。
方法
在我们的模型中,每次从知识图谱中选择一定数量的节点及其连接的节点,构建一个训练样本。然后,利用一种新的基于Transformer的知识表示学习算法,从相邻节点处学习节点的嵌入。最后,将学习到的知识表示集成到语言模型中,增强模型的预训练和微调的效果。
1
Transformer学习KG嵌入
Transformer可以作为一个强大的编码器对序列输入进行建模。最近,Koncel-Kedziorski等人(2019)将Transformer扩展为对图结构输入进行编码。在他们的工作中,首先将文本转换为图,然后由图Transformer对其进行编码并输入文本生成模型。受他们工作的启发,我们将知识子图转换为节点序列,并利用基于Transformer的模型学习节点嵌入。我们称这个模型为KG- Transformer,其中KG表示知识图谱)。下面将详细描述该方法。
2
图变换
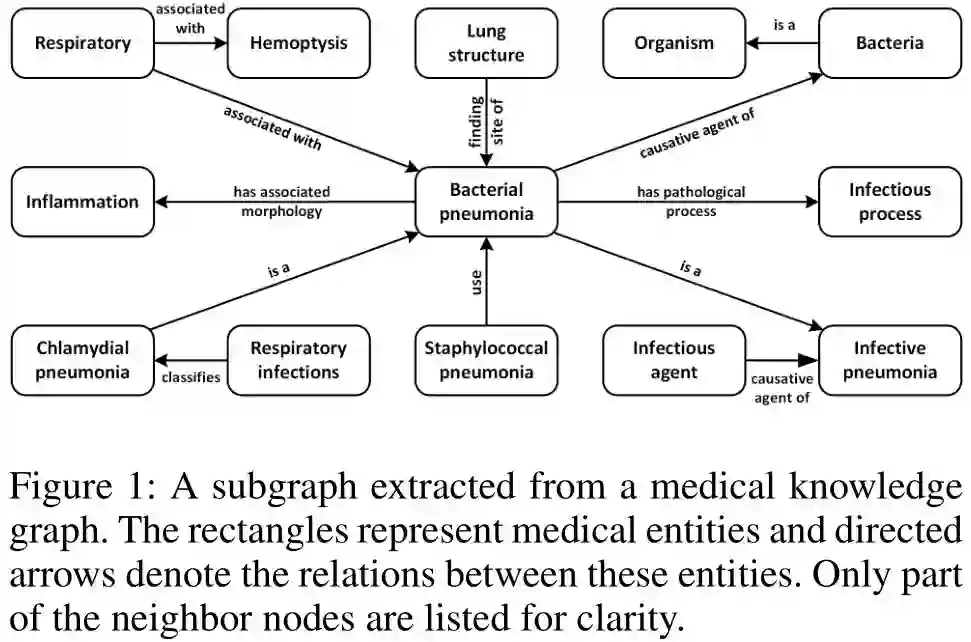
我们表示知识图谱G = (E, R), 其中E代表实体集合,R是G中的实体对之间的关系集合。G中的三元组可以表示为t=(es,r,eo) , 其中es是一个头实体,eo是尾实体,r是es,eo之间的关系。图1给出了医疗KG的子图示例。两个实体(矩形)和它们之间的关系(箭头)构成一个知识三元组,例如,
(Bacterial pneumonia, causative agent of, Bacteria)。
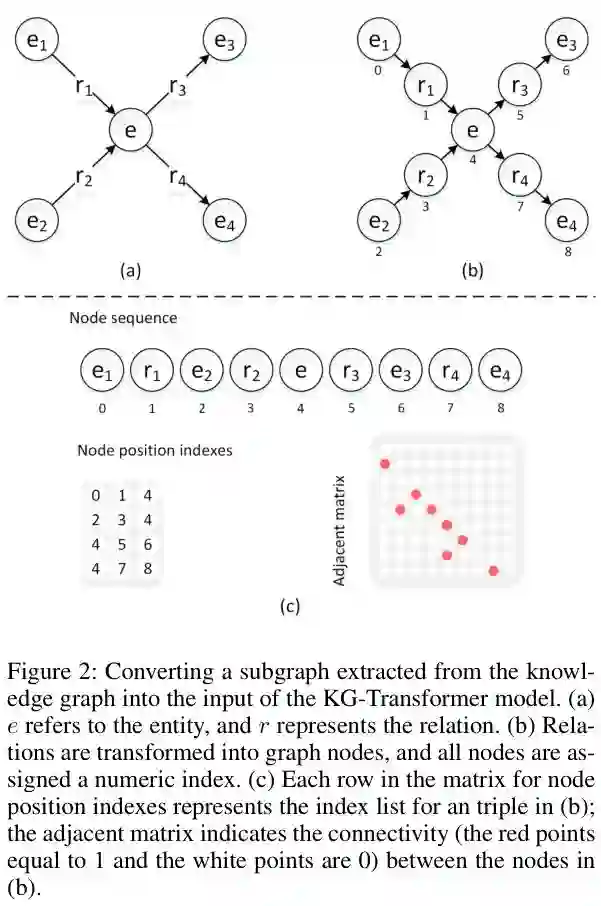
传统的KRL方法(如TransE (Bordes et al. 2013)和ConvKB (Nguyen et al. 2018))将单个三元组作为训练样本。但是在此设置中,实体邻居的信息不能同时更新实体的嵌入。图注意网络(GATs)(Veliˇckovi´c et al. 2018)的提出解决了这个问题。Nathani等人(2019)利用GAT进行构建一个KRL模型,其中所有指向尾实体的头实体都被用来学习尾实体的嵌入。在我们的工作中,我们提出了一种更通用的方法,将KG的任何子图作为训练样本,它极大地丰富了在学习知识表示中的上下文的信息。为了便于说明,在图2(a)中,我们选择一个实体及其两个in-entities和 out-entities来构建一个训练样本。
此外,我们还将KG中的关系作为与模型中的实体等价的节点进行学习,实现了实体嵌入和关系嵌入的联合训练。节点转换过程如图2(b)所示。将知识图谱重新定义为G = (V,E),其中V表示G中的节点,涉及E中的实体和R中的关系,E表示V中节点间有向边的邻接矩阵。图2(c)中的邻接矩阵展示了图2(b)中节点之间的连通性。
子图的转换结果如图2(c)所示,包括节点序列、节点位置索引矩阵和邻接矩阵。节点位置索引矩阵的每一行对应于图中的一个三元组。例如,三元组(e1,r1,e)表示为矩阵中的第一行(0,1,4)。在邻接矩阵中,如果图2(b)中的节点i与节点j相连,则元素aij = 1,否则为0。
3
基于Transformer的编码器
我们将节点序列表示为{x1,…,xN},其中N为输入序列的长度。定义了一个节点位置索引矩阵和一个邻接矩阵,分别为P和A。实体嵌入和关系嵌入集成在一个矩阵V中,V∈R(nr+ne)xd其中ne是E中的实体编号,nr是R中的关系类型编号。在嵌入矩阵V中可以查找节点序列{x1,…,xN}可以生成节点嵌入信息X={x1,…,xN}。X, P和A构成KRL模型的输入,如图3所示。
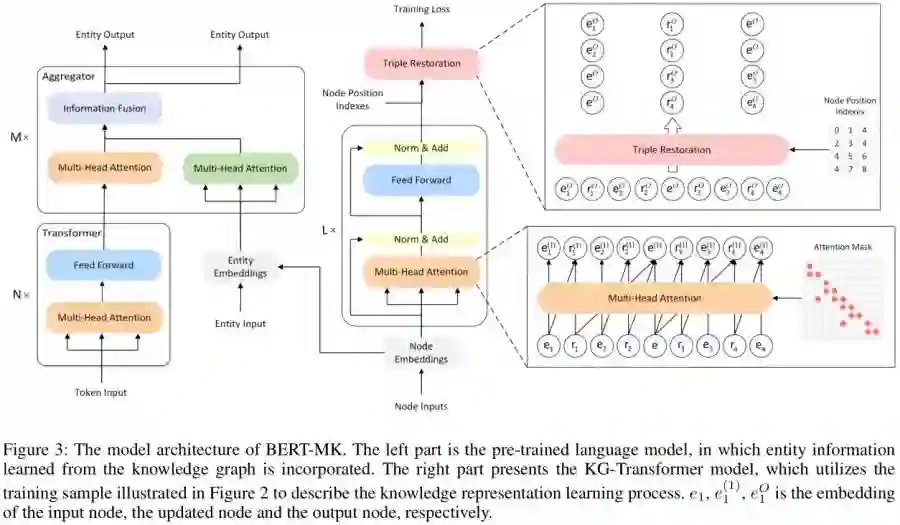
将输入输进到基于Transformer的模型中,对节点信息进行编码。
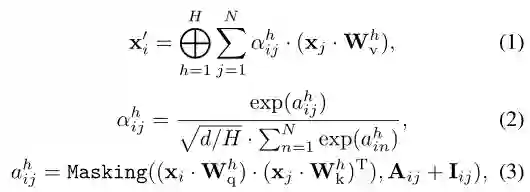
其中xi'是节点xi的新嵌入。⊕表示该层中H个注意头的连接,αijh和Wvh为节点xj的注意权值,将节点xj分别嵌入第h个注意头的线性变换。方程3中的掩码函数限制了输入节点之间的上下文的依赖关系,只涉及到 degree-in节点和当前节点本身来更新节点嵌入。类似于Wvh ,Wqh 和Wkh是节点嵌入的独立线性变换。然后,将新的节点嵌入信息输入到前馈层进行进一步编码。
和Transformer模型中一样,我们将上述Transformer块堆叠了L次。基于Transformer的编码器的输出为:
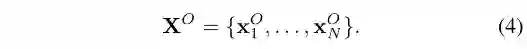
4
训练目标
利用编码器XO的输出和节点位置索引P来还原三元组并生成三元组的嵌入:
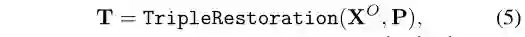
其中Tk=(xesk,xrk,xeok),Pk=(esk,rk,eok)是有效知识三元组的位置索引。
本研究采用基于翻译的评分函数(Han et al. 2018)测量知识三元组的能量。通过最小化margin-based的训练数据损失函数来学习节点嵌入:
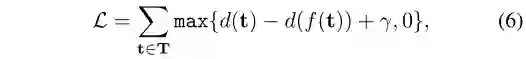
其中t=(ts,tr,to),d(t)=|ts+tr-to|,γ>0是一个间隔(margin)超参数,f(t)是一个实体替换操作函数,该操作替换了一个三元组中的头实体或尾实体,而被替换的三元组则成了在KG中是无效的三元组。
5
知识融入语言模型
对于给定的一个综合的医学知识图谱,首先利用KG-Transformer模型可以学习图的上下文化知识表示。我们遵循(Zhang et al. 2019)提出的语言模型架构,利用图上下文化知识增强医学语言表征。语言模型的预训练过程如图3的左侧部分所示。Transformer块编码单词上下文化表示,aggregator块实现知识和语言信息的融合。
根据医学自然语言处理任务的特点,设计了面向领域的细化流程。与BioBERT (Lee et al. 2019)类似,符号@和$用于标记实体边界,表示样本中的实体位置,并区分共享同一语句的不同关系样本。例如,关系分类任务的输入序列可以修改为 “[CLS] pain control was initiated with morphine but was then changed to @ demerol $, which gave the patient better relief of @ his epigastric pain $”。提及的实体及其上下文对于预测实体类型至关重要,因此提及的实体的更多局部化特征将有利于预测过程。在我们的实验中,选择实体开始标记@来表示实体类型示例。
实验
1
数据集-医学知识图谱
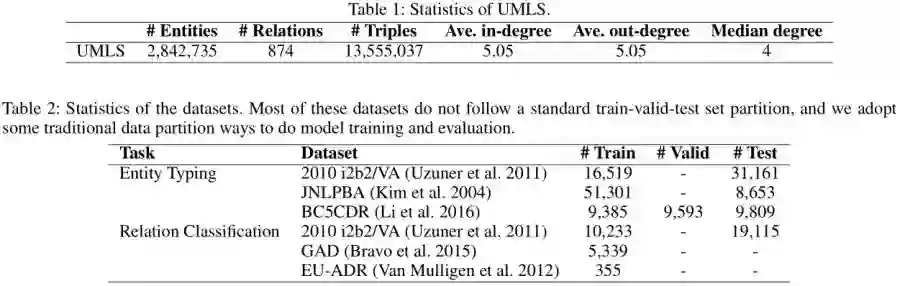
统一医学语言系统(UMLS) (Bodenreider 2004)是生物医学领域的一个综合性知识库,包含大规模的概念名称和它们之间的关系。UMLS中的元词表涉及各种术语系统,包含约1400万个术语,涵盖25种不同的语言。在本研究中,我们提取了该知识库的一个子集来构建KRL的医学知识图谱。对非英语词汇和长词汇进行筛选,最终统计结果如表1所示。
2
预训练语料
为了保证充分的医学知识能够被整合到语言模型中,我们选择PubMed摘要和PubMed中心全文论文作为训练前的语料库,这两个语料库是生物医学和生命科学期刊文献的开放获取数据集。由于不同段落中的句子可能没有很好的上下文连贯性,所以选择段落作为下一个句子预测的文档单元。自然语言工具包(NLTK)被用来在一个段落中拆分句子,并且对少于5个单词的句子进行分解。从而实现了一个包含9.9B大小的tokens的大型语料库,用于语言模型的预训练。
在我们的模型中,医学术语出现在语料库中是需要的在预训练与UMLS元词表库中的实体对齐。为了确保元词表库中已识别实体的覆盖率,使用前向最大匹配(FMM)算法从前面提到的语料库中提取词汇跨度,并过滤跨度小于5个字符的词汇。然后,使用BERT词汇表将输入文本标记为单词片段,并将医疗实体与识别的术语的第一个子单词对齐。
下游任务
在本研究中,我们使用医学领域的实体类型化和关系分类任务来评估这些模型。
1
实体类型化
对于标记了提及实体的句子,实体类型化的任务是识别该实体的语义类型。例如,医疗问题类型常用于标记句子中提到的实体,“he had a differential diagnosis of <e> asystole </e>”。据我们所知,在医学领域没有公开的实体类型化数据集,因此,从相应的医学命名实体识别数据集构造了三个实体类型化数据集。在这些数据集中,实体和实体类型被标注,在本研究中,输入是实体,而输出标签是实体类型。表2显示了实体类型任务的数据集统计信息。
2
关系分类
给定一个句子中的两个实体,任务目标是确定实体之间的关系类型。例如,在句子“pain control was initiated with morphine but was then changed to,demerol </e1>, which gave the patient better relief of <e2>his epigastric pain </e2>”,两个实体之间的关系类型是 TrIP(治疗改善医疗问题)。在本研究中,我们使用三个关系分类数据集来评估我们的模型,这些数据集的统计数据如表2所示。
实现细节
1
知识表示学习
为了实现一个基本的知识表示,UMLS三元组被输入到TransE模型中。采用OpenKE toolkit (Han et al. 2018)对实体和关系嵌入进行训练,嵌入维数设置为100,训练epoch数设置为10000。
遵循(Nguyen et al. 2018;使用TransE生成的嵌入来初始化KG-Transformer模型的表示学习。层数和隐藏头数都设置为4。由于UMLS中节点的中位数为4(如表1所示),因此将一个具有两个in-nodes和两个out-nodes的节点作为训练实例进行采样。KG-Transformer模型在单台NVIDIA Tesla V100 (32GB) GPU上运行1200 epoch来训练知识嵌入,批量大小50000。
2
预训练
首先,医学ERNIE (MedERNIE)模型在UMLS三元组和PubMed语料库上进行训练,使用与之相同的模型超参数(Zhang et al. 2019)。另外,KG-Transformer模型学习到的实体嵌入被集成到语言模型中,以训练BERT-MK模型。在我们的工作中,我们采用BioBERT相同的预训练且我们的预训练语料库一样,并对PubMed语料库上的BERT-Base模型进行了微调。
3
微调
由于在某些数据集中没有标准的 development集,我们将训练集按照4:1进行划分为一个新的训练集和一个 development集。对于包含标准测试集的数据集,我们使用不同的随机种子在特定的实验设置下对每个实验进行五次预处理,并使用平均结果来提高评价的可靠性。此外,10折交叉验证方法是用来评估模型数据集没有一个标准的测试集的性能。根据最大序列长度的句子在每个数据集,输入序列长度为2010 i2b2 / VA (Uzuner et al . 2011), JNLPBA (Kim et al . 2004), BC5CDR(李et al . 2016),广泛性焦虑症(布拉沃et al . 2015年)和EU-ADR (Van Mulligen et al . 2012年)分别设置为390,280,280,130和220。初始学习速率设置为2e-5。
4
Baseline
Baseline除了这些数据集上最先进的模型,我们还添加了流行的BERT-Base模型和另外两个在生物医学文献上预训练的模型,以便进一步比较。
BERT-Base (Devlin et al. 2019) :这是由谷歌提出的原始的双向预训练语言模型,它在广泛的NLP任务中实现了最先进的性能。
BioBERT (Lee et al. 2019)此模型遵循与BERT-Base模型相同的模型体系结构,但是使用了PubMed摘要和PubMedCentral全文文章(大约18Btokens)来对BERT-Base进行模型微调。
SCIBERT (Beltagy, Cohan, and Lo 2019)一个新的单词块词汇表是基于一个大型的科学语料库(大约3.2亿个标记)构建的。然后,使用新的科学词汇和科学语料库从零开始训练一个新的基于bert的模型。由于科学语料库中有很大一部分是生物医学文章,所以该科学词汇也可以看作是生物医学词汇,可以有效地提高生物医学领域下游任务的表现。
实验结果
表3给出了实体类型和关系分类任务的实验结果。对于实体类型的任务,所有这些预训练的语言模型都达到了较高的准确性,这表明医疗实体的类型不像一般领域那样模糊。mk的平均准确率分别比BERT-Base、BioBERT和SCIBERT高出0.71%、0.24%和0.02%。在没有使用预训练的语言模型中的外部知识的情况下,SCIBERT获得了与BERT-MK类似的结果,这证明了特定于域的词汇对于输入的特征编码是至关重要的。长标记在医学领域中比较常见,当使用领域独立的词汇表时,这些标记会被分割成短块,这将导致词汇特征的泛化。因此,在接下来的工作中,可以将PubMed语料库生成的医学词汇引入BERT-MK。
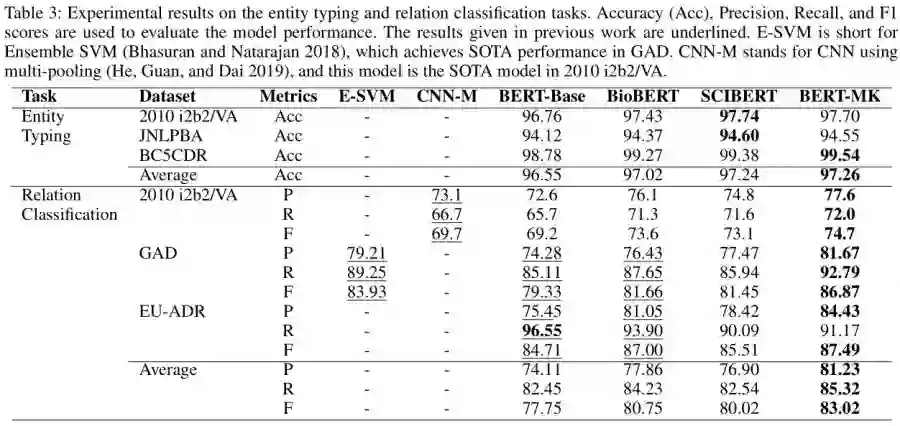
在关系分类任务上,BERT-Base的表现不如其他模型,这说明在受限领域使用预训练好的语言模型需要一个域适应过程。与BioBERT利用与我们相同的领域特异性语料库对预训练好的语言模型进行领域适应相比,BERT-MK的平均F分数提高了2.27%,这表明医学知识确实在医学关系的识别中起到了积极的作用。下面的例子简要解释了为什么医学知识提高了关系分类任务的模型性能。“On postoperative day number three , patient went into <e1> atrial fibrillation</e1> , which was treated appropriately with <e2>metoprolol </e2>and digoxin and converted back to sinus rhythm”是来自2010年i2b2/VA数据集的关系示例,和关系标签是TrIP。同时,上述实体对可以在医学知识图谱中与一个知识三元组 (atrial fibrillation, may be treated by,metoprolol)对齐。显然,这些知识信息有利于上述例子的关系描述。
1
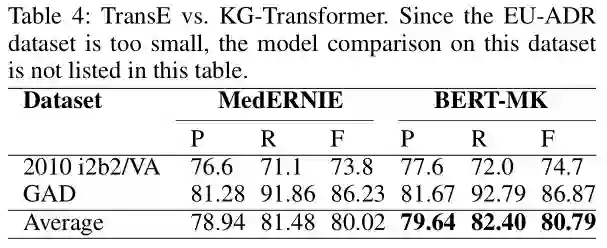
TransE VS. Transformer
为了对我们的新KRL方法进行更直观的分析,我们对两个关系分类数据集上的MedERNIE (TransE用于学习知识表示)和BERT-MK(对应KG-Transformer)进行了比较。表4展示了这两个模型的结果。从图中可以看出,将KG-Transformer模型学习到的知识信息进行整合,在两个关系分类数据集上,其在F分数性能分别提高了0.9%和0.64%,这说明知识质量的提高对预训练好的语言模型是有好处的。
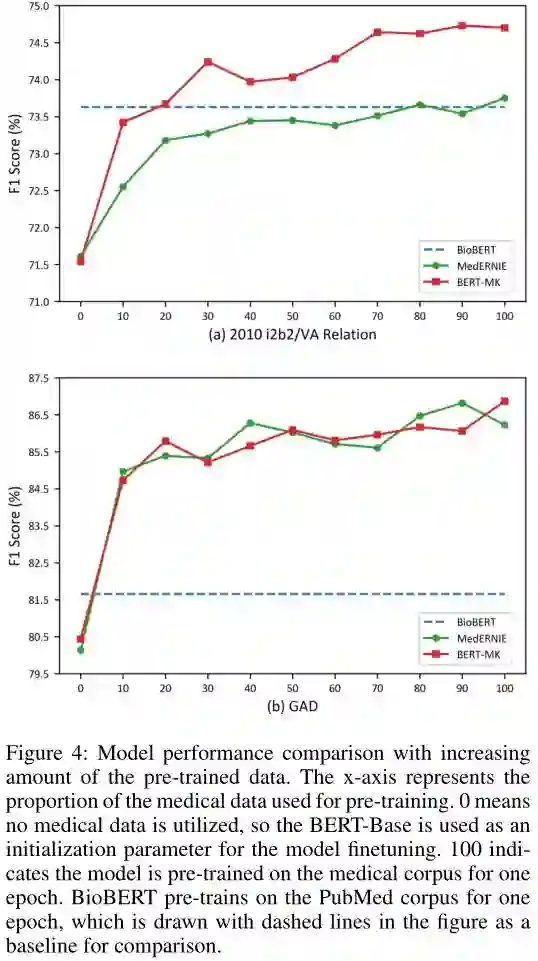
在图4中,随着训练前数据量的增加,BERT-MK在2010 i2b2/VA关系数据集上的表现总是优于MedERNIE,并且表现差距有增大的趋势。但是,在GAD数据集上,BERT-MK和MedERNIE的性能是相互交织的。我们将关系样本中的实体链接到知识图谱中,并对链接节点之间的关系进行统计分析。我们观察到2010年i2b2/VA有136个2- hop邻居关系,而广泛性焦虑症只有1个。表5中所示的第二种情况是上述情况的一个例子。在医学知识图谱中发现三组(CAD, member of, Other ischemic heart disease (SMQ))和(Other ischemic heart disease (SMQ), has member, Angina symptoms),表明实体CAD与实体心绞痛症状存在2跳邻居关系。KG-Transformer在2010年i2b2/VA中学习了这些2跳邻居关系,并对BERT-MK进行了改进。但是,由于GAD数据集的特点,KG-Transformer的能力是有限的。
2
语料大小对预训练模型的影响
图4为预训练语料库不同方案下的模型性能对比。从这个图中,我们观察到BERT-MK只使用了10%- 20%的语料库,从而优于BioBERT,这表明医学知识有能力增强预训练好的语言模型并节省计算成本(Schwartz et al. 2019)。
相关工作
以ELMO (Peters et al. 2018)、GPT (Radford et al. 2018)和BERT (Devlin et al. 2019)为代表的预训练语言模型受到了极大的关注,并提出了大量的变体模型。在这些研究中,一些研究者致力于将知识引入到语言模型中,如ERNIE-Baidu(Sun et al. 2019)和ERNIE-Tsinghua(Zhang et al. 2019)。百度推出了新的掩码单元,如短语和实体学习知识信息在这些掩码单元。作为奖励,来自短语和实体的语法和语义信息被隐式地集成到语言模型中。在此基础上,研究了一种不同的知识信息,将知识图谱融合到BERT中,同时学习词汇、句法和知识信息。然而,知识图谱中节点间的信息交互受到ERNIE-Tsinghua所使用的KRL方法的限制是知识质量的关键。
最近,提出了几种基于神经网络的KRL方法,大致可分为基于卷积神经网络(convolutional neural network, CNN)的方法(Dettmers et al.2018; Nguyen et al. 2018) 以及基于图神经网络(GNN)的模型(Schlichtkrull等,2018;Nathani et al,2019年)。基于CNN的模型增强了三元组内的信息交互,但将三元组作为训练单元,不利用相关三元组的信息。为了克服上述缺点,提出了关系型图卷积网络(R-GCNs) (Schlichtkrull et al. 2018)来学习实体嵌入,大大增强了相关三元组之间的信息交互。Nathani等人(2019)在实体表示的学习过程中,进一步将信息从1跳实体流向n跳实体,并在多个关系预测数据集上实现SOTA性能,特别是对于那些包含高阶节点的关系集合。
我们认为,知识图谱所包含的信息远远没有得到充分利用。在本研究中,我们发展了一种KRL方法,可以将任何子图转换成训练样本,从理论上对知识图谱中的任何信息进行建模。此外,该知识表示被集成到语言模型中,以获得医学预训练语言模型的增强版本。
结论和未来工作
针对知识图谱中子图的建模问题,提出了一种学习更全面知识表示的新方法。此外,所学习的医学知识被整合到预训练的语言模型中,该语言模型在几个医学NLP任务中执行了BERT-Base和另外两个领域特定的预训练的语言模型。我们的工作验证了医学知识有利于某些医学NLP任务的直觉,为医学知识的应用提供了初步的探索。
在后续工作中,将利用知识表示学习方法的传统下游任务,如关联预测,进一步验证KG-Transformer的有效性。此外,我们将探索一种更有效的方式,将医学知识与语言模型相结合。
参考论文:https://arxiv.org/abs/1912.00147





