资源 | 谷歌发布人类动作识别数据集AVA,精确标注多人动作
选自Google Research
机器之心编译
参与:路雪
视频人类动作识别是计算机视觉领域中的一个基础问题,但也具备较大的挑战性。现有的数据集不包含多人不同动作的复杂场景标注数据,今日谷歌发布了精确标注多人动作的数据集——AVA,希望能够帮助开发人类动作识别系统。
教机器理解视频中的人类动作是计算机视觉领域中的一个基础研究问题,对个人视频搜索和发现、运动分析和手势交流等应用十分必要。尽管近几年图像分类和检索领域实现了很大突破,但是识别视频中的人类动作仍然是一个巨大挑战。原因在于动作本质上没有物体那么明确,这使得我们很难构建精确标注的动作视频数据集。尽管很多基准数据集,如 UCF101、ActivityNet 和 DeepMind Kinetics,采用了图像分类的标注机制,并为数据集中的每一个视频或视频片段分配一个标签,但是仍然不存在包含多人不同动作的复杂场景的数据集。
为了推进人类动作识别方面的研究,谷歌发布了新的数据集 AVA(atomic visual actions),提供扩展视频序列中每个人的多个动作标签。AVA 包括 YouTube 公开视频的 URL,使用包含 80 个原子动作(atomic action)集进行标注(如「走路」、「踢(某物)」、「握手」),所有动作都有时空定位,从而产生 57.6k 视频片段、96k 标注人类动作和 210k 动作标签。你可以点击 https://research.google.com/ava/ 查看 AVA 数据集并下载标注。论文地址:https://arxiv.org/abs/1705.08421。
与其他动作数据集相比,AVA 具备以下关键特征:
以人类为中心的标注。相比于视频或片段,每个动作标签都与人类更加相关。因此,我们能够向同一场景中执行不同动作的多人分配不同的标签,而这种场景非常常见。
原子视觉动作(Atomic visual actions)。我们将动作标签限制在固定的时间长度(3 秒),所有动作都是物理动作且有清晰的视觉信号(visual signature)。
真实的视频材料。我们使用不同类型和国家的电影作为 AVA 的数据源。因此,数据覆盖大范围的人类行为。

3 秒视频片段示例,每个片段的中间帧都有边界框标注。(为清晰起见,每个示例仅显示一个边界框。)
为创建 AVA,我们首先从 YouTube 上收集了大量多样化的数据,主要集中在「电影」和「电视」类别,选择来自不同国家的专业演员。我们对每个视频抽取 15 分钟进行分析,并统一将 15 分钟视频分割成 300 个非重叠的 3 秒片段。采样遵循保持动作序列的时间顺序这一策略。
接下来,我们为每个 3 秒片段中间帧的人物手动标注边界框。对标注框中的每个人,标注者从预制的原子动作词汇表(80 个类别)中选择适当数量的标签来描述人物动作。这些动作可分为三组:姿势/移动动作、人-物互动和人-人互动。我们对执行动作的所有人进行了全部标注,因此 AVA 的标签频率遵循长尾分布,如下图所示。
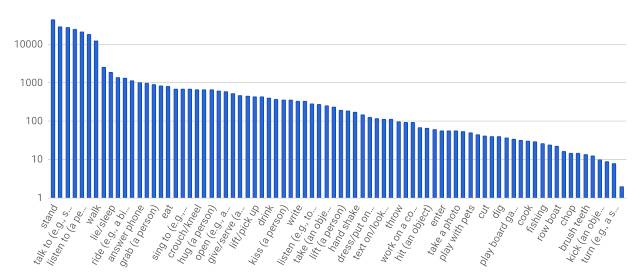
AVA 的原子动作标签分布。x 轴所示标签只是词汇表的一部分。
AVA 的独特设计使我们能够获取其他现有数据集中所没有的一些有趣数据。例如,给出大量至少带有两个标签的人物,我们可以判断动作标签的共现模式(co-occurrence pattern)。下图显示 AVA 中共现频率最高的动作对及其共现得分。我们确定的期望模式有:人们边唱歌边弹奏乐器、拥吻等。
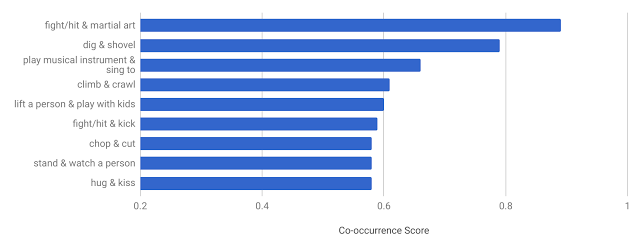
AVA 中共现频率最高的动作对。
为评估基于 AVA 数据集的人类动作识别系统的高效性,我们使用一个现有的基线深度学习模型在规模稍小一些的 JHMDB dataset 上取得了具备高竞争性的性能。由于存在可变焦距、背景杂乱、摄影和外观的不同情况,该模型在 JHMDB dataset 上的性能与在 AVA 上准确识别动作的性能(18.4% mAP)相比稍差。这表明,未来 AVA 可以作为开发和评估新的动作识别架构和算法的测试平台。
我们希望 AVA 的发布能够帮助人类动作识别系统的开发,为基于个人动作精确时空粒度的标签对复杂活动进行建模提供了机会。我们将持续扩展和改进 AVA,并且很乐意获取社区反馈以帮助我们校正未来方向。加入 AVA 用户邮件列表(https://groups.google.com/forum/#!forum/ava-dataset-users)即可获取 AVA 数据集更新。
原文地址:https://research.googleblog.com/2017/10/announcing-ava-finely-labeled-video.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




