©作者 | 范少华
单位 | 北邮 GAMMA Lab
研究方向 | 图神经网络
目前提出的图神经网络 (GNN) 方法没有考虑训练图和测试图之间的不可知偏差,从而导致 GNN 在分布外(OOD)图上的泛化性能变差。导致 GNN 方法泛化性能下降的根本原因是这些方法都是基于 IID 假设。在此条件下,GNN 模型倾向于利用图数据中的虚假相关进行预测。但是,这样的虚假相关可能在未知的测试环境中改变,从而导致 GNN 的性能下降。因此,消除虚假相关的影响对于实现稳定的 GNN 模型至关重要。
为了实现此目的,在本文中,我们强调对于图级别任务虚假相关存在于子图级别单元,并且用因果视角来分析 GNN 模型性能下降的原因。基于因果视角的分析,我们提出了一个统一的因果表示框架用于稳定 GNN 模型,称之为 StableGNN。这个框架的主要思想是首先利用一个可微分的图池化层提取图的高层语义特征,然后借助因果分析的区分能力来帮助模型摆脱虚假相关的影响。因此,GNN 模型可以更加专注于有区分性的子结构和标签之间的真实相关性。我们在具有不同偏差程度的仿真数据和 8 个真实的 OOD 图数据上验证了我们方法的有效性。此外,可解释性实验也验证了 StableGNN 可以利用因果结构做预测。
论文标题:
Generalizing Graph Neural Networks on Out-Of-Distribution Graphs
论文链接:
https://arxiv.org/abs/2111.10657
引言
图神经网路 (GNNs) 是在各种图数据应用上强有力的深度学习算法。其中一种主要的应用是图级别的任务,比如分子图级别的预测,情境图分类,和社交网络图分类。目前 GNN 方法的基本学习范式是从训练图中学习 GNN 的参数然后将其用于预测未知的图数据。保证如此学习模式成功的最基本假设是 IID 假设,即训练和测试数据是从相同的数据分布中抽取出来的。然而,在现实中这种假设由于真实据收集过程中的不可控性很难保证。因此测试数据可能会遭受未知的分布偏移,称为分布外偏移,这种偏移导致大多数 GNN 模型无法做出稳定的预测。如 OGB 数据所报告的,到数据采用 OOD 划分时,GNN 将会遭受 5.66% 到 20% 的性能损失。
本质上说,对于一般的机器学习方法,当遭受分布偏移问题时,准确率下降的根本原因是不相关特征和类别标签之间的虚假相关导致的。这个虚假相关根本上是由不相关特征和相关特征的意外的相关性导致的。而对于本文研究的图级别任务,由于图的性质通常由子图单元决定(比如,在分子图中,原子和化学键团表示其功能单元),所以我们定义一个子图单元可以是一个对于标签相关的或者不相关的特征单元。
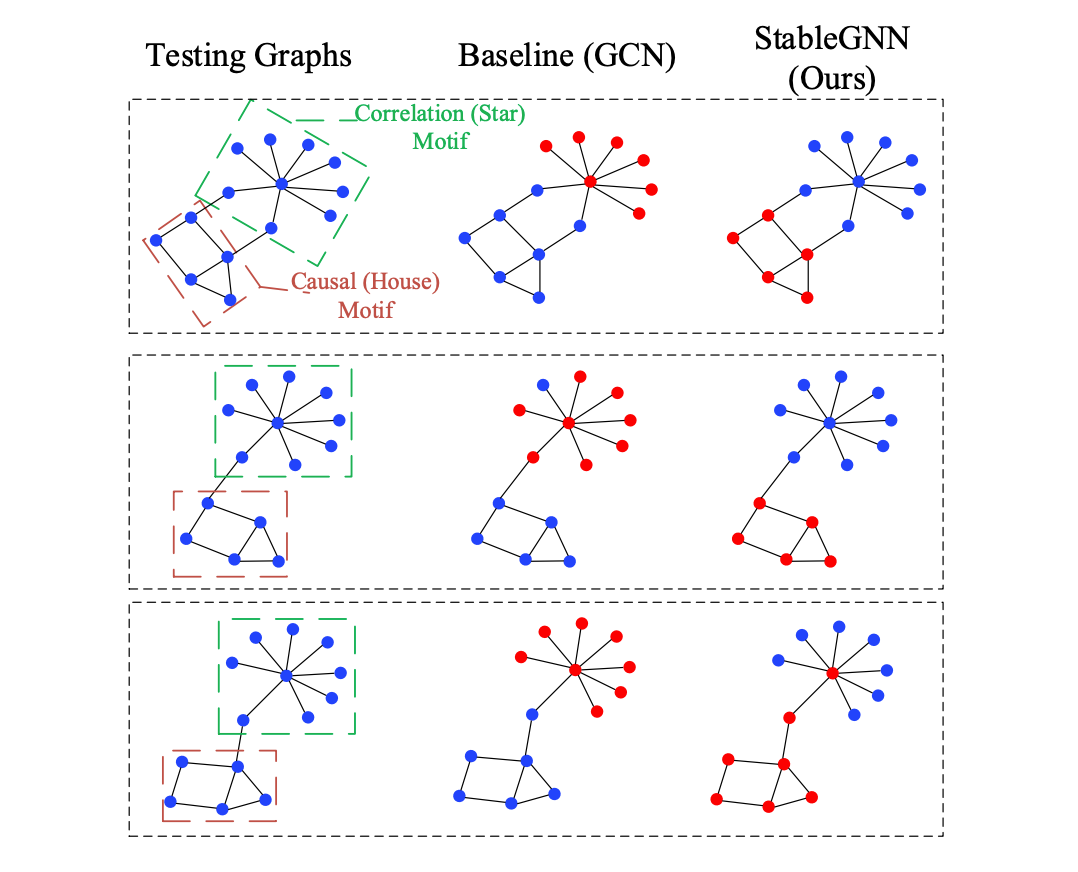
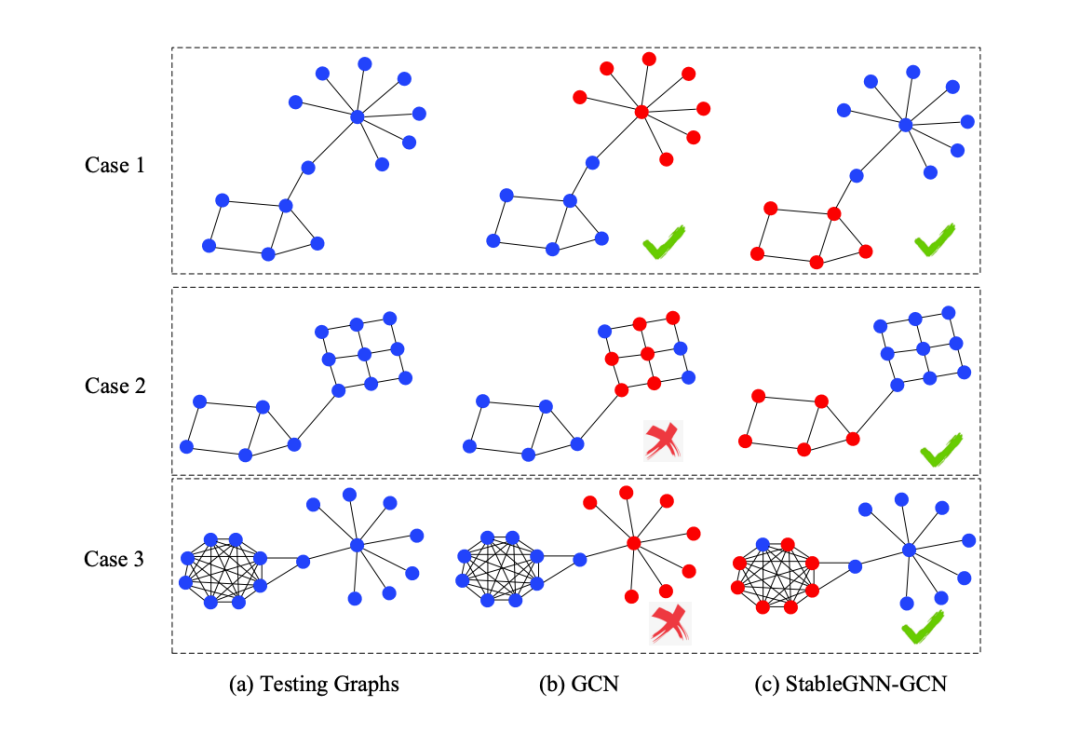
如图 1 所示,以“房子”模体分类任务为例,其中图的标签表示一个图中是否有“房子”模体。GCN 模型是在“房子”模体和“星星”模体高度相关的训练图上训练的。在这个数据上,“房子”模体和“星星”模体将会高度相关。这个意料之外的相关性将会导致“星星”模体的结构特征和“房子”标签的虚假相关。 图 1 的第二列展示了用于 GCN 预测的最重要的子图可视化结果 (由 GNNExplainer 产生)。由结果可知,GNN 倾向于利用星星模体做预测。然而当遭遇没有“星星”模体的图,或者其他模体( 比如,“ 钻石“ 模体) 和星星模体在一起时, GCN 模型被证明容易产生错误的结果。
为了去除虚假相关对于 GNN 模型泛化性的影响,我们提出了一个新颖的用于图的因果表示框架,称之为 StableGNN , 其结合了 GNN 模型灵活的表示学习和因果学习方法对于区分虚假相关能力的两方面优势。对于表示学习部分,我们提出了一个图高层语义学习模块,其利用了一个图池化层来映射相近的节点为簇,其中每一个簇为原始图中一个紧密连接的子图单元。
此外,我们理论证明了不同图的簇的语义含义可以通过一个有序的拼接操作实现匹配。给定了匹配的高层语义变量,我们用因果视角分析 GNN 的性能退化并且提出了一个新颖的因果变量区分正则化项通过学习一套样本权重来去除每一个高维变量对之间的相关性。这两个模块在我们的模型中联合训练。此外,如图 1 所示,StableGNN 可以有效的排除不相关子图的影响(“星星”模体)并且利用真实的相关子图(“房子 ”模体)做预测。
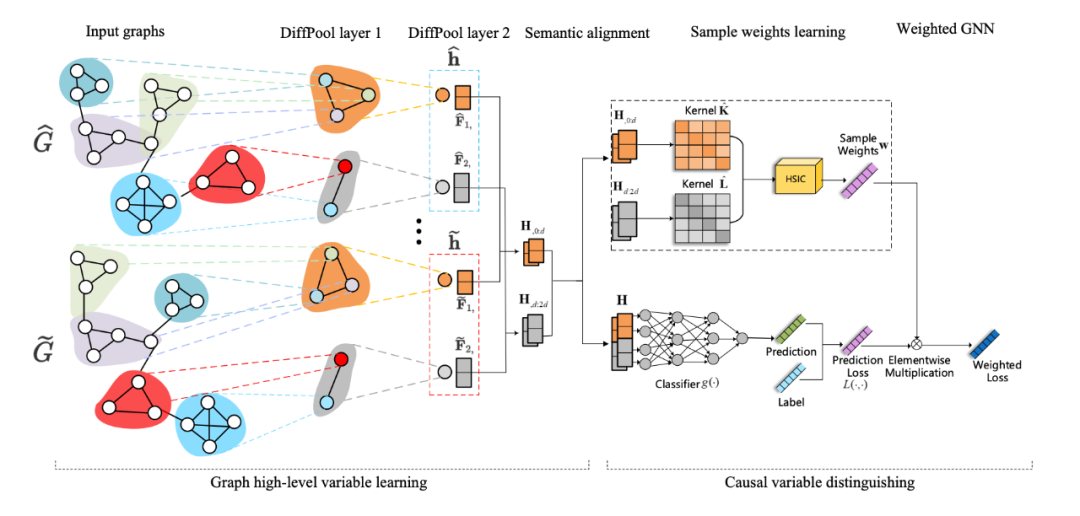
所提出框架的基本想法是设计一个因果表示学习方法来抽取有意义的图高层语义变量然后估计他们对于图级别任务的真实因果效应。如图 2 所示,所提出的模型框架主要分为两个部分:图高层语义表示学习模块和因果变量区分模块。
图2. StableGNN的模型框架
2.1 图高层变量学习
高层变量池化: 为了学习节点表示同时映射紧密连接的子图到几个簇中,我们采用 DIffPool 层学习一个簇分配矩阵来实现这个目标。具体而言,由于 GNN 可以平滑节点表示同时使得表示更加具有区分性,给定输入邻接矩阵
, 同时表示为
,和节点属性
,我们首先使用一个 embedding GNN 模块来得到平滑的节点表示
:
其中
是一个 3 层的 GNN 模块,GNN 层可以是 GCN,GraphSAGE 或者其他的。然后我们构建了一个池化层基于这个平滑的特征表示
。具体地,我们产生一层的节点表示如下:
由于在相同子图的节点可能会有相似的表示和邻居结构,GNN 模型可以把具有相似特征和结构的节点映射到相同的表示上,因此我们把节点表示
和邻接矩阵
输入到一个池化 GNN 模块来产生第一层的的簇分配矩阵:
其中
和
表示第 i 个节点的簇分配向量,
同样是一个 3 层的 GNN 模块,其输出维度为预设的在层 1 的最大的簇个数,是一个参数,可以通过端到端的方法学习到。在得到分配矩阵
之后,我们可以知道每个节点在预设的簇上的分配概率。因此,新的节点的表示可以通过如下方法计算:
这个公式根据簇分配矩阵
聚合了节点表示
,产生了
个簇的表示特征。同样的,我们产生了一个粗化的邻接矩阵如下所示:
我们可以通过堆叠多个 Diffpool 层来实现层次化的聚类结构。
高层表示匹配: 在堆叠 L 层图池化层之后,我们可以得到最高层的高层簇表示
。由于我们的目标是编码子图结构到图表示中并且
已经显示的编码每个紧密连接的子结构信息到
的行向量中,因此,我们提出使用
的表示矩阵来表示高层语义。然而,由于图数据的非欧特性,对于两个图
和
的第 i 个学习到的高层表示的
和
的语义含义可能会不同,比如,
可能代表苯环,
可能代表 NO2 团。为了匹配不同图之间学习到的高层语义表示我们提出通过高层矩阵的行索引来拼接高层变量:
并且我们堆叠在一个 mini-batch 中的 m 个图的高维表示得到 embedding 矩阵
:
我们通过 GNN 层的置换不变性,证明了在经过 DiffPool 层之后,不同图之间对应的高层语义是匹配的:
到目前为止变量学习部分学习的变量可能是虚假相关,在本节中,我们首先分析以因果视角分析导致 GNN 模型性能下降的原因,然后提出一个因果变量区分正则化器(CVD)。
我们的目标是学习到一个分类器
基于相关的特征 Z。为了达到这个目的,我们需要区分学习到的表示
哪个是属于稳定特征 Z 哪个是属于不稳定特征 M。Z和 M 的主要区别是对 Y 有没有因果效应。对于一个图级别的分类任务,在学习到节点表示之后,他将会被送到一个分类器里来预测他的标签。
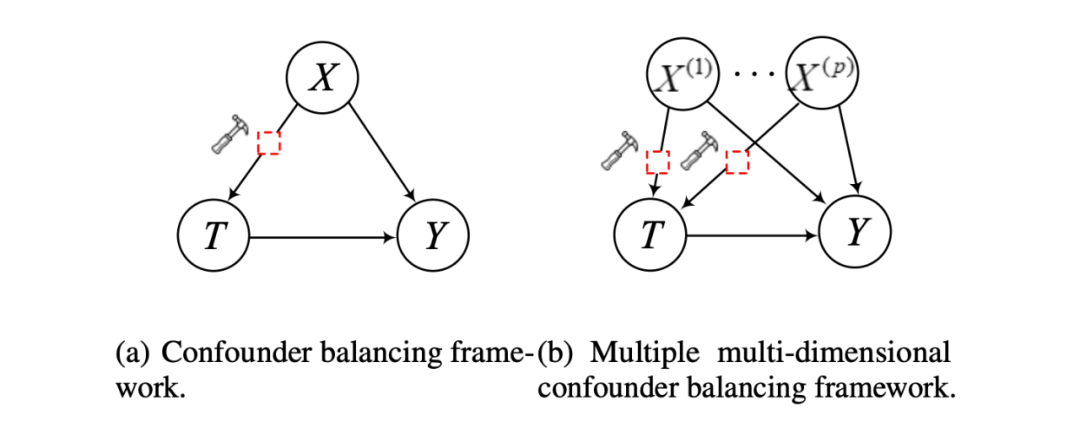
这个预测过程可以表示为图 3(a),其中 T 是处理变量,Y 是输出预测值,X 是混淆变量。路径
表示 GNN 的目标是估计一个学习到的表示变量 T 到 Y 的因果效应。同时其他变量将会被视为混淆变量 X。由于子图之间存在虚假相关,因此他们学习到的表示之间也存在虚假相关。因此,存在一个在 X 和 T 之间的路径。并且由于 GNN 同样也使用 confounder 做预测,所以存在一条路径
。因此,这两条路径形成一个 X 到 T 的后门路径 (i.e.,
),从而导致 T 和 Y 之间的虚假相关。这个虚假相关将会改变处理变量和标签的之间真实相关性,并且在测试的时候会改变。
在这种情景下,目前的 GNN 方法不能准确的评估子图的因果效应,因此 GNN 的性能可能会衰减。混淆平衡技术通常被用来评估变量的因果效应,但是他们通常针对某一变量是由单个维度的特征组成的数据,我们要处理的数据是是多个高维变量组成的,因此,我们提出一种多变量多维度的混淆变量平衡技术,如图 3b 所示:
其中
是第 k 个混淆变量的 embedding 矩阵。
但是上述的混淆变量平衡技术主要针对的是二元处理变量,我们需要处理的高维处理变量。基于混淆平衡技术主要目的是去除处理变量和混淆变量之间的关联,我以我们考虑采用 HSIC 来度量高维变量之间的关联,同时提出采用样本加权的方式去除高维变量之间的关联,方法如下:
对于两个变量 U 和 V,我们首先采用随机初始化的样本权重来重加权它们:
对于去除所有变量之间的相关性,我们优化如下的全局高维变量去相关项:
在传统的 GNN 模型中,对于每一个图数据的权重是相等的。因为学习到的样本权重
可以全局的去除高层变量之间的相关性,我们提出使用这个样本权重来重加权 GNN 的损失,并且迭代的优化样本权重
和加权 GNN 的参数如下所示:
实验
我们分别在仿真数据上和真实数据上验证了我们的实验效果。
3.1 仿真实验
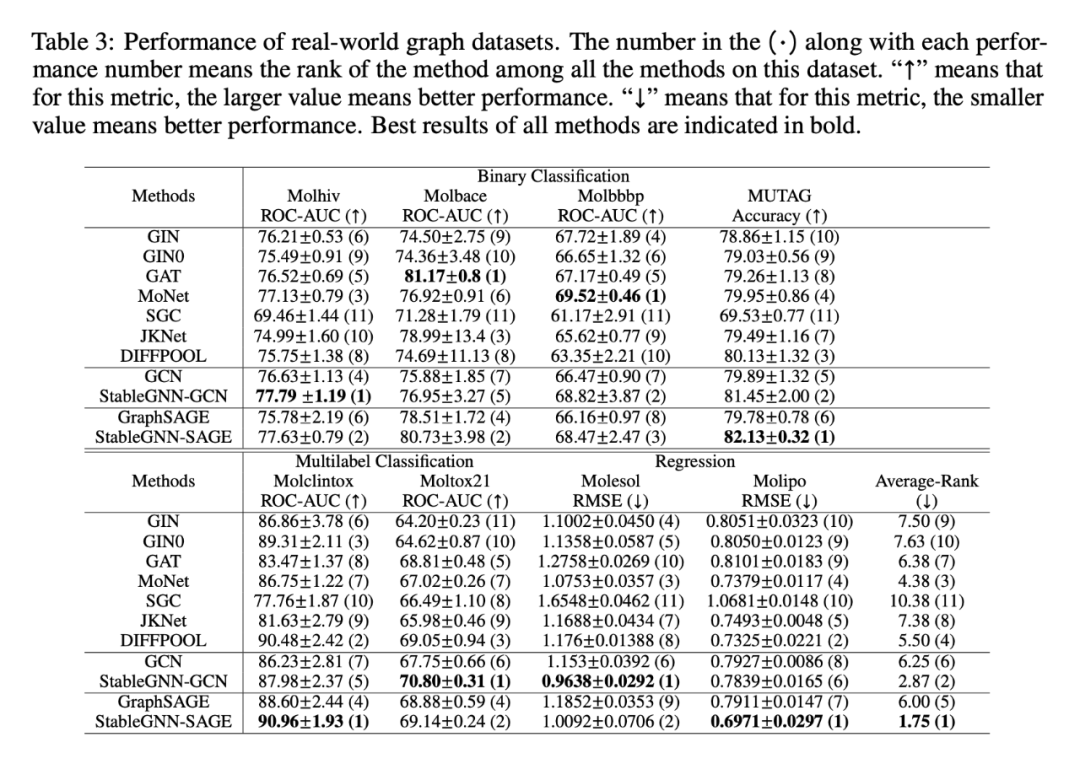
我们通过控制“房子”模体和“星星”模体的相关性程度,生成了 {0.6,0.7,0.8,0.9} 四种偏差程度不同的训练数据,更多生成数据的细节请参考原文。我们分别以 GCN/GraphSAGE 作为基模型实现了我们的模型,所以本节主要和相应的基模型进行了对比。
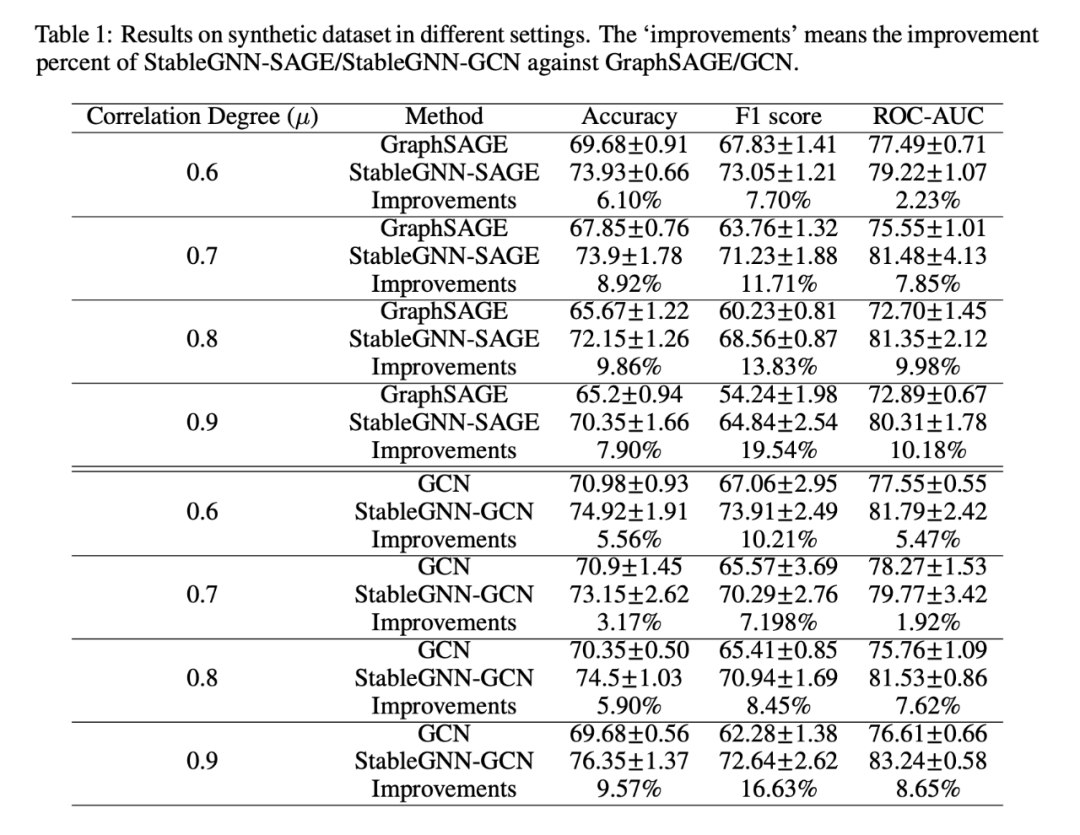
实验结果如表 1 所示。首先,相较于基模型我们都取得了比较大的提升效果,证明了我们是个有效的框架。其次,在偏差程度越大的数据上提升效果越明显,证明了我们的方法可以有效对抗数据偏移产生的分布外效果下降的问题。最后,我们的模型相较于 GCN/GraphSAGE 都有明显的提升,证明了我们的方法是一个灵活的框架可以提升现有模型的效果。图 4 是一些可解释性的例子,也能很好的说明我们的模型可以利用因果结构进行预测。
3.2 真实数据实验
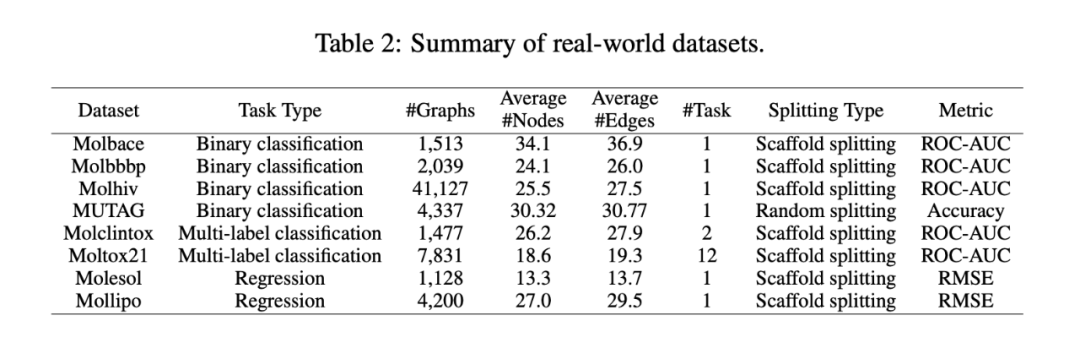
我们在 OGB 的七个分子图性质预测的数据上展开实验,与常用的数据不同的是,这些数据都采用 scaffold splitting 从而使得具有不同结构的图数据划分到训练集和测试集。此外,我们还采用了常用的 MUTAG 数据集用于解释我们的结果。
表 2 是数据集的统计信息。表 3 是实验结果。从表中可以看出,我们的方法综合性能排在前两位,远远大于排名第 3 的方法,证明了现有 GNN 方法在 OOD 场景下的图预测任务上表现的都不好而我们的方法可以取得较好的结果。同时在不同类型数据,不同的任务的数据集上我们都取得了较好的效果,证明了我们的方法是一个通用的框架。
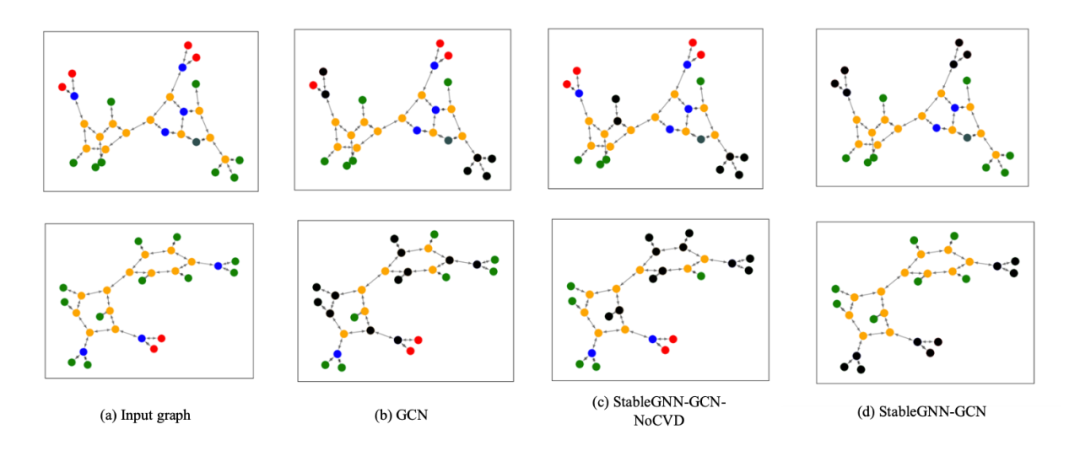
图 4 是 MUTAG 数据集上的可解释性实验。蓝色,绿色,红色和黄色分别代表 N,H,O,C 原子。由 GNNExplainer 产生的最重要的子图被标为黑色。StableGNN 正确的确定了功能团 NO2 和 NH2,这些功能团被认为是对 Mutagenic 有决定性作用的,而其他方法不能找到有解释性的子图做预测。
在本文中,我们首次研究了图数据在 OOD 上的泛化问题。我们以因果视角分析了这个问题,认为子图之间的虚假相关会影响模型的泛化性。为了提高现有模型的稳定性,我们提出一个一般化的因果表示学习框架,称之为 StableGNN,其有效的结合图高层表示学习和因果效果评估到一个统一的框架里。丰富的实验很好的验证了 StableGNN 的有效性,灵活性,和可解释性。
此外,我们认为本文开启了一个在图数据上进行因果表示学习的方向。本文的最重要的贡献是提出了一个通用的因果表示框架:图高层变量表示学习和因果变量区分,这两个部分都可以为任务而特殊的设计。比如,多通道的滤波器可以被用来学习图上的不同的信号到子空间里。然后对于一些数据也许在高层变量之间存在这更复杂的因果结构,因此发现这些因果结构对于重构原始数据生成过程将会更有效。
[
1] R. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec, “Gnnex-plainer: Generating explanations for graph neural networks,” in NeurIPS, 2019.
[2] X. Zhang, P. Cui, R. Xu, L. Zhou, Y. He, and Z. Shen, “Deep stablelearning for out-of-distribution generalization,” in CVPR, 2021, pp.5372–5382
[3] R. Ying, J. You, C. Morris, X. Ren, W. L. Hamilton, and J. Leskovec,“Hierarchical graph representation learning with differentiablepooling,” in NeurIPS, 2018.
[4] B. Schölkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner,A. Goyal, and Y. Bengio, “Toward causal representation learning,”Proceedings of the IEEE, vol. 109, no. 5, pp. 612–634, 2021.