
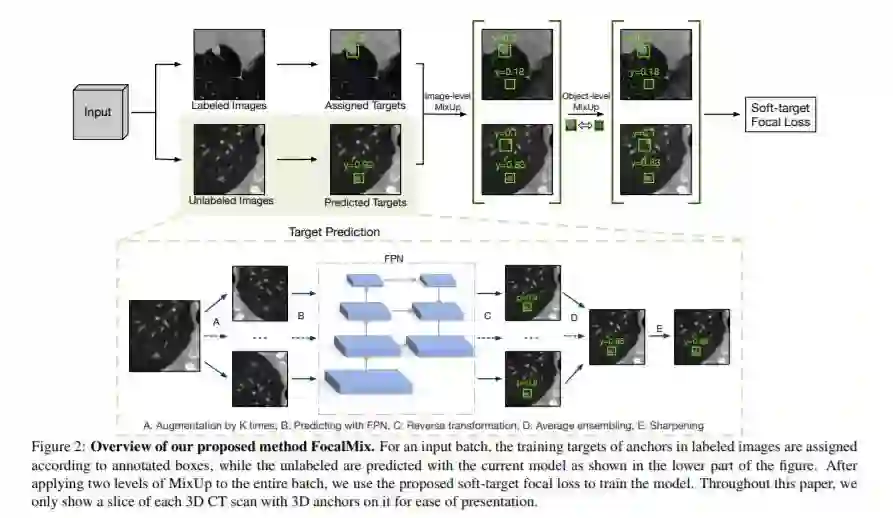
人工智能技术在医学影像领域的应用是医学研究的热点之一。然而,这一领域最近的成功主要依赖于大量仔细注释的数据,而对医学图像进行注释是一个昂贵的过程。在本文中,我们提出了一种新的方法,称为FocalMix,据我们所知,这是第一个利用半监督学习(SSL)的最新进展来进行3D医学图像检测的方法。我们对两个广泛应用的肺结节检测数据集LUNA16和NLST进行了广泛的实验。结果表明,与最先进的监督学习方法相比,我们提出的SSL方法可以通过400个未标记的CT扫描实现高达17.3%的实质性改进。
成为VIP会员查看完整内容
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
专知会员服务
24+阅读 · 2020年4月4日
Arxiv
21+阅读 · 2018年12月25日


相关VIP内容
专知会员服务
24+阅读 · 2020年4月4日
相关资讯
相关论文
Arxiv
21+阅读 · 2018年12月25日