【学界】 李飞飞学生最新论文:利用场景图生成图像
来源:AI科技评论
利用结构化场景图生成图像,能够明确解析对象与对象之间关系,并可生成具有多个可识别对象的复杂图像。
编者按:近日,李飞飞的学生 Justin Johnson 在 arXiv 上传了一篇论文:Image Generation from Scene Graphs(从场景图生成图像),提出利用结构化场景图而不是非结构化文本生成图像,该方法能够明确解析对象和对象之间关系,并可生成具有多个可识别对象的复杂图像。

为了能真正理解视觉世界,模型不仅要能够识别图像,还要能够生成它们。近期在自然语言描述生成图片方面取得了令人兴奋的进展。这些方法在有限的领域(例如鸟类或花卉的描述)上提供了令人惊叹的结果,但对于具有许多对象和关系的复杂句子却很难成功复制。为了克服这个限制,作者提出了一种从场景图生成图像的方法,能够明确地推理对象及其关系。作者开发的模型使用图形卷积来处理输入图,通过预测对象的边界框和分割掩模来计算场景布局,并且将布局转换为具有级联精化网络的图像。论文作者使用对抗训练网络对抗一组鉴别器,以确保实际输出图像足够逼真。实验通过 Visual Genome 和 COCO-Stuff 数据集验证了其方法,定性结果和用户实验复现证明了该方法能够生成具有多个对象的复杂图像。
我不理解的事物,我是不可能创造出来的。——Richard Feynman
创作行为的产生建立在深刻理解所创造的事物的基础之上。例如,厨师要比食客更深层理解食物,小说家要比读者更深层次理解写作,电影制作者要比影迷更深层次理解电影。如果让计算机视觉系统要真正理解视觉世界,它必须不仅能够识别图像,而且能够产生它们。
除了传递深刻的视觉理解之外,生成逼真图像的方法也可能在实践中有用。在短期内,自动图像生成可以帮助艺术家或图形设计师更好地工作。有一天,可能会根据每个用户的个人兴趣爱好,私人定制图像和视频,从而取代依靠算法的图像和视频搜索引擎。
作为实现这些目标的一个步骤,通过结合递归神经网络和生成对抗网络,从文本到图像的合成,从自然语言描述生成图像已经有令人兴奋的进展。(论文作者在 Google Cloud AI 实习期间已经完成了这项工作)
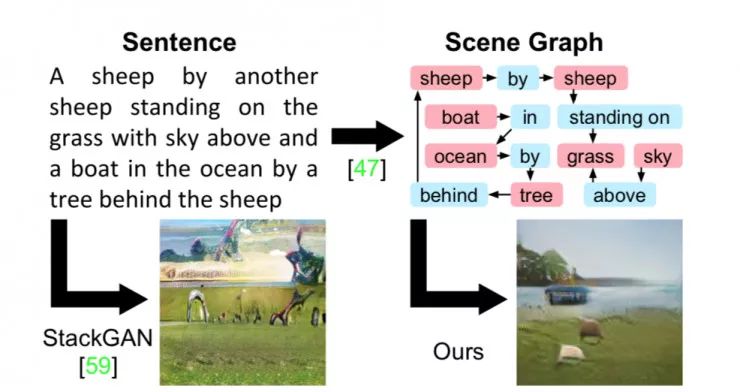
图 1
句子生成图像已经有一些最好的方法,例如 StackGAN ,但它很难用真实的方式刻画出有许多对象的复杂句子。论文作者通过从场景图生成图像来克服这个限制,可以明确地推断出对象及其关系。
这些方法可以在有限的区域上产生令人惊叹的效果,例如对鸟类或花朵的细致描述。然而,如图 1 所示,从句子生成图像的主要方法遇到包含许多对象的复杂句子并不能发挥很好的效果。
句子是线性结构,一个词接一个词;然而,如图 1 所示,复杂句子传达的信息通常可以作为场景图更明确地表示为对象及其关系。场景图是图像和语言的强大结构化表示;他们已经被用于语义图像检索;评估和改进图像字幕。其方法也被开发用于将句子转换成场景图并用于从图像到场景图的预测。
在本文中,作者旨在通过调整场景图的生成来生成具有多对象和关系复杂的图像,从而使模型能够明确地解释对象及其关系。
这项新任务带来了新的挑战。作者必须开发处理场景图输入的方法; 为此,他们使用一个图形卷积网络,沿着图形边缘传递信息。处理完图后,必须填补符号图形结构输入和二维图像输出之间的差距; 为此,通过预测图中所有对象的边界框和分割掩模来构建场景布局。预先设定好布局后,必须生成涉及它的图像; 为此,使用级联精化网络(CRN),它在不断增加的空间尺度下处理布局。最后,必须确保生成的图像真实并且包含可识别的对象; 因此针对一组用于图像补丁和生成对象的鉴别器网络进行对抗训练。模型的所有组件都以端到端的方式共同学习。
作者在两个数据集上进行实验:Visual Genome 提供了人工标注的场景图,COCO-Stuff [3] 则根据地面真实物体位置构建合成场景图。在这两个数据集上,都会展示定性结果,演示其方法生成复杂图像的能力。这些复杂图像涉及输入场景图的对象和关系,并执行全面的图像分割来验证模型的每个组件。
生成图像模型的自动评估本身就是一个具有挑战性的问题,所以通过两个亚马逊 Mechanical Turk 用户研究评估了实验结果。与 StackGAN 相比,这是一个领先的文本到图像合成系统,用户发现,该方法生成的结果在 68%的试验中能更好地匹配 COCO 字幕,并且包含 59%以上的可识别对象。
作者的目标是开发一个模型,将输入描述对象及其关系的场景图作为输入,并生成与该图对应的逼真图像。主要的挑战有三个:首先,必须开发一种处理图形结构输入的方法;其次,必须确保生成的图像涉及图形指定的对象和关系;第三,必须确保合成图像真实。
作者将场景图转换为图像生成网络 f 的图像,如图 2 所示,它输入场景图 G 和噪声 z 并输出图像 I = f(G,z)。
场景图 G 由一个图形卷积网络处理,该网络给出每个物体的嵌入矢量;如图 2 和图 3 所示,图层卷积的每个层沿着图的边缘混合信息。
我们通过使用来自图卷积网络的对象嵌入向量来预测每个对象的边界框和分割掩模,从而尊重来自 G 的对象和关系;这些结合在一起形成一个场景布局,如图 2 中间所示,它充当图形和图像域之间的中间层。
输出图像 I^是使用级联精化网络(CRN)从布局生成的,如图 2 右边所示。每个模块都在处理布局,增加空间尺度,最终生成图像 I^。我们通过对一对鉴别器网络 Dimg 和 Dobj 进行对抗训练 f 来生成逼真的图像,这些网络鼓励图像 I^看起来逼真。
关于实验中每一个组件更详细的描述,可查阅原论文:
https://arxiv.org/abs/1804.01622
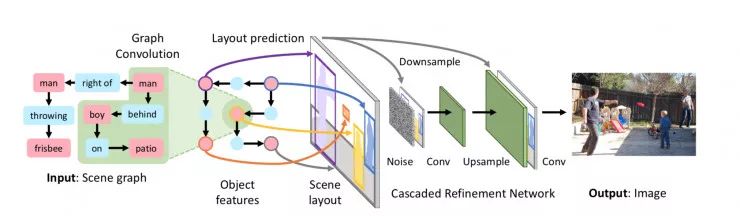
图 2:图像生成网络 f 用于从场景图生成图像的概述。模型的输入是指定对象和关系的场景图; 它用图形卷积网络(图 3)进行处理,该网络沿着边缘传递信息来计算所有对象的嵌入向量。这些向量被用来预测对象的边界框和分割掩模,它们被组合形成场景布局(图 4)。使用级联细化网络(CRN)将布局转换为图像 [6]。该模型是针对一对鉴别器网络进行敌对训练的。在训练期间,模型观察地面真实物体边界框和(可选)分割掩模,但是这些是在测试时由模型预测的。
图 3 中显示了单个图形卷积层的示例计算图。
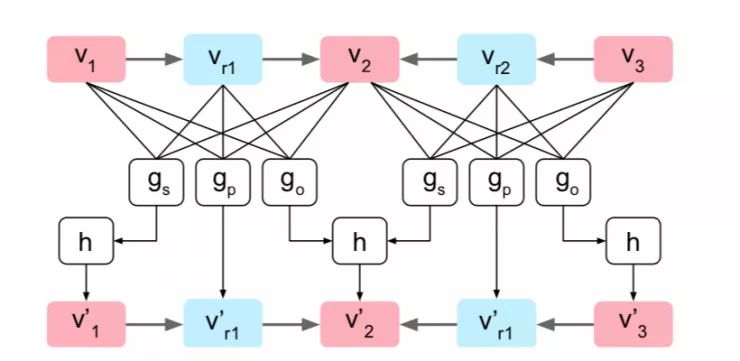
图 3:计算机图形表示单一的图形变化层。 该图由三个对象 o1,o2 和 o3 以及两个边(o1,r1,o2)和(o3,r2,o2)组成。 沿着每条边,三个输入向量被传递给函数 gs,gp 和 go; gp 直接计算边的输出矢量,而 gs 和 go 计算候选矢量,它们被馈送到对称池函数h以计算对象的输出矢量。
为了生成图像,必须从图域移动到图像域。为此,作者使用对象嵌入向量来计算场景布局,该场景布局给出了生成图像的粗略 2D 结构; 通过使用对象布局网络为每个对象预测分割掩码和边界框来计算场景布局,如图 4 所示。
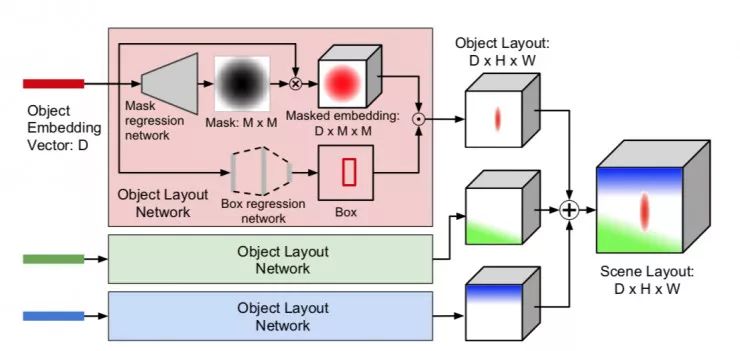
图 4
图 4 通过计算场景布局从图域转移到图像域。每个对象的嵌入向量被传递给一个对象布局网络,该网络预测对象的布局,总结所有对象布局给出场景布局。对象布局网络在内部预测一个软二进制分割掩码和一个对象的边界框; 这些与使用双线性插值的嵌入向量组合以产生对象布局。

图5
图 5 使用分别来自 Visual Genome(左四列)和 COCO(右四列)测试集的图形生成 64×64 图像为例。对于每个示例,都会显示输入场景图和手动将场景图转换为文本; 模型处理场景图并预测由所有对象的边界框和分割掩模组成的布局; 然后这个布局用于生成图像。作者还使用地面实况而非预测的场景布局显示了模型的一些结果。一些场景图具有重复的关系,如双箭头所示。为了清楚起见,忽略了某些东西类别的遮罩,如天空,街道和水。

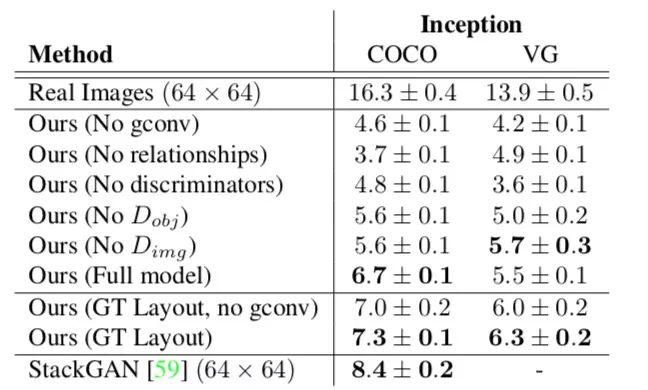
表 1
表 1 是使用 Inception 分数的消融研究。在每个数据集上,作者将测试集样本随机分成 5 组,并报告分组的平均值和标准差。在 COCO 上,通过构建不同的合成场景图,为每个测试集图像生成五个样本。对于 StackGAN,作者为每个 COCO 测试集字幕生成一个图像,并将其 256×256 输出下采样为 64×64,以便与论文中的方法进行公平比较。

表 2
表 2 是预测边界框的统计。R@t 是具有 t 的 IoU 阈值的对象调用,并且与地面实况框测量协议。σx 和 σ 分别通过计算每个对象类别中框 x 位置和面积的标准偏差,然后对各个类别进行求平均来测量框的变化。
图 5 显示了来自 Visual Genome 和 COCO 测试集的示例场景图以及使用论文作者方法生成的图像,以及预测的对象边界框和分割掩模。
从这些例子中可以清楚地看到,该方法可以生成具有多个对象的场景,甚至可以生成多个相同对象类型的实例:例如图 5(a)显示了两只羊,(d)显示了两辆巴士,(g)显示三个人,(i)显示两辆汽车。
这些例子还表明,该方法生成涉及输入图关系的图像; 例如(i)看到第二个西兰花左边有一个西兰花,第二个西兰花下面有一个胡萝卜; 在(j)中,该男子正在骑马,并且该男子的腿和马的腿都已经被适当定位。图 5 还显示了该方法使用的是地表实况而不是预测的对象布局生成的图像。
在某些情况下,该方法的预测布局可能与地面实况对象布局有很大差异。例如(k)图中没有指定鸟的位置,该方法使它站立在地面上,但是在地面真实布局中,鸟在天空中飞行。模型有时会受到布局预测的瓶颈,比如(n)使用地面实况而不是预测布局显着提高图像质量。
在图 6 中,通过从左侧的简单图形开始,逐步构建更复杂的图形来演示模型生成复杂图像的能力。从这个例子中,可以看到对象的位置受到图中关系的影响:在顶部序列中,添加「汽车在风筝下面」关系后,造成使汽车向右移动,风筝向左移动,从而风筝和汽车的关系也发生变化。在底部序列中,将关系「船在草地上」添加后,导致船的位置移位。
在本文中,作者开发了一种从场景图生成图像的端到端的方法。 与从文本描述生成图像的领先方法相比,作者提出的从结构化场景图而不是非结构化文本生成图像的方法能够明确地解析对象和对象之间关系,并生成具有多个可识别对象的复杂图像。
论文下载地址:
https://arxiv.org/abs/1804.01622
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】国科大本科生连续在CVPR,AAAI发文,系统提出三维模型库变形分析方法
☞【学界】密西根大学利用图像生成过程进行「数据增强」,以提高现实场景中「目标检测」的鲁棒性

