
即使有可靠的OCR模型,要回答需要在图片中阅读文字的问题,也对现有模型构成了一个挑战。其中最困难的是图片中经常有罕见字,多义字,比如地名,产品名,球队名。
为了克服这个困难,我们的模型利用了图片中多个模态的丰富信息来推测图片中文字的语义,例如酒瓶上显眼位置的字样很可能是酒名。
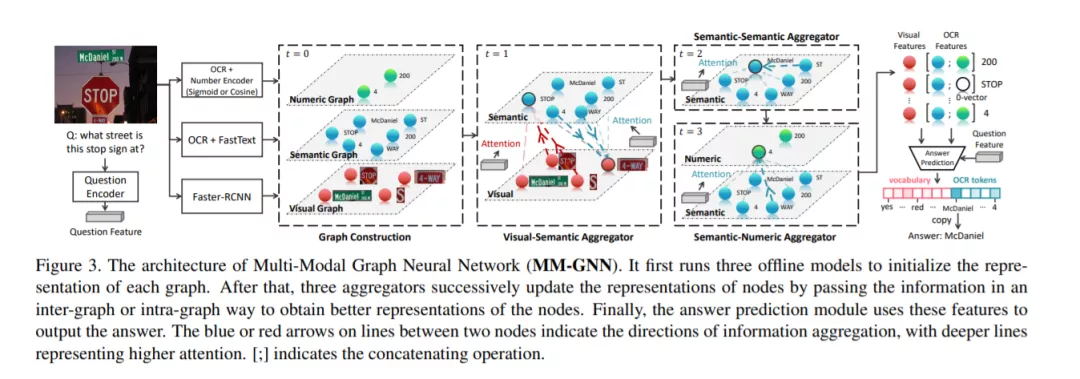
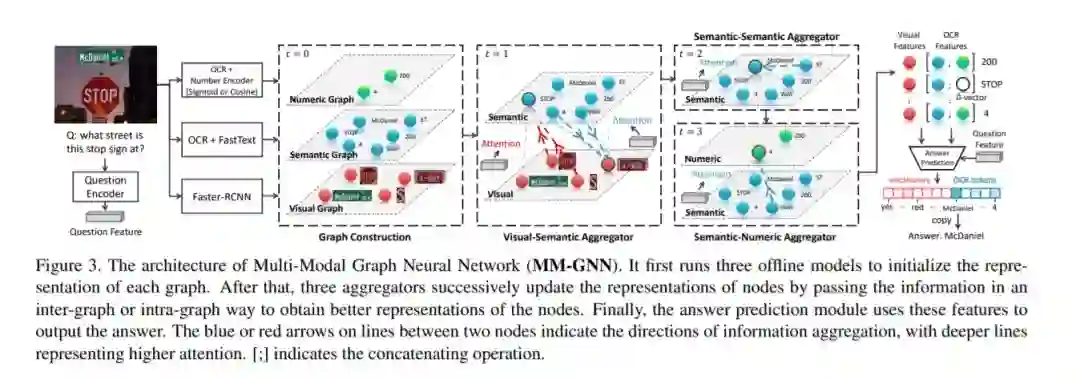
有了这样的直观感受,我们设计了一个新的VQA模型---多模态图神经网络(MM-GNN)。它会首先构建一个具有三个子图的特征节点图,分别描述视觉,文字,和数字模态。此后,我们设计了三个融合子,在子图间或子图内进行信息传递。增强过后的节点特征被证明可以很好地帮助下游任务,我们在ST-VQA和Facebook的Text-VQA上都取得了SOTA的成绩。
成为VIP会员查看完整内容
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日

相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日