ECCV 2018 | 腾讯优图提出几何对抗损失函数在单视图3D物体重建中的应用
机器之心发布
作者:Li Jiang, Shaoshuai Shi, Xiaojuan Qi, Jiaya Jia
机器之心编辑部
点云是常用的3D物体表示方式,但该技术中的损失函数没有保证预测的点遵从物体的几何形状。为解决这一问题,腾讯优图与港中文联合提出了一种补充的损失函数——几何对抗损失,通过保持预测点云和真实点云在不同2D视角上的几何一致性来从整体上规范生成的点云,同时要求生成的点云与输入图片的语义相符。
论文:GAL: Geometric Adversarial Loss for Single-View 3D ObjectReconstruction

论文链接:https://xjqi.github.io/GAL.pdf
1. 介绍
单目 3D 物体重建是计算机视觉的一个基础问题,在机器人科学,虚拟现实等领域有广泛的应用。随着大规模 ShapeNet 数据集的出现和深度卷积神经网络的发展,数据驱动的 3D 物体重建获得了越来越多的关注。现有的方法采用的 3D 物体表示方式大多是以下两种:三维像素和点云。采用三维像素来表示 3D 模型,需要神经网络直接预测每个三维像素是否被物体占据。尽管三维立体像素可以直接使用 3D 卷积神经网络处理,这种表示方式在高分辨率时常常会受到效率和内存问题的困扰。为了解决这些问题,Fan et al. 提出了点云模型。点云模型中物体由离散的三维点组成。考虑到点云的可扩展性和灵活性,我们基于点云模型构建了一个 3D 重建系统。
在点云表示方式的发展过程中,研究者大都着眼于设计一个损失函数来衡量预测点云和真实点云的距离。Chamfer 距离和 Earth Mover 距离被用于当作损失函数来优化神经网络模型,减小重建模型与真实模型的差距。但这些损失函数有其局限性,即它们没有保证预测的点遵从物体的几何形状,这些点可能存在于真实的物体 3D 形体之外。
在本文中我们提出了一种补充的损失函数——几何对抗损失来解决这个问题。几何对抗损失通过保持预测点云和真实点云在不同 2D 视角上的几何一致性来从整体上规范生成的点云,同时它要求生成的点云与输入图片的语义相符。
几何对抗损失由两个损失项组成:多视角几何损失和条件对抗损失。几何损失使得预测结果与真实模型在不同视角保持几何一致。条件对抗损失则通过条件判别网络来优化生成模型。条件判别网络由提取图片语义特征的 2D 卷积神经网络和提取点云特征的 PointNet 组成。2D 图片特征作为条件促使生成的 3D 点云符合输入图片的语义。总的来说,几何对抗损失在整体上规范了生成的 3D 模型,与前面提到的 Chamfer 距离损失相互补充,从而更好地进行单视角物体重建。
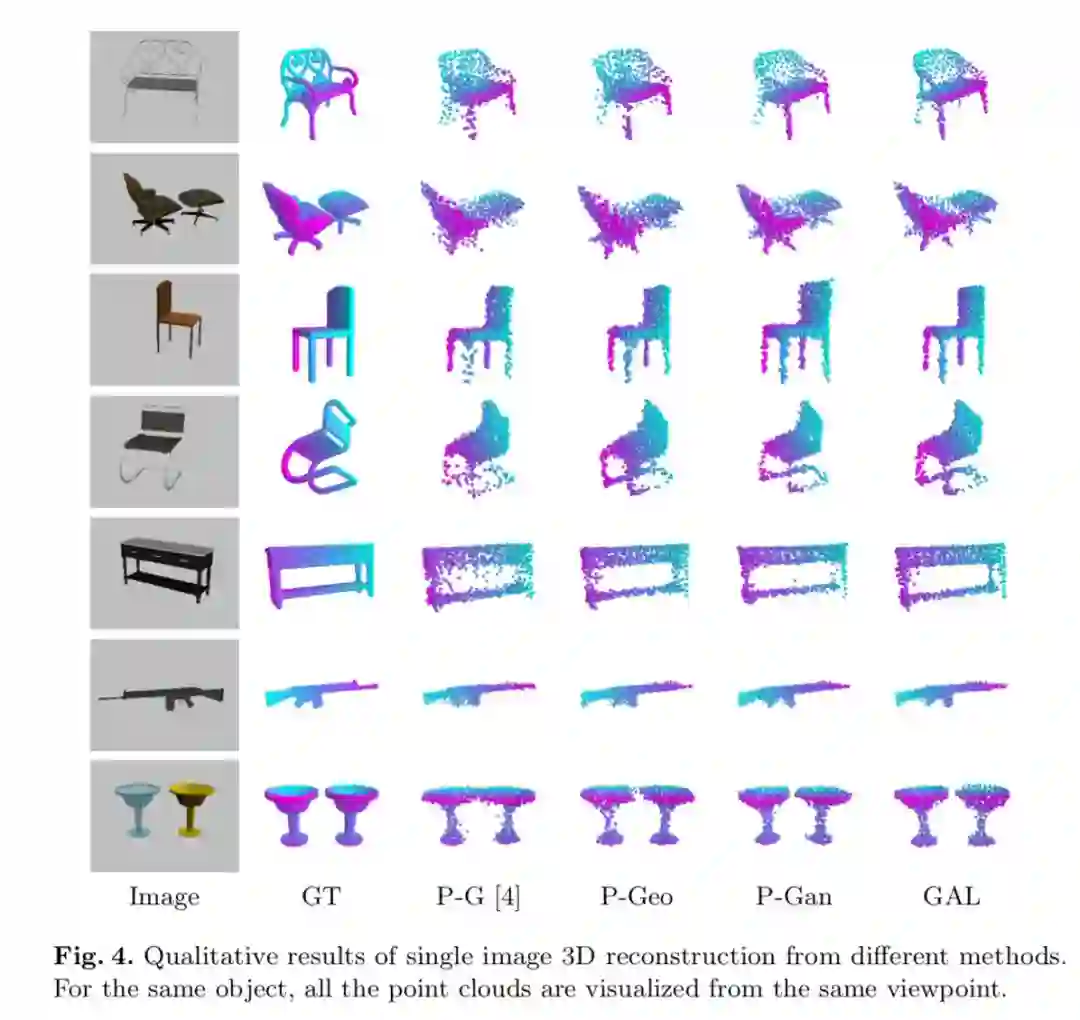
如图 1(b)(d) 所示,仅仅使用 Chamfer 距离损失,生成的点云有许多不在物体三维形状内的噪点。这是因为重建过程没有满足对整体的 3D 几何形体的限制,而仅采用了局部的点对点的限制。如图 1(c)(e) 所示,几何对抗损失使得重建的结果更加合理。

2. 网络结构
如图 2 所示,整个网络框架由两部分组成:生成网络和条件判别网络。生成网络包含一个编码解码模块构成的卷积分支和一个全连接分支,负责将输入的单视角图片映射到相对应的点云。判别网络则由一个提取生成/真实点云特征的 PointNet,和一个从输入图片中提取物体语义特征的 2D CNN 组成,提取的 2D 和 3D 特征被连接在一起作为最终的特征表示,以判别输入判别器的 3D 点云是否真实合理。
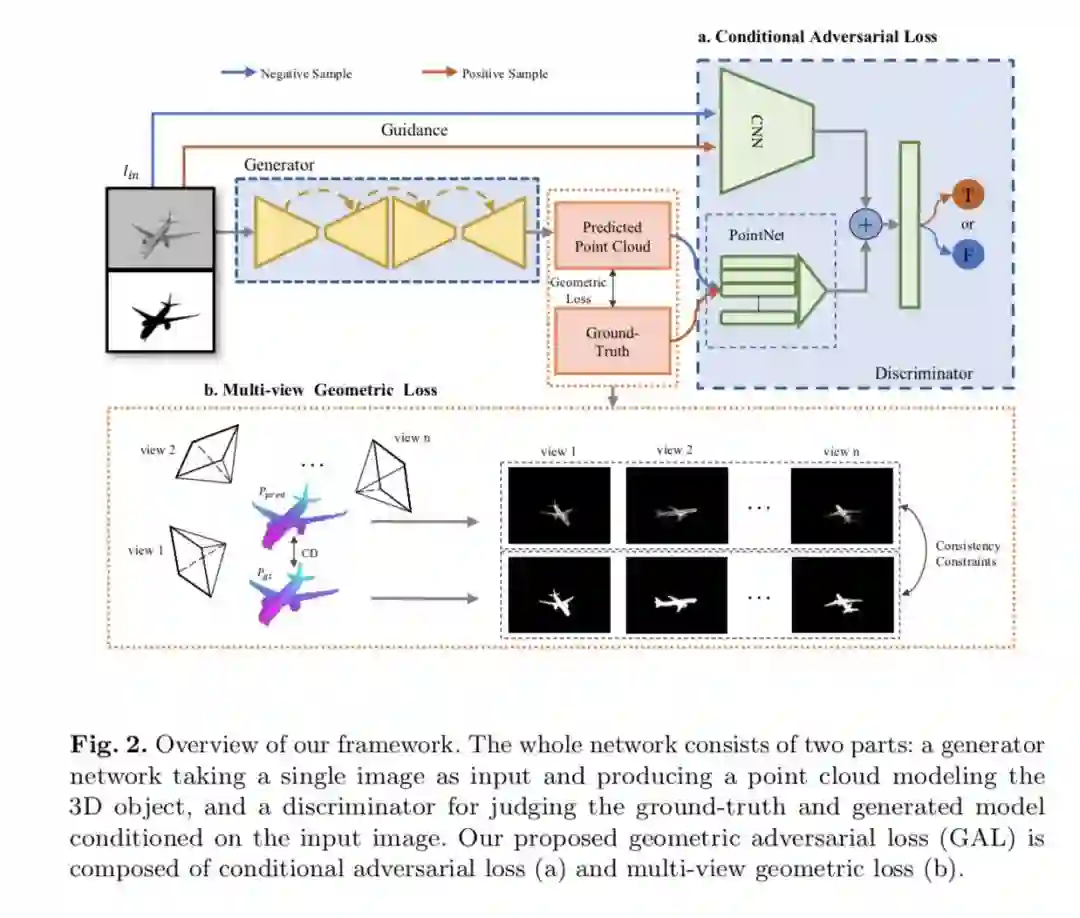
3. GAL: 几何对抗损失
3.1 多视角几何损失
人类即使只从一个方向看物体,也可以自然的联想出它的三维形状。这是因为我们拥有这个物体是什么形状的先验知识。在这一部分中,我们增加了多视角几何约束,从而让神经网络也掌握这样的先验知识。多视角几何损失从多个不同的视角衡量了模型预测的点云和真实点云在几何上的不一致程度。
当给定当前生成的点云和真实点云时,对于每个给定的视角,我们通过使用其对应的相机参数可以分别合成一副当前视角下生成点云的投影图和真实点云的投影图,并且比较两幅生成图像的不一致程度,作为当前视角的几何损失。
如图 3 所示,这样存在一个问题,那就是当生成图像的分辨率较高时,两幅生成图像的点云密度会存在较大的差别。因为真实点云的点的数量远大于生成点云的点的数量,所以合成的真实点云的投影图像会比生成点云的头像图像密的多。为了解决这个问题,我们的多视角几何损失包含了高分辨率模式和低分辨率模式两部分。
高分辨率模式: 在高分辨率模式中,我们将投影图像的长和宽设为了较大的值,记为 h1,w1。如图 3(b1-e1) 所示,该模式下的投影图像包含了较多的细节。然而,由于两幅投影图像的点的密度存在较大差异,直接使用 L2 损失衡量两者的不一致性显然不合适。由于生成点云对应的投影图像更稀疏,所以我们提出只使用生成点云投影图像中非空的点来衡量两者的不一致性,如下所示:

低分辨率模式:在高分辨率模式中,我们只要求了生成点云投影图中的非空点也需要出现在真实点云投影图的对应位置。然而,值得注意的是,这个约束应该是双向的。在低分辨率模式中,我们将投影图像的长和宽设为了较小的值,记为 h2,w2。该模式下的投影图像如图 3(b2-e2) 所示,虽然在低分辨率模式下图像损失了一些细节,但是大体的形状是保留的,且也能用来衡量两者的不一致性。因此,低分辨率模式下的不一致性的衡量我们直接使用了 L2 损失,如下所示:
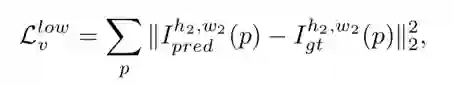
多视角几何损失:我们设 v 为不同视角的标号变量,则整体的多视角几何损失可以记为:
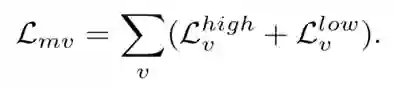
该损失函数从不同视角约束了生成点云的几何形状。
3.2 基于点云的条件对抗损失
为了产生更合理且符合输入图像的点云,我们提出了基于点云的条件对抗损失去规范生成的 3D 物体点云。我们的出发点是考虑到生成的 3D 模型需要跟输入的图像保持语义信息上的一致。我们采用了 PointNet 提取生成点云的全局特征,将此全局特征加上输入图像提供的 2D 语义特征输入判别网络,则可以让判别网络更好的识别生成的点云和真实的点云。在对抗训练中,生成点云和 2D 图像语义特征作为负样本,而真实点云和 2D 图像语义特征作为正样本,用于训练判别网络。这样在训练生成网络时,该条件对抗损失会促使生成点云更加符合输入图像的特征。
在判别网络中,我们使用了预训练好的 CNN 提取 2D 图像的语义特征,使用 PointNet 提取点云的全局特征。由于真实点云比生成点云更密,我们在实际中下采样的真实点云,使其与生成点云规模一致。并且,我们采用了 LSGAN 作为我们的条件对抗损失,如下所示:
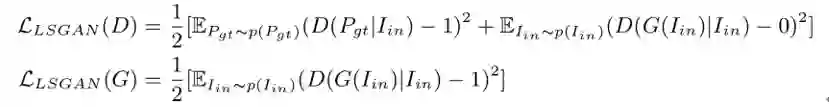
在对抗训练过程中,生成网络和判别网络将会被交替优化。生成网络促使生成点云更接近真实点云,而判别网络目标是区分真实点云与生成点云。在测试时,只有训练好的生成网络会被用于从单幅图像中重建物体三维模型。

多种方法的对比:
P-G:chamfer 距离损失
P-Geo:chamfer 距离损失 + 多视角几何损失
P-Gan:chamfer 距离损失 + 条件对抗损失
GAL: chamfer 距离损失 + 几何对抗损失
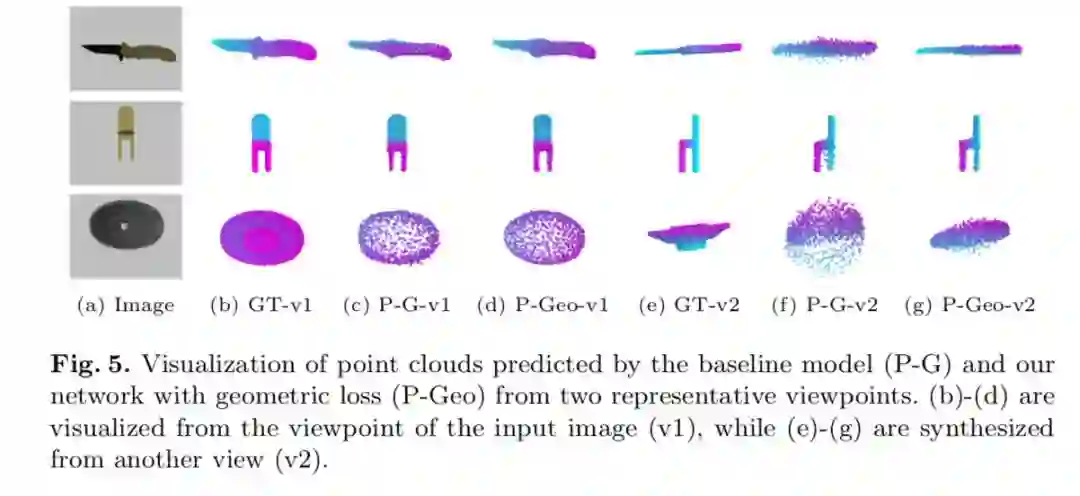
多视角几何损失函数:多视角几何损失函数保证了重建的点云不仅是从拍照视角 (v1),而是从各个视角看 (v2) 都符合真实物体的三维形状。
基于点云的条件对抗损失函数:利用判别网络,使得生成的点云更加符合物体语义。例如第二行的椅子,从侧面看时,不采用对抗损失生成的点云 (f) 很难分辨出是一个座椅,而加上对抗损失生成的点云 (g) 显然更加合理。

真实图片作为输入的例子:
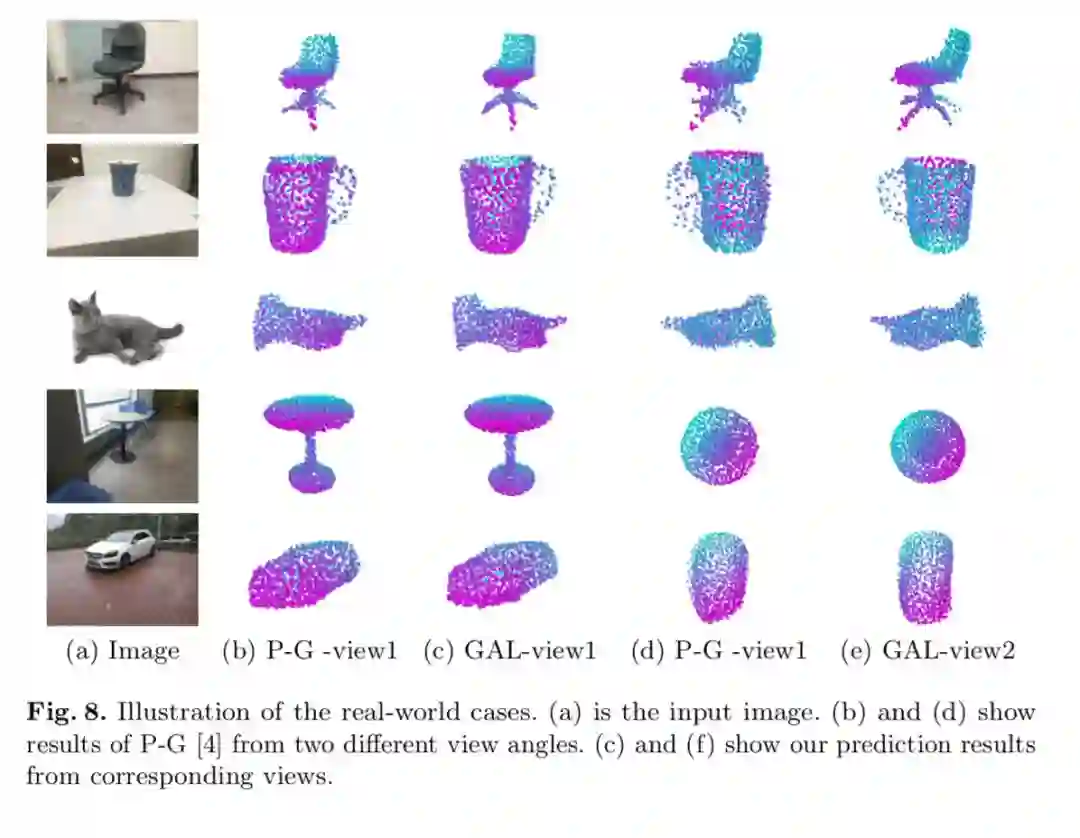
更多例子:



本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


