【推荐】伪标签学习导论 - 一种半监督学习方法
转自:上大飞猪钱小莲
作者 SHUBHAM JAIN
译者 钱亦欣
引言
在有监督学习领域,我们已经取得了长足的进步,但这也意味着我们需要大量数据来做图像分类和销量预测,这些算法需要把这些数据扫描一遍又一遍来寻找模式。
.然而,这其实不是人类的学习方法,我们的大脑不需要成千上万的数据循环往复地学习来了解一类图片的主题,我们只需要少量的特征点来习得模式,所以现有的机器学习方法是有所缺陷的。
好在现有已经有一些针对这个问题的研究,我们或许可以构建一个系统,它只需要最少量的监督数据输入但能学得每个任务的主要模式。本文将会介绍其中一种名为伪标签学习的方法,我会深入浅出的讲解原理并演示一个案例。
走起!
注:我既定你已经对机器学习又基本了解,如果没有请学习相关知识再看本文。
目录
什么是半监督学习 (SSL)?
如何利用无标签数据
伪标签学习
半监督学习的应用
采样率的作用
半监督学习的应用场景
1. 什么是半监督学习 (SSL) ?
假设我们目前面临一个简单的图像分类问题,我们的数据有两类标签(如下所示)。

我们的目标就是区分图像中有无日食,现在的问题就是如何仅从两幅图片的信息中构建一个分类系统。
一般而言,为了构建一个稳定的分类系统我们需要更多数据,我们从网上下载了更多相关图片来扩充我们的训练集。

但是,如果从监督学习的方法出发,我们还要给这些图片贴上标签,因此我们要借助人工完成这个过程。

基于这些数据运行了监督学习的算法,我们的模型表现显著高于那个仅基于两张图片的算法。
但是这个方法只在任务量不大的时候起效,数据量一大继续人工介入会消耗大量资源。
为了解决这一类问题,我们定义了一种名为半监督学习的方法,能从有标签(监督学习)和无标签数据(无监督学习)中共同习得模式。
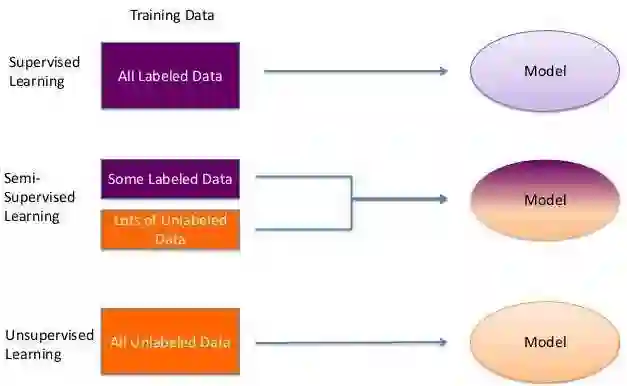
来源: 链接
因此,现在就让我们学习下如何利用无标签数据。
原文链接:
https://zhuanlan.zhihu.com/p/29886875




