
题目: Self-Supervised Viewpoint Learning From Image Collections
简介:
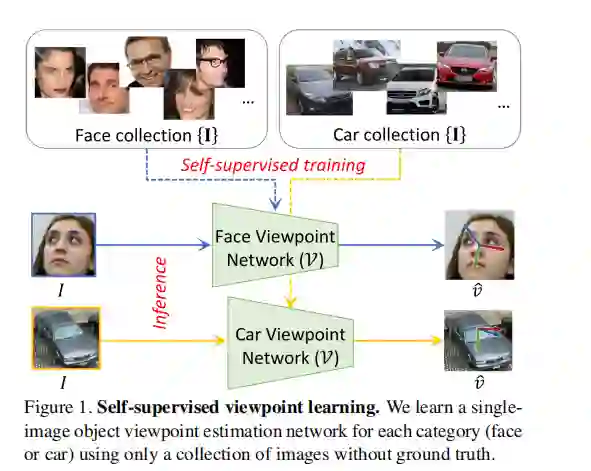
训练深度神经网络以估计对象的视点需要标记大型训练数据集。但是,手动标记视点非常困难,容易出错且耗时。另一方面,从互联网(例如汽车或人脸)上挖掘许多未分类的物体类别图像相对容易。我们试图回答这样的研究问题:是否可以仅通过自我监督将这种未标记的野外图像集合成功地用于训练一般对象类别的视点估计网络。这里的自我监督是指网络具有的唯一真正的监督信号是输入图像本身。我们提出了一种新颖的学习框架,该框架结合了“综合分析”范式,利用生成网络以视点感知的方式重构图像,并具有对称性和对抗性约束,以成功地监督我们的视点估计网络。我们表明,对于人脸,汽车,公共汽车和火车等几个对象类别,我们的方法在完全监督方法上具有竞争性。我们的工作为自我监督的观点学习开辟了进一步的研究,并为其提供了坚实的基础。
成为VIP会员查看完整内容


相关内容

NVIDIA(全称NVIDIA Corporation,NASDAQ:NVDA,发音:IPA:/ɛnvɪdɪə/,台湾官方中文名为輝達),创立于1993年4月,是一家以设计显示芯片和芯片组为主的半导体公司。NVIDIA亦会设计游戏机核心,例如Xbox和PlayStation 3。NVIDIA最出名的产品线是为个人与游戏玩家所设计的GeForce系列,为专业工作站而设计的Quadro系列,以及为服务器和高效运算而设计的Tesla系列。
NVIDIA的总部设在美国加利福尼亚州的圣克拉拉。是一家无晶圆(Fabless)IC半导体设计公司。"NVIDIA"的读音与英文"video"相似,亦与西班牙文evidia(英文"envy")相似。现任总裁为黄仁勋。
专知会员服务
22+阅读 · 2020年3月18日
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
Arxiv
6+阅读 · 2018年1月28日
相关主题




相关VIP内容
专知会员服务
22+阅读 · 2020年3月18日
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
87+阅读 · 2020年3月1日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年1月28日