
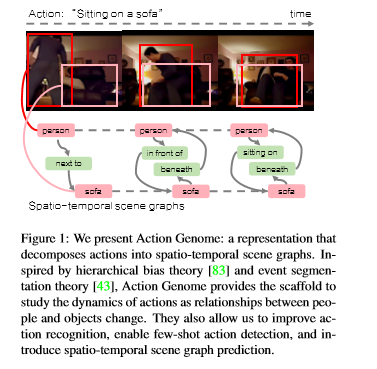
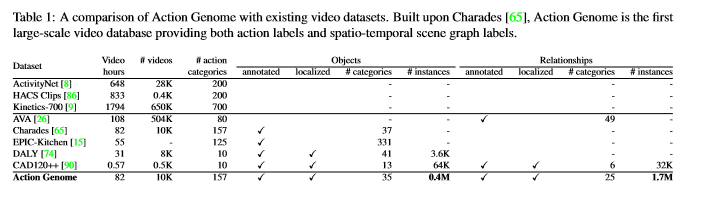
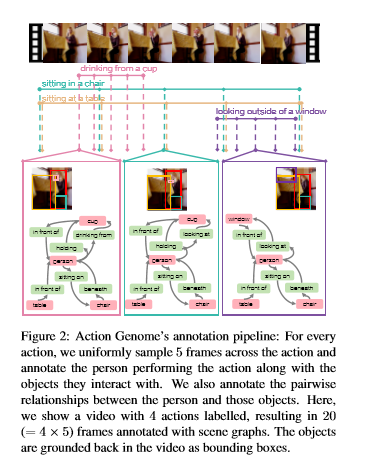
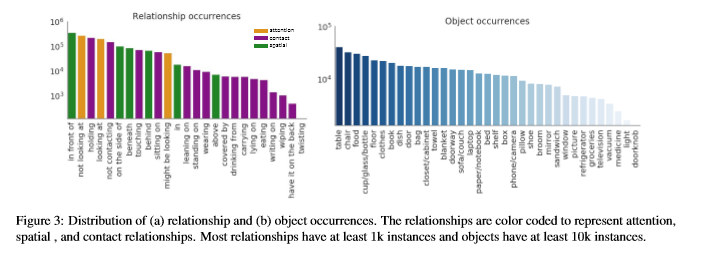
简介: 动作识别通常将动作和活动视为视频中发生的整体事件。但是,认知科学和神经科学的证据表明,人们积极地将活动编码为一致的层次结构。但是,在计算机视觉中,很少有关于编码事件单语的表示的探索。论文引入了动作基因组,该基因组将动作分解为时空场景图。动作发生时,基因组捕获对象之间的变化及其成对关系。它包含10K视频,其中有40万个对象和170万个可视关系。使用动作基因组,我们通过合并场景图的时空特征库来扩展现有的动作识别模型,以在Charades数据集上实现更好的性能。接下来,通过分解和学习导致动作的视觉关系的时间变化,我们通过启用少拍动作识别来演示分层事件分解的效用,仅使用10个示例就可以实现42.7%的mAP。最后,我们以时空场景图预测的新任务为基准对现有场景图模型进行基准测试。
成为VIP会员查看完整内容
相关内容

专知会员服务
100+阅读 · 2019年11月23日
专知会员服务
104+阅读 · 2019年10月22日
Arxiv
6+阅读 · 2018年1月28日


相关VIP内容
专知会员服务
100+阅读 · 2019年11月23日
专知会员服务
104+阅读 · 2019年10月22日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年1月28日