Moments in Time:IBM-MIT联合提出最新百万规模视频动作理解数据集
来源:AI科技评论(公众号ID:AI科技评论)
在过去一年中,视频理解相关的领域涌现了大量的新模型、新方法,与之相伴的,今年也出现了多个新的大规模的视频理解数据集。近期,MIT-IBM Watson AI Lab 就推出了一个全新的百万规模视频理解数据集Moments-in-Time[1]。虽然没有之前的YouTube-8M数据集大,但应该是目前多样性,差异性最高的数据集了。该数据集的任务仍然为视频分类任务,不过其更专注于对“动作”的分类,此处的动作为广义的动作或动态,其执行者不一定是人,也可以是物体或者动物,这点应该是该数据集与现有数据集最大的区分。本文中简单的统称为“动作”。
本文主要对这篇数据集的论文进行介绍,数据集地址是http://moments.csail.mit.edu/。此外,该数据集也将参与ActivityNet Challenge 2018 (http://activity-net.org/challenges/2018/)作为其中的一个任务。
数据集概览
这部分主要对数据集的基本情况和特性进行介绍,大概可以总结为以下几点
共有100,0000 个视频,每个视频的长度相同,均为3s
每个视频有一个动作标签(后续版本可能拓展为多标签),此处的动作仅为动词,比如“opening”就为一个标签(与之不同,其他数据集经常采用动名词组的形式,如”openingthe door”)
动作主体可以是人,动物,物体乃至自然现象。
数据集的类内差异和类间差异均很大。
存在部分或完全依赖于声音信息的动作,如clapping(拍手)
由上述描述可以看出,由于超大的数据量以及多样性,这个数据集是相当难的,下图则为该数据集的一个例子。可以看出,一个动作类别可以由多种动作主体完成,从而从视觉上看的差异性相当的大,动作的概念可以说是相当抽象了。

下面我对作者构建这个数据集的方式进行介绍,这部分内容也有助于对该数据集的理解。
数据集的构建
1. 建立动作的字典
该数据集采用的是先确定动作标签,再根据动作标签构建视频集合的方式。构建动作标签集合,在该数据集中即构建一个合适的动作字典。主要通过以下几个步骤实现
参考【2】中的内容,选取4500个美式英语中最常用的动词
按照词义对这4500个词进行聚类,一个动词可以属于多个聚类
迭代的从最常见的聚类中选取最常见的动词加入目标字典
最终从4500个初始动词中选取339个最常见的动词作为字典
2. 数据收集与标注
在确定好动词字典后,作者对每个动词,在多个视频网站上进行视频的爬取。这里的视频网站比较多,包含YouTube,Flicker,Vine等十几个网站,比起只用YouTube的ActivityNet,Kinectic等数据集在来源的丰富性上要高不少。
在爬完数据后,每个视频都是以 视频-动词 对的形式呈现,标注工作的主要目的就是确定视频是否可以用动词描述,所以是一个二分类的标注任务(此处作者的解释是,多分类的标注对于标注者难度太高,也容易错,故采用二分类的标注方式)。标注工作在近来大量数据集都采用的Amazon Mechanical Turk (www.mturk.com)实现。
对于每个标注者,都会被分配64个待标注的动词-视频对以及10个已知真值的动词-视频对。在10个已知真值的动词-视频对中,只有标对9个及以上,该标注者的标注结果才会被认为是有效的。剩下的所有动词-视频对,都会被交由2个标注者,只有俩人的标注结果一致,该结果才会被采用。所以从标注角度来看,这个数据集的标签质量应该还是不错的。标注界面的样式如下图所示,可以看出还是相当简洁明了的。

数据集的数据分布
接下来我主要对该数据集的数据分布进行介绍,由于该数据集目前还没有正式放出,所以所有数据和图表均来自论文。
首先是数据集的类别分布:
对于339个动作类别,共有超过100000个标注视频
每个类别至少有1000个视频,每个类别视频数量的平均值是1757,中值是2775
类别与类别视频数量的关系图如下图所示。
接下来,作者介绍了数据集中动作主体的分布情况,如前所述动作主题可能是人,动物或一般物体。作者统计了不同类别视频中各类动作主题所占比例的分布,如下图所示。左侧的极端是“typing“,主体全部是人类,右边的极端是”overflowing”,动作主题基本不是人类。
最后,作者分析了数据集各个类别中依赖于声音的视频所在的比例。此处,依赖于声音的视频是指该视频无法从图像上判断出其包含的动作,而必须要听声音。从下图可以看出,有相当比例的视频是依赖于声音的,这点要增加了该数据集的挑战性。
场景、物体与动作之前的相关性探索
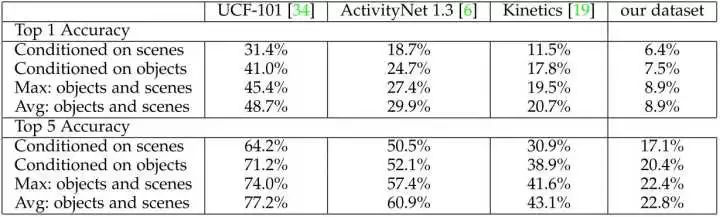
最后,作者通过一组简单的实验探索了各个数据集中 物体-场景-动作 之间的相关性。此处分析的视频数据集除了Moments in Time 还包括UCF-101, ActivityNet 1.3 以及Kinetics数据集。
这里的实验设置还蛮有趣的。作者分别采用了一个在ImageNet上训练的Resnet50 用于物体分类,一个在Places数据集上训练的Resnet50用作场景分类。对于每个视频,均匀抽取3帧并利用两个网络进行检测并平均结果,可以得到一个物体label以及一个场景label。对于物体或场景label,作者通过贝叶斯公式来推断对应的动作类别,其中先验概率在数据集的训练集上计算获得。
实验结果如下表所示,可以得到以下几点结论:
动作与场景以及物体均是相关的。
Moments in Time数据集中,动作与物体以及场景的相关性显著弱于其他几个数据集,这表明该数据集有更高的挑战性以及更大的难度。
个人讨论
Moments-in-Time 数据集我觉得还是相当有趣以及有挑战性的,估计很快就会有不少人跟进来做这个数据集(显而易见需要比较大的计算资源…)。下面是我对于该数据集的一些讨论内容,包括优点以及一些个人存在疑惑的地方。
优点:
数据集的大小和丰富程度很高,足以训练较复杂的视频分类模型。
视频的长度统一为3s,这样的设计方便实验时进行处理,也使得数据集的尺寸不至于过大。
数据标注的策略应该还是比较靠谱的,应该不太会有错误标注。
以上是几点明显的优点,但对于作者强调的几个数据集优点,我则存在一些疑惑:
仅用动词定义动作: 这个应该是这个数据集和其他数据集相比最大的一个差异点。作者认为通过该数据集能够学习一个泛化能力很强的动作概念,但在我看来这样的定义有些太过宽泛了。动词的含义常常依赖于其主语和谓语,单独的动词即便对于人类而言也常常是含义模糊的。此处可以参考今年ICCV上的【3】一文,我此前也写过一篇笔记(zhuanlan.zhihu.com/p/29227174)介绍这篇文章。这篇文章中一个重要的观点是,动作应该用动词-名词组合来定义,从而明确其含义。不过该数据集也是故意在此处模糊化从而增加类内差异,现在也不能够知道是否是一个好的设计了。
动作的主体不一定是人:这点也是数据集作者有意设计,从而增加难度以及多样性。我也持有同样的对于定义不清晰的疑惑,比如人开门(“opening”)和风吹开了一扇窗户(”opening“)放在同一个类别中总感觉不太合理。此外,此处还有一个问题,尽管温中给出了动作主体的分析,但通过询问作者,第一版的数据集不会提供动作主体的label,而仅包含一个动作label。
依赖声音的动作:这点我觉得倒是蛮好的,可以促进多模态方法的发展。但是同以上一点,该数据集在训练集中并没有告知这个视频中的动作是否是依赖与声音的。如果有相关的标签,我觉得会更有助于视频的理解吧。作者可能会在后续版本加上。
总体而言,这个新数据集还是很有趣且充满挑战的,与此前的多个主要关注人类动作的数据集在设定上有较大的差异。针对这个数据集,模型方面应该更注重于对动作概念的理解以及对较大的类内差异性的处理。期待之后针对该数据集的算法了。
参考文献
[1] Monfort M, Zhou B, Bargal S A, et al.Moments in Time Dataset: one million videos for event understanding[J].
[2] Salamon J, Jacoby C, Bello J P. Adataset and taxonomy for urban sound research[C]//Proceedings of the 22nd ACMinternational conference on Multimedia. ACM, 2014: 1041-1044.
[3] Sigurdsson G A, Russakovsky O, Gupta A.What Actions are Needed for Understanding Human Actions in Videos?[J]. arXivpreprint arXiv:1708.02696, 2017.
*推荐文章*
加入极市Email List (http://extremevision.mikecrm.com/pdKKGSx),获取极市最新项目需求,以及前沿视觉资讯等。






