CVPR 2019 | 旷视研究院提出TACNet,刷新时空动作检测技术新高度

全球计算机视觉三大顶级会议之一 CVPR 2019 将于当地时间 6 月 16-20 日在美国洛杉矶举办。届时,旷视研究院将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会介绍一篇被 CVPR 2019 接收的论文,本文是第 11 篇,旷视研究院(R4D组)出一个过渡感知的上下文网络——TACNet,可以显著提升时空动作检测的性能。

论文名称:TACNet: Transition-Aware Context Network for Spatio-Temporal Action Detection
论文链接:https://arxiv.org/abs/1905.13417
导语
简介
模型
框架
时序上下文检测器
过渡感知分类器
实验
与当前最佳的对比
结论
参考文献
往期解读
导语
在时空动作检测(spatio-temporal action detection)领域,当前最佳方法效果优秀,但是在一些方面,比如时序事件检测,依然无法令人满意。原因在于,一些模糊不清的、和真实动作很相似的动作被当作目标动作来处理,即使训练良好的网络也概莫能外。
旷视研究员把这些模糊不清的样本称之为“过渡性状态”,并提出一个过渡感知的上下文网络——TACNet,来辨识这些过渡状态。TACNet 包含两个关键组件:时序上下文检测器和过渡感知分类器。前者通过构建一个循环检测器,可以从连续的时间复杂度中提取长期的上下文信息;后者则通过同时分类动作和过渡性状态以进一步区分过渡性状态。
因此,TACNet 可以显著提升时空动作检测的性能。大量实验也在 UCF101-24 和 J-HMDB 数据集上证明 TACNet 有效,它不仅在剪辑的 J-HMDB 数据集上取得有竞争力的结果,还在未剪辑的 UCF101-24 数据集上 frame-mAP 和 video-mAP 两个指标方面大幅超越当前最佳方法。
简介
动作检测任务旨在同时分类视频中当前的动作并对其进行时空定位,近期由于其广泛的应用场景,受到了越来越多研究者的重视,并成长为异常检测、人机交互、城市管理等领域的关键技术。
当前,绝大多数动作检测方法把时空检测分为两个阶段,即空间检测和时序检测。这些方法首先借助深度检测器从帧中做空间动作检测;接着,通过连接帧层面的检测以及运用一些目标函数,执行时序检测以创造时空行为块。
这些方法把视频帧看作是一个个独立图像,从而无法利用视频的时间连续性,因此其检测结果实际上无法令人满意。
为此,一种称之为 ACT 的方法则通过堆栈策略捡起短期的时间连续性,显著提升时空动作检测的性能。但是,ACT 依然无法提取对于动作检测而言异常关键的长期的时序上下文信息。进而,由于动作检测的两个阶段相互分离,ACT 无法彻底纠正由含糊的样本所造成的时间误差,如图 1 红框所示。

▲ 图1:过渡性状态图示
本文把含糊的样本定义为“过渡性状态”,它与动作持续时间很接近,但并不属于动作的范畴。根据 ACT 检测器的误差分析,35%-40% 的误差是时间误差,它主要由过渡性状态造成。因此,如果要进一步提升时空动作检测的性能,提取长期的语境信息并区分过渡性状态就变得十分关键。
上述发现开启了本文工作。具体而言,旷视研究员提出一个过渡感知上下文网络——TACNet,它包含两个核心组件,即时序语境检测器和过渡感知分类器,前者的设计是基于标准的 SSD 框架,但是通过嵌入若干个多尺度的双向 Conv-LSTM 单元可以编码长期的语境信息(据知,把 Conv-LSTM 和 SSD 相结合,以打造一个用于动作检测的训练检测器,这是第一次);后者则通过同时分类动作和动作状态,以区分过渡性状态。
更为重要的是,旷视研究院进一步提出一个共模和差模网络加速 TACNet 的收敛,从而使 TACNet 不仅可以提取长期的时序上下文信息,还能区分过渡性状态。在UCF101-24 和 J-HMDB 两个数据集上,TACNet在帧和视频两项指标上均取得了引人注目的提升。
TACNet 框架
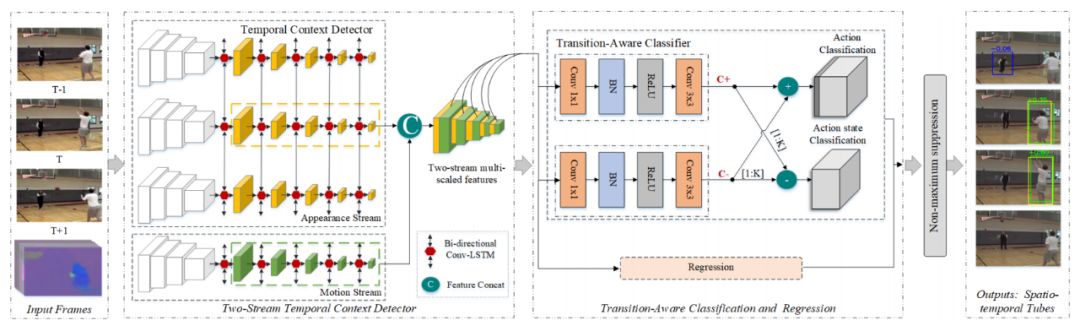
▲ 图2:TACNet整体架构
如图 2 所示,TACNet 包含两个模块,双流的时序上下文检测和过渡感知的分类和回归。在时序语境检测器方面,旷视研究员使用双流 SSD 做动作检测,正如 ACT 检测器那样。尽管如此,为提取长期的时序语境信息,旷视研究员还嵌入若干个双向 Conv-LSTM 单元到不同的特征图(不同尺寸)。
在过渡感知分类器方面,为区分过渡性状态,旷视研究员设计两个分类器以同时分类动作和动作状态,并进一步提出一个共模和差模的网络方案,加速 TACNet 整体的收敛。
通过与回归相结合,过渡感知分类器可从空间上检测动作,同时从时间上预测时序边界。需要注意的是,本文基于的则是标准的 SSD,但实际可在不同的检测器基础上进行设计。
时序上下文检测器
长期的时序上下文信息对时空动作检测来说至关重要。然而,标准 SSD 是从不同大小的多个特征图中执行动作检测的,它并不考虑时序语境信息。为提取时序语境,旷视研究员在 SSD 中嵌入 Bi-ConvLSTM 单元,以设计一个检测动作的循环检测器。
作为 LSTM 的一种,ConvLSTM 可以编码长期的信息,并更适宜处理视频这样的数据,因为 ConvLSTM 单元可以用卷积操作替代 LSTM 单元中全连接的相乘操作,从而能随着时间保持帧的空间结构。因此,在本文框架中使用 ConvLSTM 单元提取长期时序信息是可行的。
具体而言,旷视研究员在 SSD 每两个相邻层之间嵌入一个 Bi-ConvLSTM 单元,形成一个时序语境检测器,如图 2 所示。本文考虑了前向与反向两个输入序列,并为此采用一对时序对称 ConvLSTM;接着,旷视研究员借助这一 Bi-ConvLSTM 从每一个视频帧获取两类特征,这些特征被 1 × 1 卷积层连接和转换,以消除多余的通道。
通过这种方法,时序上下文检测器可以利用 SSD 的优势,并提取长期时序语境信息。
过渡感知分类器
过渡性状态中的实例与目标动作具有相似性,因此检测较容易发生混淆。大多数现有方法将其作为背景,并依赖后处理算法剪裁它们。然而,由于这些状态与背景非常不同(比如场景和其他目标),将其看作背景会加大类内差异,降低检测性能。在本文中,旷视研究院提出一个过渡感知的分类器,以同时进行动作分类和过渡状态分类,具体细节如图 3 所示:
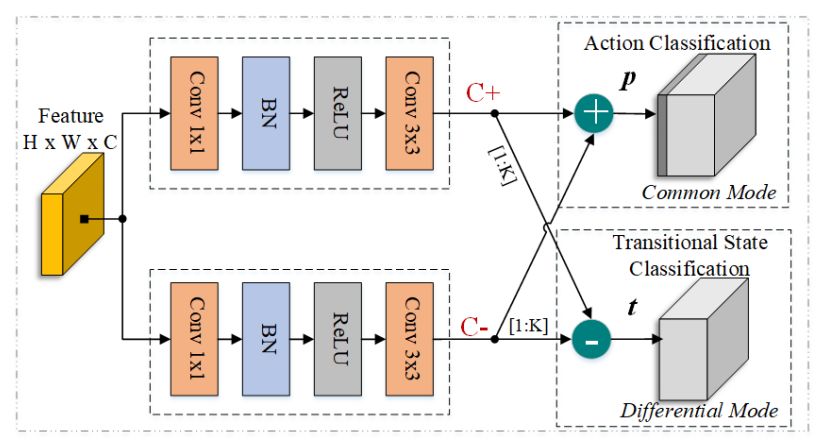
▲ 图3:过渡感知分类器图示
实验
与当前最佳的对比
在 frame-mAP 和 video-mAP 两个指标上,本文把 TACNet 与当前最优方法在数据集 J-HMDB 和 UCF101-24 上做了对比,结果如表 3 所示。由表可知,在时序未经修剪的 UCF101-24 数据集上,TACNet 在两个指标上均超越了先前同类方法。
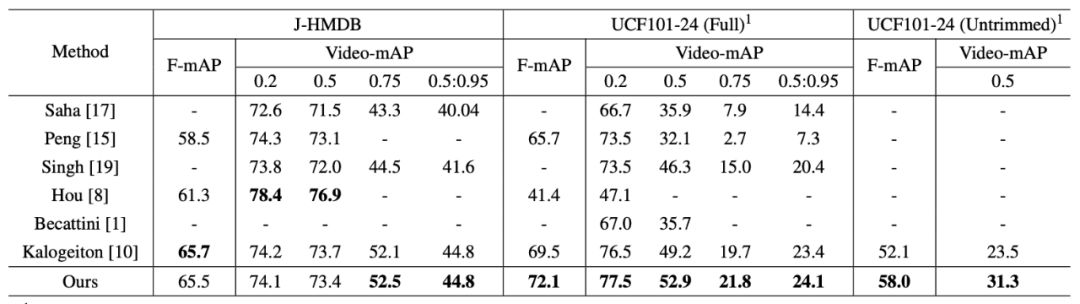
▲ 表3:在J-HMDB和UCF101上,TACNet与当前最佳方法的结果对比
结论
本文旨在推进动作检测的性能。具体而言,旷视研究员发现,提取长期的时序上下文分析并区分过渡性状态十分关键。由此,旷视研究院提出 TACNet,它包含一个时序上下文检测器和一个过渡感知分类器。
由大量的实验结果可知,TACNet 异常奏效,并在有挑战性的、未剪辑的数据集上刷新了当前最佳结果,这主要得益于 TACNet 使用的时序检测和过渡感知方法。
未来,旷视研究院将从行为者与其周遭的人物(或物体)的关系着手,持续探索,进一步提升时序检测的能力。
传送门
欢迎各位同学关注旷视研究院 Detection 组及知乎专栏:
http://zhuanlan.zhihu.com/c_1065911842173468672
简历可以投递给 Detection 组负责人俞刚:
yugang@megvii.com
参考文献
[1] V. Kalogeiton, P. Weinzaepfel, V. Ferrari, and C. Schmid. Action tubelet detector for spatio-temporal action localization. In ICCV, 2017.
[2] Z. Li, K. Gavrilyuk, E. Gavves, M. Jain, and C. G. Snoek. Videolstm convolves, attends and flows for action recognition. Computer Vision and Image Understanding, 166:41– 50, 2018.
[3] X. Peng and C. Schmid. Multi-region two-stream r-cnn for action detection. In ECCV, pages 744–759, 2016.
[4] G. Singh, S. Saha, M. Sapienza, P. Torr, and F. Cuzzolin. Online real-time multiple spatiotemporal action localisation and prediction. In CVPR, pages 3637–3646, 2017.
[5] G. Yu and J. Yuan. Fast action proposals for human action detection and search. In CVPR, pages 1302–1311, 2015.
[6] K. Soomro, A. R. Zamir, and M. Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
[7] H. Jhuang, J. Gall, S. Zuffi, C. Schmid, and M. J. Black. Towards understanding action recognition. In ICCV, pages 3192–3199, 2013.
往期解读:

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐
