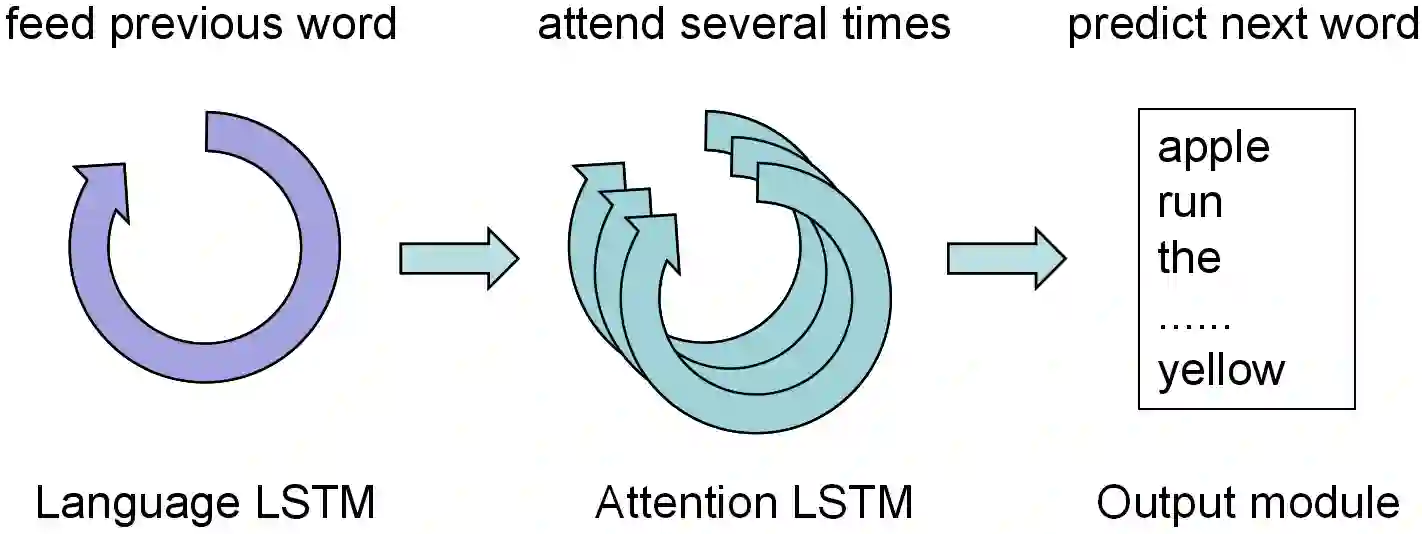
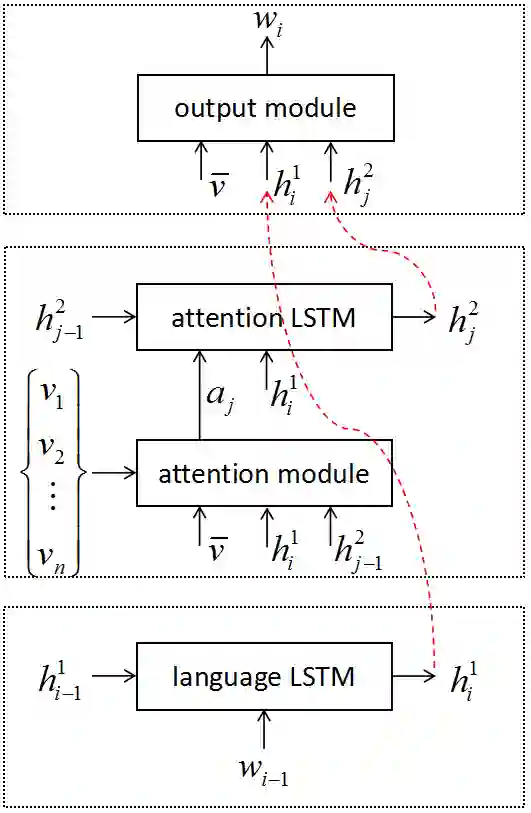
Most attention-based image captioning models attend to the image once per word. However, attending once per word is rigid and is easy to miss some information. Attending more times can adjust the attention position, find the missing information back and avoid generating the wrong word. In this paper, we show that attending more times per word can gain improvements in the image captioning task. We propose a flexible two-LSTM merge model to make it convenient to encode more attentions than words. Our captioning model uses two LSTMs to encode the word sequence and the attention sequence respectively. The information of the two LSTMs and the image feature are combined to predict the next word. Experiments on the MSCOCO caption dataset show that our method outperforms the state-of-the-art. Using bottom up features and self-critical training method, our method gets BLEU-4, METEOR, ROUGE-L and CIDEr scores of 0.381, 0.283, 0.580 and 1.261 on the Karpathy test split.
翻译:多数关注的图像字幕模型对图像每个单词都关注一次。 但是, 一次访问每个单词是僵硬的, 容易丢失某些信息 。 更多时间的处理可以调整关注位置, 找到缺失的信息, 避免生成错误的单词 。 在本文中, 我们显示每个单词多关注一次可以改进图像字幕任务 。 我们提议一个灵活的两个LSTM 合并模型, 以便于将更多的注意力比单词进行编码 。 我们的字幕模型使用两个LSTM 来分别对单词序列和注意序列进行编码 。 两个 LSTM 和图像特征的信息可以合并来预测下一个单词 。 对 MSCO 字幕数据集的实验显示, 我们的方法比最新工艺要好 。 使用自下而上的特点和自我批评的培训方法, 我们的方法在 Karpathic 测试分法上得到了 BLEU-4、 METEOR、 ROUGEL 和 CIDER 分数为0. 381、 0. 283、 0. 0. 580 和 1. 261 。