图神经网络(GNN)是在机器学习中利用图结构数据的强大工具。图形是一种灵活的数据结构,可以为许多不同类型的关系建模,并已被用于各种应用,如交通预测、谣言和假新闻检测、疾病传播建模,以及理解为什么分子有气味。
作为机器学习(ML)的标准,GNN假设训练样本是均匀随机选择的(即,是一个独立的、同分布的或“IID”样本)。对于标准的学术数据集来说,这很容易做到,这些数据集是专门为研究分析而创建的,因此每个节点都已经标记好了。然而,在许多现实世界的场景中,数据没有标签,而对数据进行标签可能是一个涉及熟练的人员的繁重过程,这使得对所有节点进行标签变得困难。此外,有偏差的训练数据是一个常见的问题,因为选择节点进行标注的行为通常不是IID。例如,有时会使用固定的启发式来选择数据子集(共享一些特征)进行标记,而其他时候,人类分析人员会使用复杂的领域知识单独选择数据项进行标记。

为了量化训练集中出现的偏差量,可以使用测量两个不同概率分布之间的偏移有多大的方法,其中偏移的大小可以被认为是偏差量。随着迁移规模的增大,机器学习模型更难从有偏训练集推广。这种情况可能会严重损害泛化性——在学术数据集上,我们已经观察到领域的转移导致了15-20%的性能下降(以F1分数衡量)。
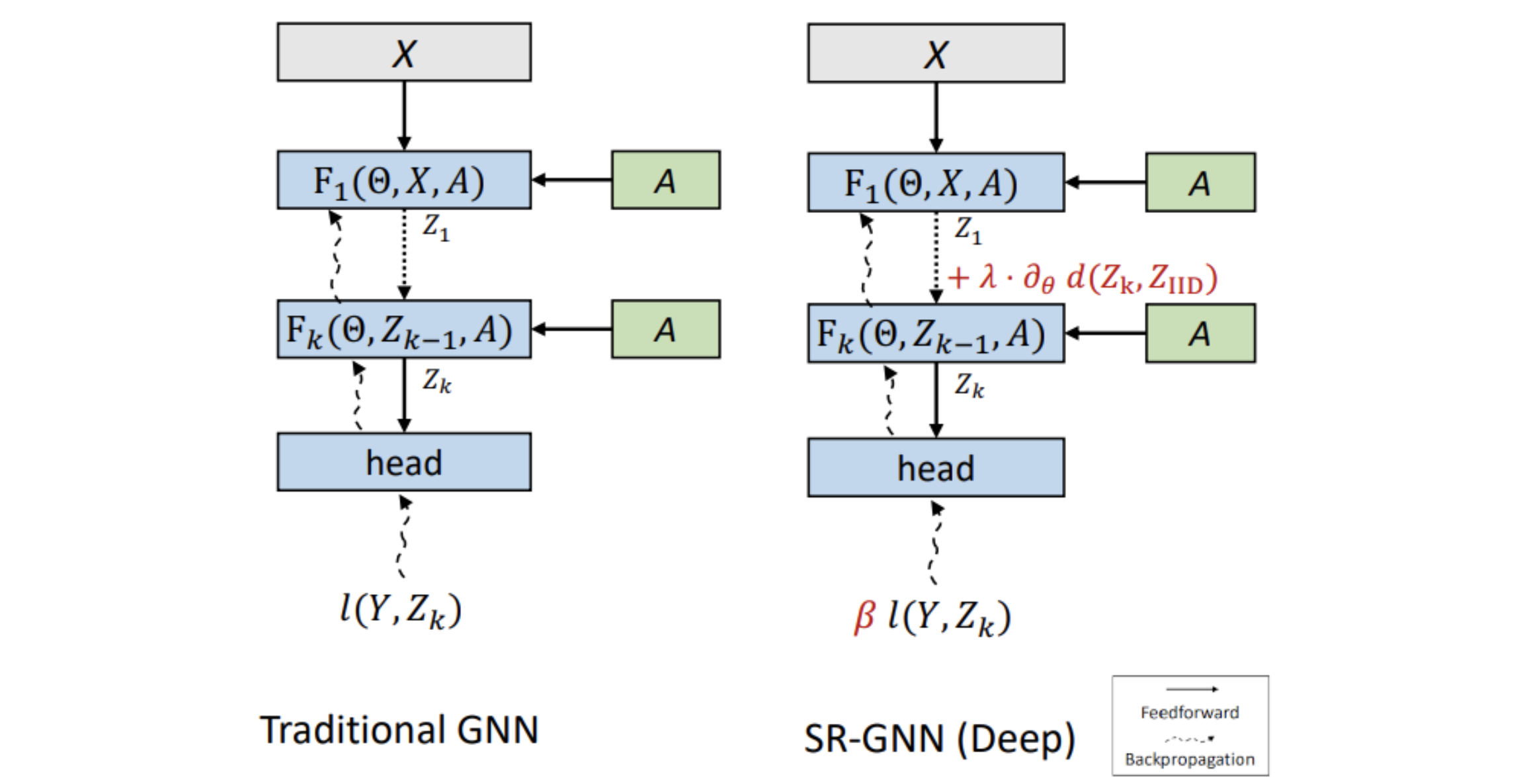
在NeurIPS 2021会议上发表的“位移鲁棒GNN:克服局部化图训练数据的局限性”中,我们介绍了在有偏数据上使用GNN的解决方案。该方法被称为移位鲁棒GNN (SR-GNN),旨在考虑有偏训练数据和图的真实推理分布之间的分布差异。SR-GNN使GNN模型适应于标记为训练的节点和数据集的其余部分之间的分布转移的存在。我们在半监督学习的常见GNN基准数据集上使用有偏训练数据集进行的各种实验中说明了SR-GNN的有效性,并表明SR-GNN在准确性方面优于其他GNN基准,将有偏训练数据的负面影响减少了30-40%。