如何应对变化的图数据分布? Non-IID Graph Neural Networks
前言
本文的出发点是 graph-level 的图分类任务,在图分类中,每个图都被视为一个数据样本,目标是在一组训练图上训练一个分类模型,通过利用其相关节点特征和图结构来预测未标记图的标签。当建立一个用于图分类的 GNN model 时,训练集中的图数据假定满足同分布。然而在现实世界中,同一数据集中的图可能具有差异性很大的不同结构,即图数据彼此之间可能是非非独立同分布的(Non-IID)。基于此本文提出了一种适用于 Non-IID 图数据的 GNN model。具体来说,首先给定一个图,Non-IID GNN 可以适应任何现有的图神经网络模型,为该图数据生成一个特定样本的模型。
如果大家对大图数据上高效可扩展的 GNN 和基于图的隐私计算感兴趣,欢迎关注我的 Github,之后会不断更新相关的论文和代码的学习笔记。
1.Motivation
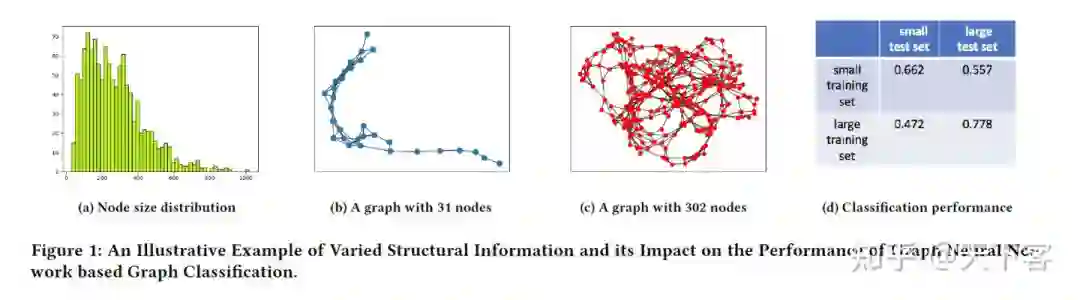
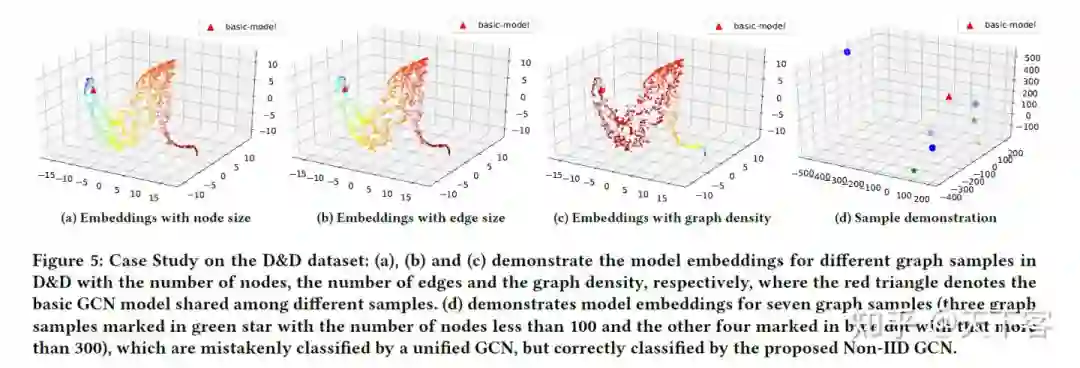
因此作者想到数据集中多样的图结构信息是否会影响基于 GNN model 的训练,作者根据节点数量将 D&D 中的图分为两组:一组由节点数量较少的图组成,另一组由节点数量较多的图组成。然后将每个集合分成一个训练集和一个测试集。分别基于两个训练集训练两个传统的 GCN model,实验结果如图 1(d)。作者基于两个 GCN model 在两个数据集上分别的表现来说明图的结构信息会影响 GNN model 的性能(这里逻辑存疑,按图 1(d)已经分成两个数据集了,理所应当对角线上表现最好,因为训练样本不同,作者原文如下)
The GNN model trained on graphs with a small number of nodes achieves much better performance on the test graphs with a small number of nodes than these with a large number of nodes.
个人认为根据这个实验结果说明的问题是图的结构会影响基于 Message-passing 的 GNN model 的性能,因为 large dataset 的表现更优,即丰富的图结构是 Message-passing GNN 表现良好的关键,因此图数据集中不同图结构的分布可能会对最终 train 的 GNN model 产生一定影响。(因此应该加入利用全部图数据训练得到的模型来进行 test dataset 的效果对比来说明 Non-IID 分布的图结构信息确实会对模型产生影响。)
作者基于此实验现象认为一个良好的 graph-level 的 GNN model 需要学习到数据集中不同分布的图结构。(此处个人认为核心在于如何处理数据集中结构信息较少的 graph data 以减少其对模型的影响)。
2. Non-IID-GNN
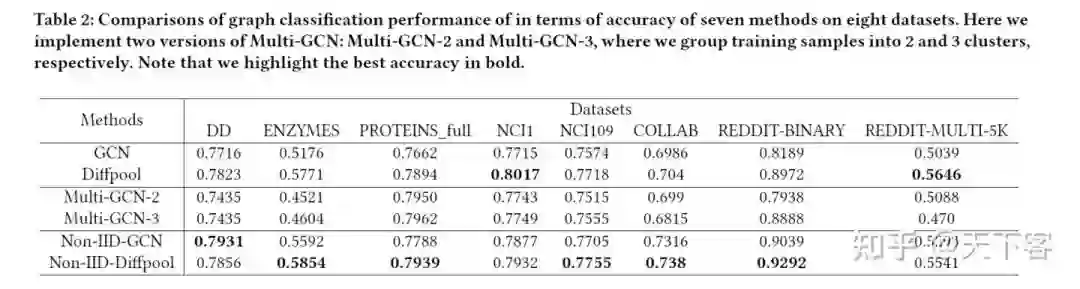
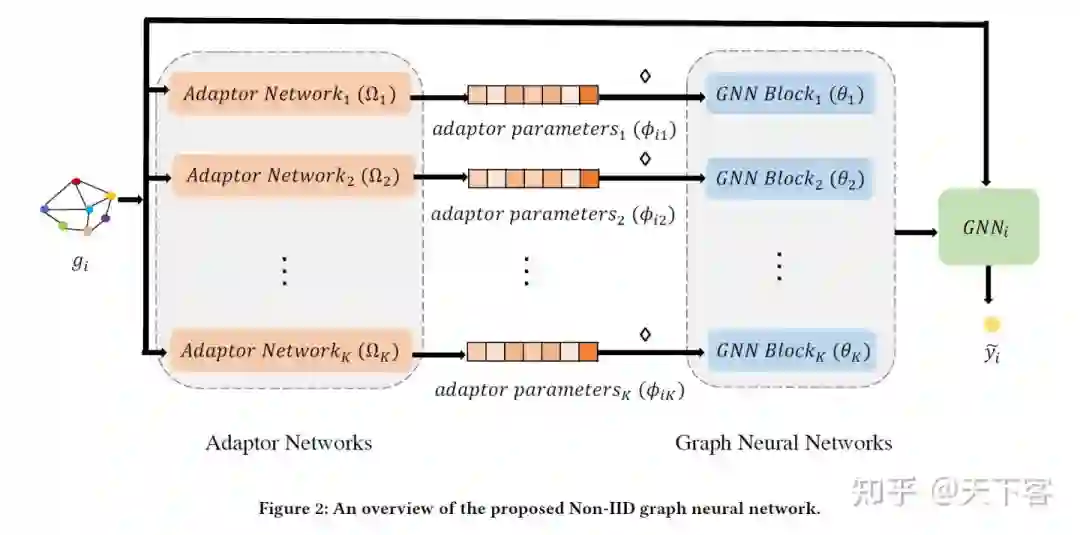
Non-IID-GNN 的基本思想是过在图的结构信息上应用 adaptor network来逼近图 的分布信 息,这些信息作为适配参数,为 适配每个 GNN block ,适配后的 GNN 模型 可以 看作是 的一个 specific graph classification model (直觉上可以理解为每个 Adaptor Network 学习一个图数据中可能存在一类图结构即图数据的一类结构分布)。理想情况下,给定 一个末标记的图 ,经过训练的 Non-IID-GNN 将生成一个自适应的GNN 模型 (Adaptor Networks 中 adaptor parameters 共享的 GNN Blocks 组成)来预测其标签。
2.1 The Adaptor Network
作者希望通过 Adaptor Network 从观察到的结构信息中估计出其分布。图神经网络通常由几个后续的 filtering 和 pooling layers 组成视为 GNN Blocks。图数据分布的不同可能对每个 GNN Block 产生不同的影响。因此建立一个 Adaptor Network,为 GNN Blocks 生成 adaptor parameters。
首先提取 代表给定 graph sample 的结构信息,之后 Adaptor Networks 将 作为输 入并生成 adaptor parameters。假设共有 个 GNN Blocks 基于 adaptor parameters 进行 学习,形式如下:
其中 代表第 个 adaptor network 的参数, 代表相应 adaptor network 的输出同时 被用于第 个GNN Block 的学习。理论上 adaptor network 的函数有多种选择,本文选择在拟 合任何函数方面能力较强的前馈神经网络, Adaptor Networks 的整体表示如下:
2.2 The Adapted Graph Neural Network
2.2.1 An General Adapted Framework
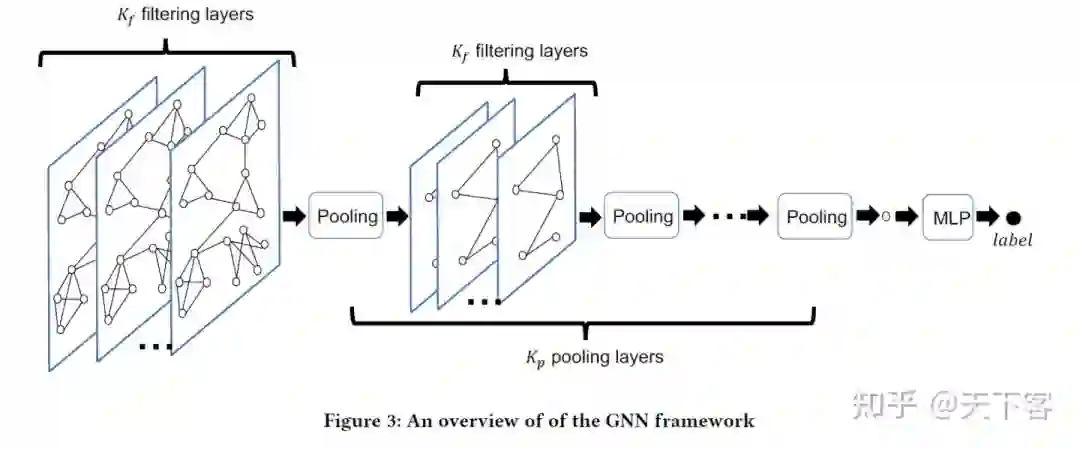
graph-level 的 GNN model 通常包含两类层: the filtering layer 和 the pooling layer. 其中 the filtering layer 将图的结构和节点表示作为输入,输出节点 embedding。the pooling layer 将图的结构和节点表示作为输入,产生具有新的图结构和新的节点表示的 coarsened graph。假 设包含 个 pooling layer 和 个堆叠的 filtering layer,那么总共可学习的 GNN Blocks 的个数为 。
filtering layer
分别代表 GNN Block 和 adaptor parameters 的参 数,关系如下:
其中 代表适应的模型参数和原始模型参数 维度相同, 代表 adaptation operator, 其中算子的设计与具体类型的 GNN model 相关。模型参数自适应后的计算形式为:
代表池化层参数满足且池化 层更新为:
2.2.2 Adapted GCN: Non-IID-GCN
以 GCN 为例:
算子设计如下: ,将其分割成两个部分 :
其中 代表广播机制,将向量 重复 次 即与 维度相同, 代表 element-wise multiplication。节点侧的池化层选择 max pooling layer:
其中 代表 graph-level 表示, 代表 the maximum over all the nodes,且 。
2.2.3 Adapted diffpool: Non-IID-Diffpool
Diffpool 是一种用于图分类的分层图级表示学习方法。Diffpool 中的 filtering layer 参考式(9)(10)其 pooling layer 定义如下:
为在 pooling layer 中定义的嵌入层, 代表软分配矩阵。
2.3 Training and Test
预测结果:
loss:
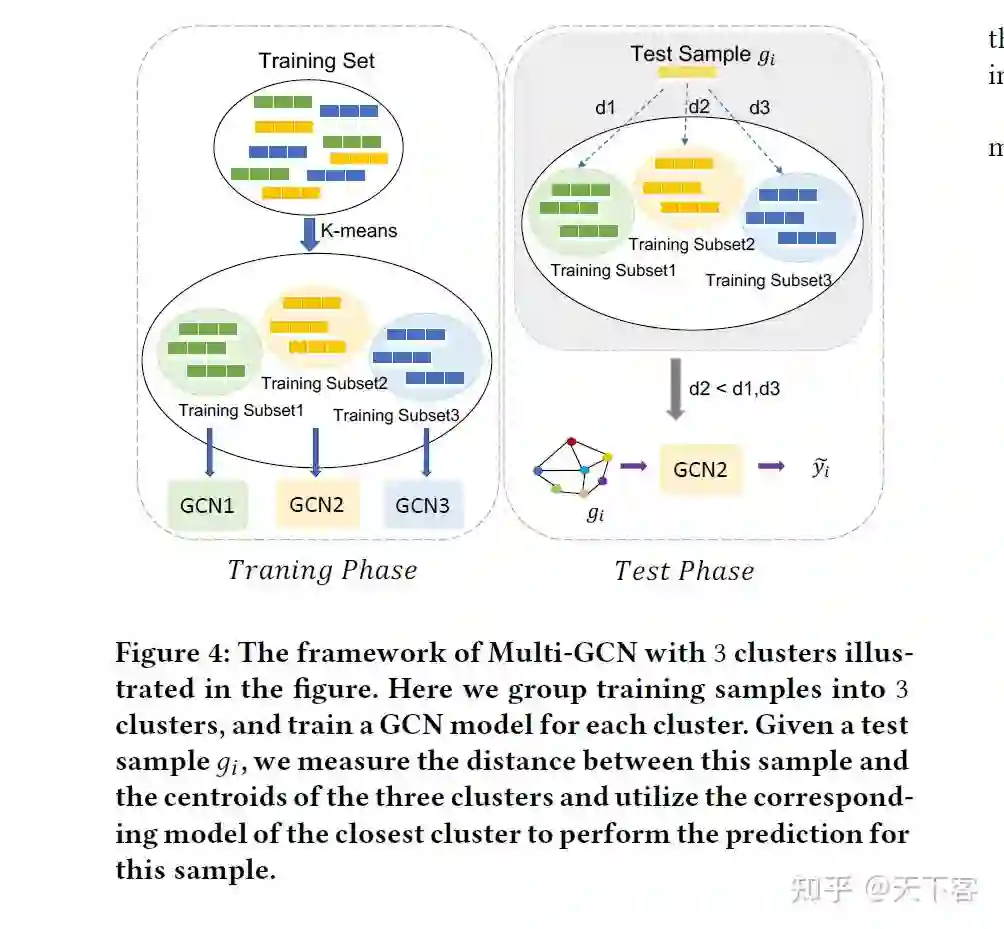
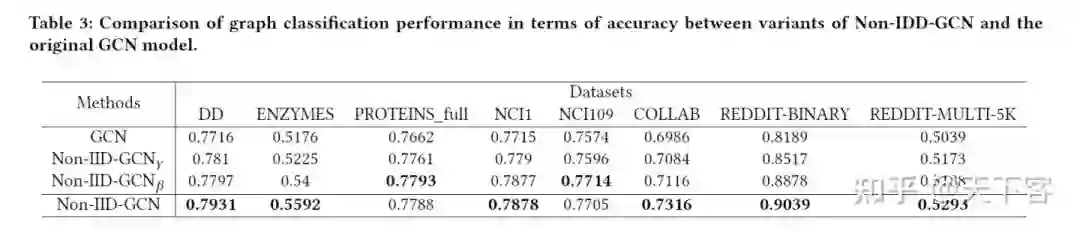
3. Experiments