【CVPR2018】物体检测中的结构推理网络
物体检测,是计算机视觉任务的基础,其精度将直接影响相关视觉任务的效果,在深度学习方法兴起之前,开展了很多利用场景上下文来提高检测精度的研究。近年来,随着Faster RCNN等深度学习方法的兴起,在日益强调数据和性能的背景下,对上下文关联信息的利用却鲜有尝试。本文将介绍一种结构推理网络(Structure Inference Net,简称SIN),将物体检测问题形式化为图结构推理,采用图结构同时建模物体细节特征、场景上下文、以及物体之间关系,采用门控循环单元(GRU)的消息传递机制对图像中物体的类别和位置进行联合推理。在基准数据集PASCAL VOC和MS COCO上的实验,验证了方法在精度提升方面的有效性,同时证实了上下文信息对于输出更为符合人类感知的检测结果确有帮助。
1.问题&动机

图1.Faster R-CNN检测器典型错误样例
目前的检测器一般在分类和位置回归时,只利用了兴趣区域内的视觉特征,尤其是两阶段检测器(将检测视为对候选区域的分类问题)。所以检测器就会出现图1中典型的检测错误(样例来自于Faster R-CNN方法)。左图将水中的船只误检成了汽车,如果能够利用全图的场景上下文信息,那可能检测器就不会认为水中是汽车了。右图漏检了鼠标,如果利用物体之间的关系,电脑和鼠标经常一起相邻出现,那么可能就能够推断到鼠标的存在了。
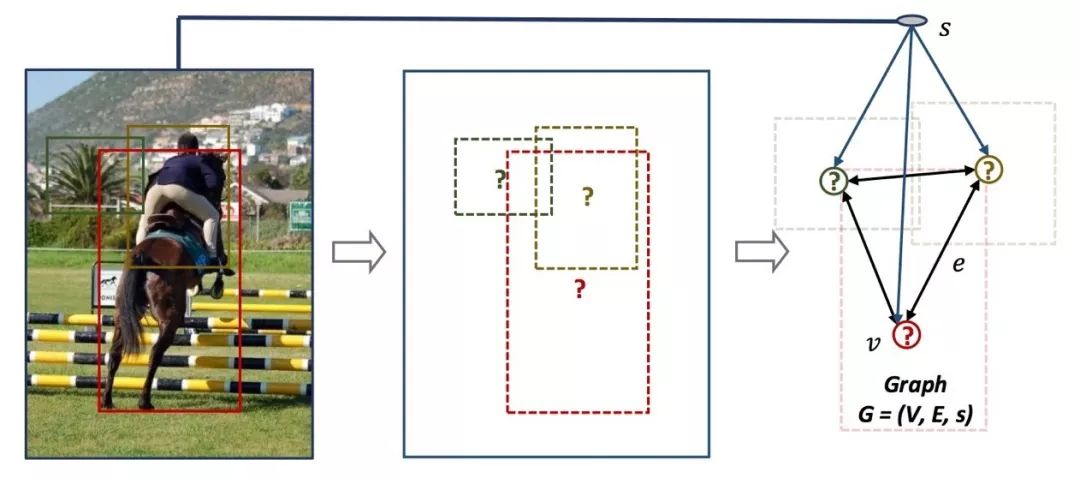
图2.图结构问题
自然而然,我们的动机就是不仅仅依赖物体视觉特征,同时利用场景上下文和物体关系来联合推理解决物体检测问题。我们认为自然场景图是一个有机的结构体,如图2所示,包含三种视觉概念分别是场景、物体、物体间关系。在场景的指导下,物体之间通过关系程度相互交互。所以我们将问题形式化为一个图结构G=(V,E,s),其中V是节点node代表ROI,E是边edge代表ROI之间的关系程度打分,s是场景scene描述。通过图结构中的元素联合推理交互,物体状态得到丰富的表示再用于分类和位置refine回归。下面首先需要对图结构中的三元素进行建模,再设计相应的交互机制来相互传递信息。
2.方法
理论上来说,我们的模块可以应用到各种框架上(单阶段和两阶段检测器)。这里我们使用Faster R-CNN作为基本框架,设计我们的结构推理网络,整体框架如图3所示。
2.1 图结构建模
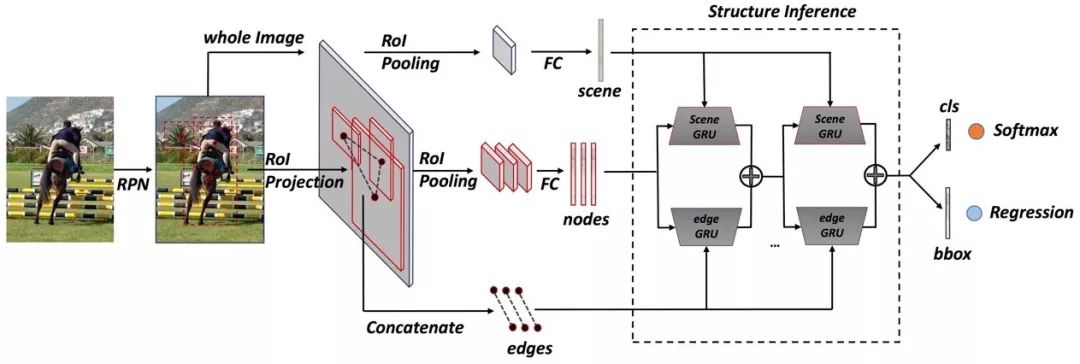
图3.方法框架
其中,scene是场景,这里没有场景标签,所以用全图特征来建模。node是ROI,也就是RPN的生成结果,选取固定数目128个ROIs。edge是物体间的关系,这里是一个标量相当于一个打分,用ROI之间的视觉特征和位置关系同时建模,表达关系的时候距离很重要,具体是什么东西也很重要,例如对于键盘来说,同样近的鼠标比杯子更重要。
2.2 交互机制
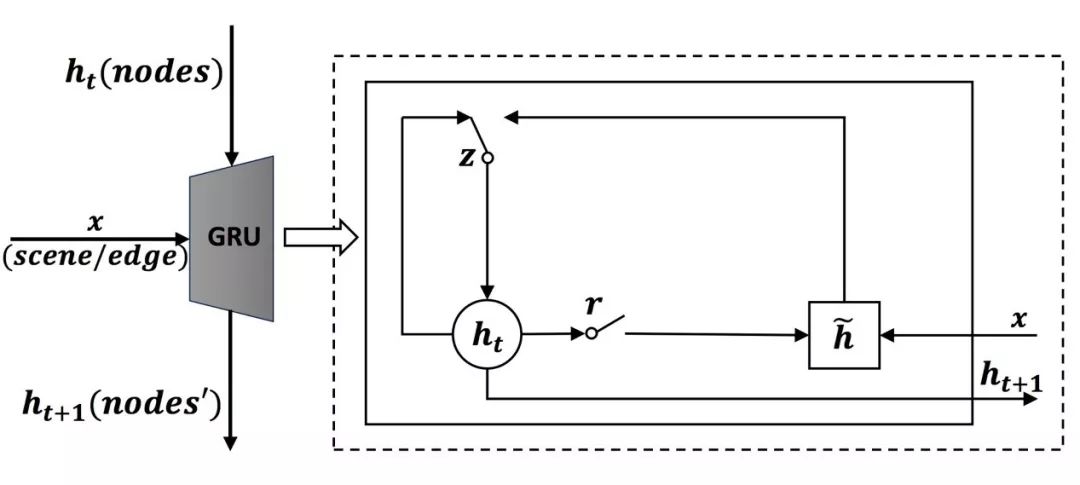
图4.消息传递机制
在场景指导下,物体之间通过关系程度相互交互,其实就是物体接收场景的指导信息,每个物体接收其他物体传递来的信息,只不过关系不同,接收程度不同。所以交互机制也就是消息传递,我们这里采用GRU来实现,如图4所示。例如当前物体需要接受场景的信息,那么将当前物体的状态作为隐状态,场景信息作为输入,输出即接收信息更新后的物体状态;同理当物体需要接受其他物体的信息,同样将当前物体状态作为隐状态,其他物体传递来的信息作为输入,输出即更新后的物体状态。GRU的Gate结构可以使得隐状态丢弃与输入无关的部分,也可以选择与输入相关的部分根据输入来更新隐状态。所以GRU本身是一种很巧妙的实现消息传递的方式。
2.3 结构推理
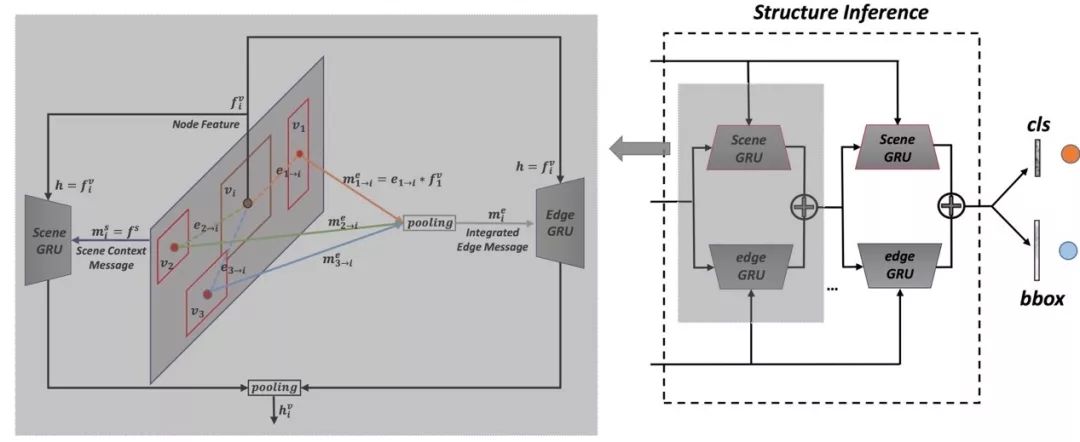
图5.结构推理模块
对于当前node vi,左边scene GRU接收场景信息,将node特征作为隐状态,场景特征作为信息输入。右边edge GRU接收其他物体的信息,通过关系程度计算每个物体传递的信息,再pooling所有物体传递来的整合信息,将整合后的信息传递到当前node。两种GRU的输出融合为最终的状态表达,作为物体状态。当物体状态更新后,物体之间的关系发生变化,更多次的信息交互迭代可以更鲁棒的表示物体状态。
3.实验结果
文章的实验中详细分析了单独应用场景、单独应用物体间关系各自所带来的效果,以及二者结合的整体表现。在这里,我们只简单展示SIN的一些定量结果和定性的结果,更多的实验分析与结果可以参考论文。
3.1 定量结果
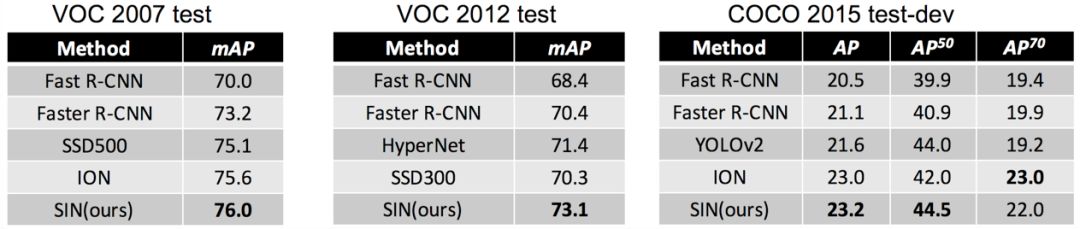
表1.各数据集检测结果
相比于基准模型Faster R-CNN,可以发现在多个基准数据集上均有较为明显的性能提升,这里使用的是VGG-16模型。
3.2 定性结果
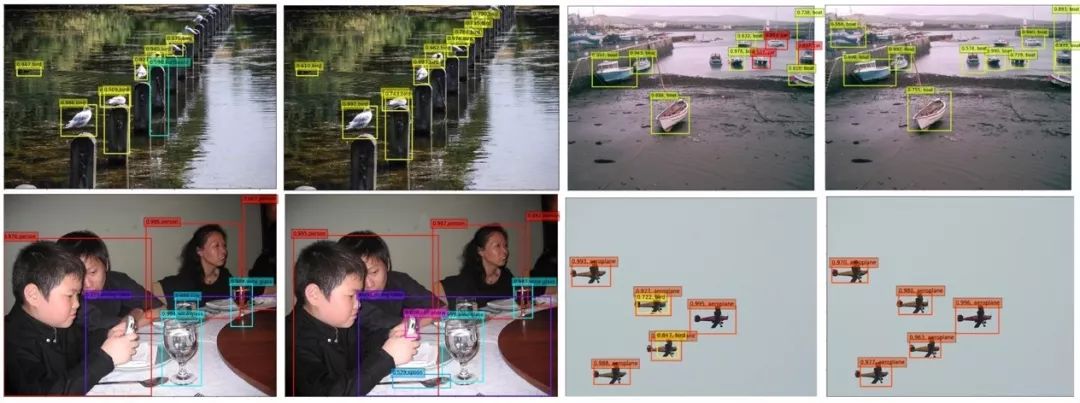
图6.定性结果对比(左:faster R-CNN baseline 右:SIN)
部分检测结果如图6。左上角样例中,基准模型把石板误检为surfboard,尽管其表观确实有点相似;而通过应用场景和关系,我们的方法避免了这样的错误,而且能够检测到更多的鸟儿。右上角样例中,我们的方法可以正确检测水中的船只。左下角样例中,我们的方法能够检测到小孩手里的手机,桌子上的勺子等。右下角样例中,Faster R-CNN经常会对一个ROI预测出多个可能的类别,我们的方法则能够很好的避免这个问题。
4.结论&展望
文章初步验证了当前主流的检测框架下,应用场景和物体之间关系能够有效的帮助提高检测性能。在未来更大规模的数据库上,我们认为应用场景信息和关系能够对检测发挥更大的作用,我们将进一步验证尝试。同时在更强的网络框架上,以及在单阶段的检测器上如何有机嵌入推理模块也将做出更进一步的尝试与探索。
更多细节详见代码&论文:
https://github.com/choasup/SIN
http://vipl.ict.ac.cn/view_database.php?id=6
参考文献:
Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, "Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships," IEEE Conference on Computer Vision and Pattern Recognition(CVPR2018), pp. 6985-6994, Salt Lake City, UT, June 18-22, 2018.
主编:袁基睿,编辑:程一
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 Emily_0167。
作者简介:

刘永,中科院计算所VIPL课题组硕士研究生,导师为王瑞平研究员。研究方向是物体检测,相关成果在CVPR2018发表论文一篇。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站

