
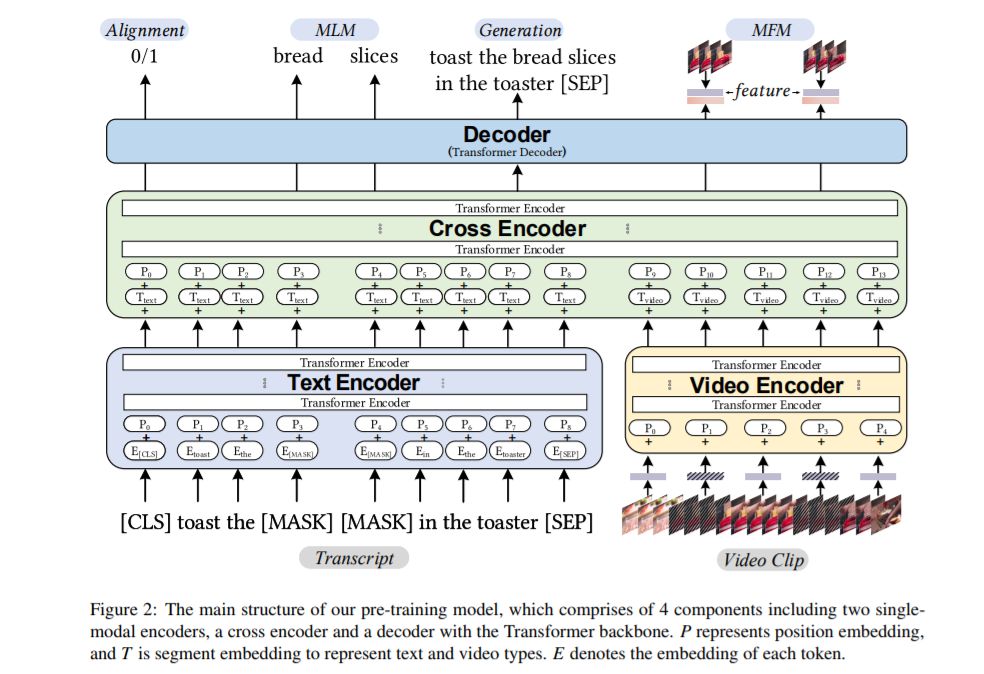
我们提出UniViLM:一个用于多模态理解和生成的统一视频和语言预训练模型。最近,基于BERT的NLP和图像语言任务预训练技术取得了成功,受此启发,VideoBERT和CBT被提出将BERT模型用于视频和语言预训练,并使用叙事性教学视频。不同于他们的工作只训练理解任务,我们提出了一个统一的视频语言理解和生成任务的预训练模型。我们的模型由4个组件组成,包括两个单模态编码器、一个交叉编码器和一个带Transformer主干的译码器。我们首先对我们的模型进行预训练,以学习视频和语言在大型教学视频数据集上的通用表示。然后,我们在两个多模态任务上对模型进行微调,包括理解任务(基于文本的视频检索)和生成任务(多模态视频字幕)。我们的大量实验表明,我们的方法可以提高理解和生成任务的性能,并取得了最先进的结果。
成为VIP会员查看完整内容
相关内容

专知会员服务
36+阅读 · 2020年5月20日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
3+阅读 · 2019年7月11日


相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
3+阅读 · 2019年7月11日