【上海交大】半监督学习理论及其研究进展概述
【导读】半监督学习介于传统监督学习和无监督学习之间,是一种新型机器学习方法,其思想是在标记样本数量很少的情况下,通过在模型训练中引入无标记样本来 避免传统监督学习在训练样本不足(学习不充分)时出现性能(或模型)退化的问 题。上海交通大学屠恩美和杨杰老师撰写了一篇关于《半监督学习理论及其研究进展概述》论文,详细阐述了最新回顾了半监督学习的发展历程和主要理 论,并介绍了半监督学习研究的最新进展,最后结合应用实例分析了半监督学习在 解决实际问题中的重要作用。

论文地址:
https://arxiv.org/abs/1905.11590
请关注专知公众号(点击上方蓝色专知关注)
后台回复“SMLS” 就可以获取《半监督学习进展综述》的下载链接~
半监督学习发展综述
传统的监督学习(如支持向量机,神经网络等)通常需要大量的良好标记样本对模型进 行仔细地训练, 以便获得较好的模型泛化能力。同时,由于维度灾难的问题,在处理高维数 据(如视频、语音、图像分类、文档)时,训练一个好的监督模型所需要的标记样本数量会 进一步呈现指数暴增趋势。这使得传统监督学习很难应用于一些缺乏训练样本的任务中。例 如,医学诊断中某些疾病患者数量较少,且部分患者可能有隐私考虑不愿信息被采集使用; 再如,具有破坏性的实验中(汽车碰撞实验、火箭发射、新产品耐用性测试等)也很难收集 到大量的训练样本,因为成本很高。因此,在模型的训练中,如何降低学习模型对标记样本 数据量的需求,同时提高模型学习的性能,成为一个重要的研究问题。
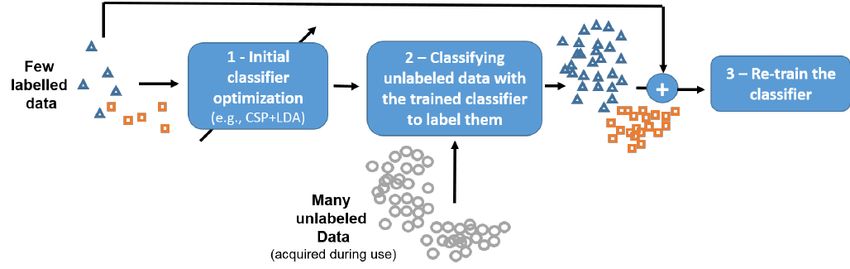
半监督学习(Semi-supervised Learning)是近十多年来发展起来的一类新型机器学习方 法,其思想是在标记样本数量很少的情况下,通过在模型训练中引入无标记样本来避免传统 监督学习在训练样本不足(学习不充分)时出现性能(或模型)退化的问题。半监督学习的 研究具有重要的实用价值,因为在许多实际应用中,一方面标记样本的获取成本往往较高(如 需要花费人力和时间进行标记,需要用到特殊仪器或设备进行实验和测量等);另一方面无 标记样本的获取相对容易,只需要简单重复地采集即可大量收集。因此,在实际应用中减少 标记样本的使用能够大幅缩减人力、时间和资源的开销,从而降低生产成本。同时在标记样本数量减少数十或数百倍(甚至更多)的情况下,算法能够取得与传统大量标记样本训练的 监督学习算法相近甚至更好的效果,提升了生产效率。半监督学习的研究也具有重要的理论 价值,它是介于传统监督学习(只利用标记样本学习)和无监督学习(只利用无标记样本学 习)之间的一种新型机器学习方法,是对传统机器学习理论的拓展和补充。此外,已有的研 究表明人类的学习过程中也存在大量的半监督学习行为,因此半监督学习也对认知科学的发 展起到了一定的促进作用。
本文首先回顾了半监督学习的发展历程,然后介绍了半监督学习的主要理论和算法,之 后详细介绍了笔者实验室在半监督学习研究方面的最新进展和成果,结合实例分析了半监督 学习在解决实际问题中的重要作用,最后对半监督学习研究进行了总结和展望。与以往的综述[1, 2]相比,本文总结了半监督学习的发展阶段性特点,并对每个阶段的代表性算法进行了 较为全面的综述,另外还包含了其他综述中未曾涉及的最新的半监督深度学习算法。
20 世纪 90 年代就有学者开始尝试在训练分类器时利用无标记样本来提高分类器性能, 但 2000 年后半监督学习才逐步形成相对独立的理论和算法体系,成为有别于传统监督学习 和无监督学习的一类新型机器学习方法。总体来看,半监督学习大概具有以下三个发展阶段 特征:第一个阶段是在上世纪 90 年代期间,人们初步探索无标记样本在一些传统机器学习 算法中的作用,是半监督学习的酝酿阶段;第二阶段是本世纪初的十多年间,形成了独立的 半监督学习算法和理论体系,是经典半监督学习发展趋于成熟阶段;第三个阶段是最近几年, 由于深度学习的巨大成功和普及应用的需求,半监督学习与深度神经网络结合形成的半监督 深度学习成为研究热点,把半监督学习研究推向新的高度。下面我们对每个阶段的代表性算 法进行介绍。
半监督学习的早期阶段
早期的半监督学习是初步探索无标记样本在传统监督学习模型中的价值[3],学习算法多 数是对传统的机器学习算法进行改进,通过在监督学习中加入无标记样本来实现。这类算法 有最大似然分类器[4, 5],贝叶斯分类器 (Bayes Classifier)[6, 7],多层感知器[8],支持向量机[9, 10] 等。早期半监督学习算法中有较大影响力的是半监督支持向量机(Semi-supervised Support Vector Machine, S3VM)和协同训练(Co-training)。
S3VM 源于 Vapnik20 世纪 90 年代末的直推式支持向量机(Transductive SVM)研究[11]:在 给定较少标记的训练样本情况下,支持向量机的决策边界(Decision Boundary)不应该穿过样 本密度高的区域。因此,S 3VM 的目标函数是在传统的支持向量机目标函数基础上,增加了 一个包含无标记样本的约束项来惩罚分类超平面穿过样本密集区域的情况。修改后的目标函 数是一个非凸的组合优化问题,直接求解难度较大且计算量会随着数据集的增大而指数暴增, 因此初期的求解算法基本很难在实际应用中使用。Joachims 提出了基于标记切换的组合优化 算法[12],第一次使 S3VM 在具有实用意义的数据集上取得了很好的效果。之后更多的学者 开始关注 S3VM,相继出现了不同的求解方法,其中较有影响的算法包括半正定规划 (Semi-definite Programming)[13-16]算法,凹凸过程(Concave Convex Procedure)[17-19],延续法 (Continuation)[20], 梯度下降[21],确定性退火(Deterministic Annealing) [22]等。另外,为了避 免算法把所有样本放在决策边界的同一边这种无意义的求解,文献[12, 20, 21]中还探讨了施 加平衡约束(Balancing Constraint)情况下的 S3VM 问题求解。
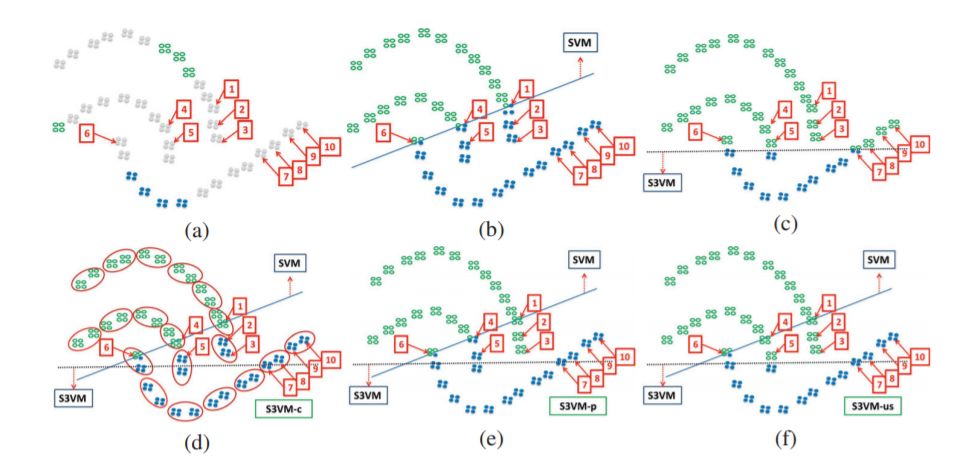
协同训练[23]假设数据本身具有多个相互独立的视角(Multi-view),且每个视角都可以 独立对数据进行分类。针对数据的每个视角,协同训练首先用标记样本训练一个该视角对应 的分类器,然后不同视角的分类器对无标记样本进行分类,每个视角的分类器都把自己认为 可靠度较高的无标记样本连同其对应的分类标记加入到其他视角分类器的训练数据集中,最 后所有分类器利用各自更新后的训练集进行二次训练,如此重复直到完成分类。文献[24]中 进一步分析了协同训练能够取得好的效果的原因,同时讨论了协同训练假设不成立时的情况。 文献[25]中提出了弱化假设的协同训练,并进行了理论分析。协同学习在自然语言处理中有 着重要的的应用,包括语意解析[26],语意标注[27],词语的同指解析[28],歧义去除[29],跨语 言情感分类[30]等。
半监督学习的成熟阶段
由于 S3VM 是非凸离散组合优化,求解难度大且很难获得全局最优解,同时协同训练假 设条件苛刻等,人们开始尝试其他方法进行半监督学习。2000 年后的十多年间大量的半监 督学习算法开始涌现,这时期的标志是“半监督学习”的概念被明确提出并形成了崭新的算 法体系,使半监督学习逐渐形成相对独立的、区别于传统监督学习和无监督学习的一类学习 方法。这个时期的半监督学习主要包括混合模型(Mixture Model)[31-34]、伪标记或自训练 (Pseudo Label, Self-training)[29, 35-37]、图论半监督学习[38-40]、流形半监督学习[41-43]等。与其他 类型的半监督学习算法相比,基于图论的半监督学习算法有许多优势,如算法多数为凸优化, 可求得全局最优解,有些甚至具有闭合数学表达式;算法基于矩阵运算操作,效率较高且便 于理解和实现;图论是数学的一个分支,具有很好的理论基础等,因此受到了广泛的关注。
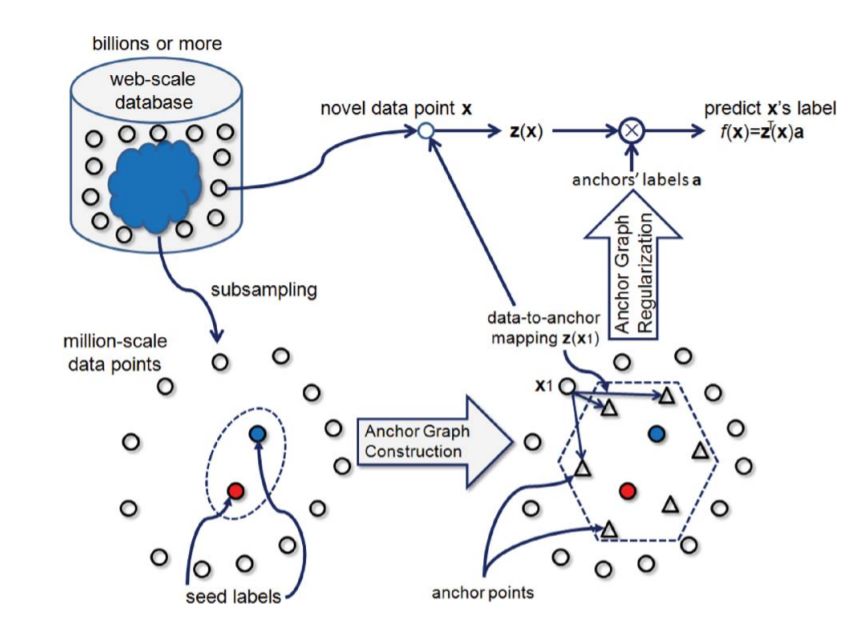
图论半监督学习需要首先构建一个图 (Graph), 图的节点集就是所有样本集(包括标记 样本和无标记样本),图的边是样本两两间的相似性(通常使用高斯核函数作为相似性度量), 然后把分类问题看作是类别信息在图上由标记节点向无标记节点的扩散或传播过程。代表性 的算法包括:文献[38]利用图论中的最小切割(Min-cut)算法来对无标记样本进行分类,文献 [44]中把学习过程看作是样本的类别标记在图上的不断扩散和传播,文献[39]中通过求解高 斯场谐函数(Gaussian Field Harmonic Function, GFHF)来实现对图上的无标记样本进行分类, 稍后文献[40]中提出基于网络的动态传播思想的局部和全局一致性(Local and Global Consistency, LGC)半监督学习算法。GFHF 和 LGC 两个算法都具有很好的理论框架,以及具 有闭合解析式的全局最优解,同时算法易于实现,在实际应用中效果突出,因此引起了学者 们的广泛关注,成为图论半监督学习的经典算法代表。二者同属于直推式学习(Transductive Learning)方式,即算法只能在参与学习过程的数据集上学习出一个模型,因此对于后续的新 样本无法直接给出分类。但二者相比,LGC 算法对样本的标记具有更好的容错性(因为采 用的是软约束,而不像 GFHF 中强制的硬性约束),而且实际应用时效果也往往更好。文献 [45]中把这两个算法统一在一个理论模型中,并在此基础上提出了基于 Nystrom 核矩阵近似 的快速算法,以解决图论半监督学习在大数据集上计算复杂度高、内存消耗大的问题。文献 [46]在 LGC 算法的基础上采用了局部线性重构的方式构建图,提出线性邻域标记传播(Linear Neighborhood Label Propagation)算法,受到较多关注。因为图论半监督学习需要构建一个包 含所有样本的图,而且求解算法时间和空间复杂度通常是样本的三次方,这带来的一个难题 是如何在大数据集上进行学习,文献[47, 48]中对超大型的数据集上如何进行半监督学习做 了研究。需要说明的是,图论半监督学习中还有许多其他算法和相关研究,在此无法一一列 举。例如,文献[49]中分析了图的构建方式对算法性能的影响并提出了一种 b-Matching 图提 升算法精度,文献[50]中研究了基于有向图的半监督学习,文献[51]中研究了多图组合下的 半监督学习,文献[52]中研究了半监督的降维算法,文献[53]中探讨了参数学习问题等等。
半监督学习研究中,与图论密切相关的另一个理论是微分流形理论。在一定条件下,图 论中的拉普拉斯矩阵可以看成是流形上的拉普拉斯-贝尔特拉米算子(Laplace-Beltrami Operator)的离散化[54-56]。因此,以图论作为工具,基于微分流形理论的半监督学习算法也受 到 广 泛 关 注 。 这 其 中 的 代 表 算 法 是 Belkin 等 提 出 的 流 形 正 则 化 算 法 (Manifold Regularization)[41, 42, 57],其目标是在高维的数据空间中,通过惩罚分类函数在样本所分布的 低维流形上的复杂度来实现无标记样本的利用。其他基于微分流形理论的半监督学习算法包 括黎曼流形(Riemannian Manifold)半监督学习[43],海森正则化(Hessian Regularization)半监督 学习[58],局部坐标编码(Local Coordinate Coding)半监督学习[59],多流形半监督学习[60]等。
半监督深度学习的发展
随着深度学习在图像识别[61]、自然语言处理[62]和语音识别[63]等方面取得突破,半监督 深度学习算法研究就成了自然的需求,因为深度学习普及应用的障碍之一就是对海量标记样 本的需求在很多应用中难以被满足。较早进行半监督深度学习研究的是 Weston 等[64],他们 尝试把图论半监督学习中的拉普拉斯正则项引入到神经网络的目标函数中,对多层神经网络 进行半监督训练。总结起来,已有的半监督深度学习算法可归为三类:无监督特征学习类, 正则化约束类和生成式对抗网络(Generative Adversarial Nets, GAN)类。
无监督特征学习类算法通常利用所有样本(包含标记样本和无标记样本)学习出样本的隐特征或隐含变量表示(Latent Feature or Hidden Variable),在此基础上利用有监督分类器对 无标记样本所对应的隐特征进行分类,从而间接地对无标记样本进行分类。文献[65]中采用 叠加的生成模型来学习标记样本和无标记样本的隐变量并使用 SVM 对学习的隐变量进行分 类。文献[66]中首先采用局部区域卷积(Local Region Convolution)在无标记的文本中学习出双 视嵌入(Two-View (TV) Embedding)特征,然后采用卷积神经网络进行分类。随后文献[67]中 又对该算法进行了拓展,采用 LSTM (Long Short-Term Memory)进行区域大小可变的文本特 征学习。文献[68]中把自编码器(Auto-Encoder)的编码层和解码层之间加入短路连接,然后使 用分类器对自编码器学习的特征进行分类。文献[69]中把自编码器按顺序拼接在一起,通过 最小化这些自编码器的重构误差可以学习出序列数据的隐特征。其他算法还包括弱监督下的 激活图学习[70],图卷积网络学习隐特征[71]。
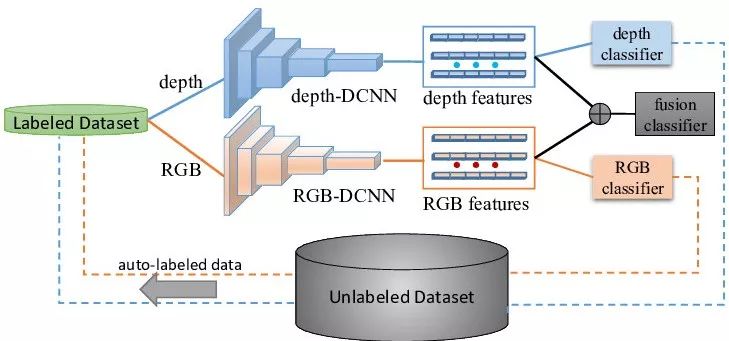
正则化约束类算法通常是在有监督神经网络的输出层或者隐含层的目标函数中加入体现样本分布特性的正则化项,用以在训练中引入无标记样本。文献[64]中把图的拉普拉斯正则化项分别加入到网络输出层的目标函数和中间隐含层的目标函数中,用来做半监督的分类 和特征学习。文献[72]中定义一组标准的随机变换操作,然后定义网络目标函数包括两个部 分:监督学习损失函数为标记样本多次随机变换后的预测差异,正则化项为无标记样本多次 通过网络预测的结果差异,最后通过反向梯度传播来最小化目标函数进行半监督深度学习。 文献[73, 74]中分别使用最大似然分类器和多层感知器作为监督学习的损失函数,并借用自 然语言处理中用于词语特征学习的 Skipgram 模型作为正则化项。文献[75]中采用分类指示向量互斥原则对网络进行正则化,即所有样本通过网络后输出的类别向量中只有一个为非 0,这就迫使网络在训练时对无标记样本的分布进行学习并给出确定的类别。其他的正则化半监督学习还包括信息熵正则项(Entropy Regularization)[76, 77],自编码器正则化[78],邻域距离正 则化[79]。需要说明的是,早期训练深度神经网络时常用的 Pre-training, Fine-tuning 训练方法, 如文献[80, 81],也可看作是一种特殊的正则化[82]。
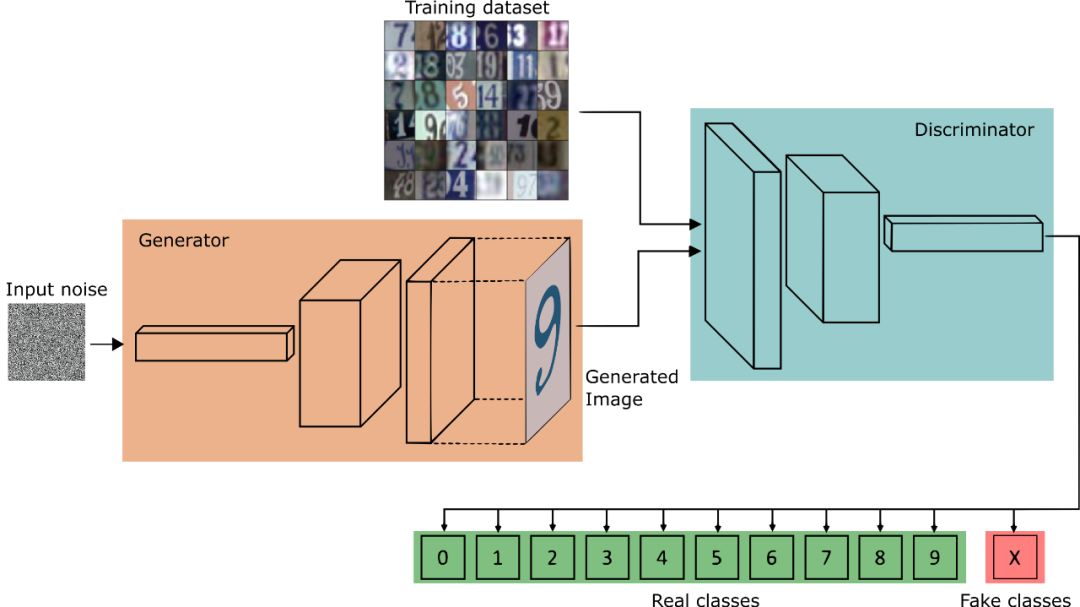
生成式对抗网络 GAN[83]中,通过让生成器(Generator)和判决器(Discriminator)相互竞争 达到平衡状态来无监督地训练网络。由于 GAN 在生成模拟真实样本上的成功表现(如文献 [84]中),一个很自然的想法就是在标记样本较少的情况下,能否利用 GAN 所学到的样本内 容分布和强大的竞争学习能力来提高网络分类性能。文献[85]中迫使判决器对于真实样本输 出单热向量(One-hot Vector),而对于生成样本输出均匀向量(即类别不确定)。文献[86]中提 出了一种输出分布匹配(Output Distribution Matching, ODM)方法用作半监督学习中的正则化 项,并用 GAN 对网络进行训练使得生成的虚拟样本类别分布与真实样本类别分布相匹配。 文献[87, 88]中通过对判决器进行修改使其输出 K 1 类,其中前 K 类为真实数据的分类, 后一类为生成样本分类。这样在 GAN 的训练过程中,分类器需要在判断真假样本的基础上, 进一步给出真样本的类别,这就可以借助 GAN 在训练中学到的样本内容分布加上少量标记 样本来完成半监督学习。另外,这里强制对样本进行分类与文献[85]中强制输出单热向量目 的上是一致的,都是要求判决器尽可能地确定每个样本的类别信息。文献[89]中证明了在半 监督学习情况下,一个差的生成器能够更有利于判决器进行半监督地学习,并以此为基础对 GAN 做了修改,通过最小化生成器真假样本分布的 KL 散度和最大化判决器的条件熵来交 替训练网络,效果改进明显。
参考文献
[1] ZHU X. Semi-supervised learning literature survey[J]. Computer Science, University of Wisconsin-Madison, 2006, 2(3): 4.
[2] CHAPELLE O, SCHOLKOPF B, et al. Semi-supervised learning[J], IEEE Transactions on Neural Networks, 2009, 20(3): 542-542.
[3] CASTELLI VITTORIO, COVER THOMAS M, The relative value of labeled and unlabeled samples in pattern recognition with an unknown mixing parameter[J], IEEE Transactions on Information Theory, 1996,42(6): 2102-2117.
[4] SHAHSHAHANI BEHZAD M, LANDGREBE DAVID A, The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon[J], IEEE Transactions on Geoscience And Remote Sensing, 1994,32(5): 1087-1095.
[5] RATSABY JOEL, VENKATESH SANTOSH S. Learning from a mixture of labeled and unlabeled examples with parametric side information[C]//Proceedings of The Eighth Annual Conference on Computational Learning Theory, ACM, 1995: 412-417.
[6] NIGAM KAMAL, MCCALLUM ANDREW, et al. Learning to classify text from labeled and unlabeled documents[C]//The Fifteenth National Conference on Artificial Intelligence, 1998,792.
[7] MCCALLUMZY ANDREW KACHITES, NIGAMY KAMAL, Employing EM and pool-based active learning for text classification[C]//Proc. International Conference on Machine Learning (ICML), Citeseer, 1998, 359-367.
[8] DE SA VIRGINIA R, Learning classification with unlabeled data[C]//Advances in Neural Information Processing Systems, 1994, 112-119.
[9] BENNETT KRISTIN P, DEMIRIZ AYHAN, Semi-supervised support vector machines[C]//Advances in Neural Information Processing Systems, 1999: 368-374.
[10] JOACHIMS THORSTEN. SVM-Light Support Vector Machine [OL].(1999-04). http://svmlight. joachims. org/
[11] VAPNIK VLADIMIR NAUMOVICH, VAPNIK VLAMIMIR, Statistical Learning Theory, Wiley New York, 1998.
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



