
原创作者:陈一帆 转载须标注出处:哈工大SCIR
1. ChatGPT与PPO算法
在上篇文章中我们提到,ChatGPT的训练过程主要分为三步:微调GPT-3模型、人工对微调后模型的生成结果打分以训练得到一个奖励模型、 基于微调后的GPT-3结合奖励模型采用强化学习的方法更新策略。而第三步中强化学习的方法为OpenAI于2017年提出的Proximal Policy Optimization(PPO)算法。PPO算法提出后应用场景相当广泛,包含图像识别[1]、机械臂控制[2]、电子游戏[3]以及今天的ChatGPT。OpenAI基于PPO算法设计的AI程序OpenAI Five甚至在2019年4月13日击败了Dota 2世界冠军战队OG[4]。 在接下来的部分中,我们会在第二章中介绍强化学习的基础知识,第三章中介绍PPO算法论文并对其中的公式进行推导。
2. 强化学习基础
以下内容参考OpenAI Spinning Up[5],其为OpenAI公开的一份关于深度强化学习的教育资源。
2.1 基本定义
强化学习(Reinforcement Learning)是一个马尔科夫决策过程,可定义为五元组,其中为状态空间,为动作空间,是状态转移函数,是奖励函数,是初始状态分布。状态转移函数是一个到的映射,有,即状态采取动作后状态转移到的概率,又可以写为或者等;奖励函数是一个到实数域的映射,可以写作,但多数情况下会根据问题的实际定义简化为, 表示状态下执行动作的奖励,也可以记为或其他。强化学习过程中,智能体首先处于开始状态,然后选择动作执行,与环境产生交互,获得奖励并转移到状态,我们称智能体经历的状态、动作序列为轨迹,强化学习的目标是最大化累积奖励:要实现最大化累积奖励,其重点在于智能体处在某个状态时应该选择哪个动作执行,或者其选择动作应该服从一个怎样的分布,记作,一般称之为策略(Policy),策略即是强化学习中优化的变量。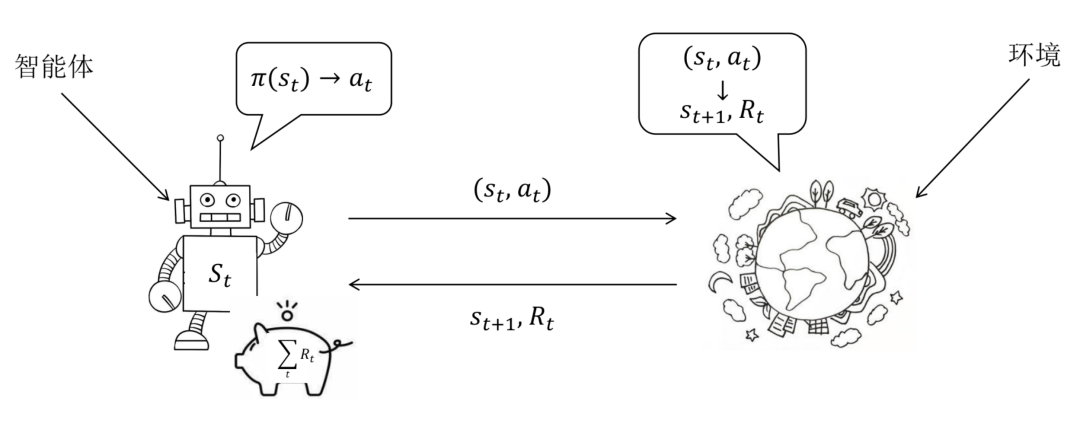
- 智能体处在某个状态执行何种动作由模型决定,执行该动作后转移到哪一个状态,以何种方式转移取决于环境。有时这是固定的,有时则会服从一定的分布;
- 马尔科夫过程意味着:智能体处在任意一个状态,其后续的策略都与之前的动作无关;
- 式(1)中的代表着轨迹的结束,可能是到达了特定的状态,或是达到一定条件;
- 式(1)是有穷的、无折扣的累积奖励,另外一种是无穷的、有折扣的累积奖励,定义一个折扣因子,无穷有折扣的累积奖励公式为:对于无穷的情况设计一个折扣因子,直观上是因为当前已获取的奖励要比未获取的奖励更好,数学上的好处是这样求和不会产生无穷大的值。具体何种形式的累积奖励取决于实际问题。 为了后续推导的方便,我们引入两个重要的量。为了评估某个状态的整体上的好坏,引入了状态值函数(State value function),用函数来表示,其定义为状态未来累积奖励的期望,期望越大说明当前状态越有利。引入状态动作值函数(State-action value function),用函数表示,其定义为状态下采取动作后未来累积奖励的期望。与之间存在如下的等式关系: 关于Q、V值的定义和转换关系可以参考图2
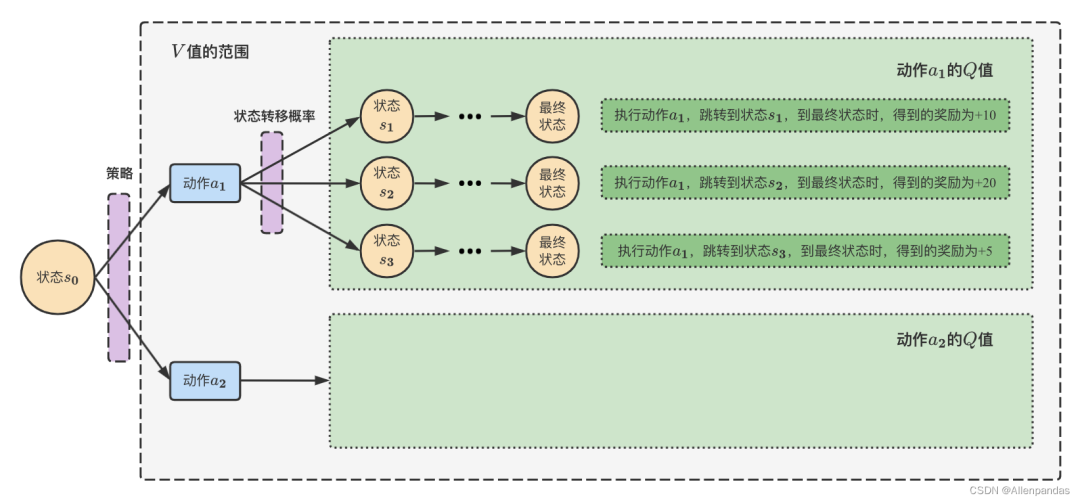
图2 Q、V 值的定义和转换关系[6]显然,强化学习模型优化目标可以使用表示,其中表示智能体的开始状态。
2.2 Model-Free vs Model-Based, Value-Based vs Policy-Based, off-policy vs on-policy
强化学习算法种类繁多,可按图3所示类别粗略分类。 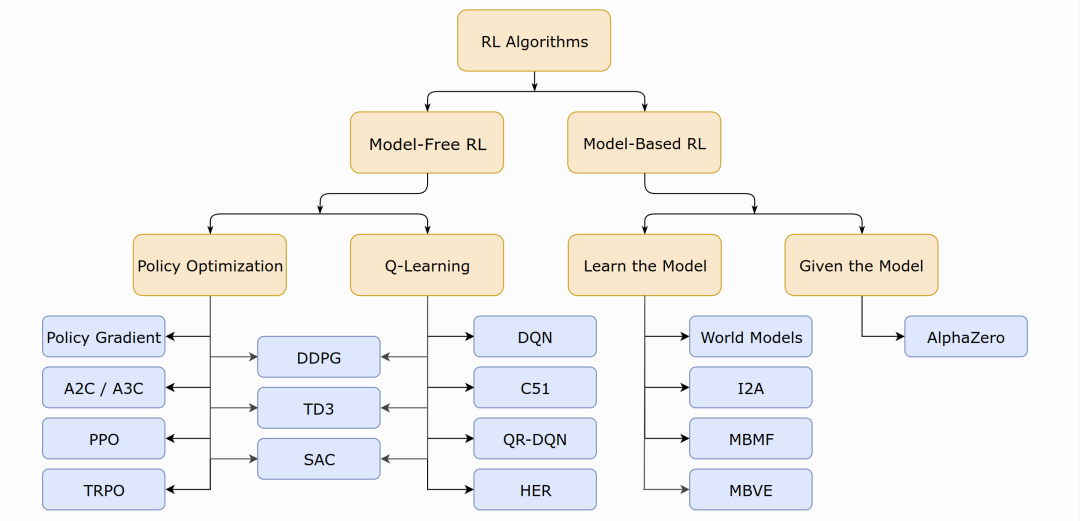
- 基于模型的强化学习(Model-based RL)、无模型的强化学习(Model-free RL);
- 基于策略的强化学习(Policy-based RL)、基于值的强化学习(Value-based RL,即图中Q-leranng);
- on-policy、off-policy。
根据问题求解思路、方法的不同,我们可以将强化学习分为基于模型的强化学习(Model-based RL)、无模型的强化学习(Model-free RL),在这里“模型”的含义是对环境进行建模,具体而言,是否已知其知和,即和的取值。 如果有对环境的建模,那么智能体便可以在执行动作前得知状态转移的情况即和奖励,也就不需要实际执行动作收集这些数据。否则便需要进行采样,通过与环境的交互得到下一步的状态和奖励,然后仅依靠采样得到的数据更新策略。 我们以围棋为例举例说明,自然而然地,我们会以棋盘上棋子的分布作为状态,以一次落子作为动作,一般以当前棋局的胜率作为奖励。不妨假设强化学习程序是黑方棋手,如果以黑方棋手落子前棋子分布作为状态,那么每次状态的改变便是两颗棋子,由于无法预测白方棋手的落子,我们无法对状态转移进行建模,此场景便是无模型的强化学习。但是,我们使用搜索引擎会发现,AlphaGO、AlphaGo Zero、AlphaZero 均是基于模型的强化学习模型,其差别便在于,他们会在训练的过程中同时扮演黑方棋手和白方棋手,这也便是“自己与自己下棋”的由来,那么状态的定义便是任意一方落子前棋子的分布,如此状态转移情况显而易见:给定当前棋子的分布(当前状态)以及本次落子的位置(动作),求落子后棋子的分布(下一步状态)。而奖励值(落子后棋局的胜率)获取的一般思路是棋局模拟,即不执行实际的落子动作,而是使用其他模型模拟棋局的进行得到获胜概率。具体方法是蒙特卡罗树搜索:例如将棋局继续进行 1600 次,得到执行各候选动作的获胜次数,除以 1600 作为获胜概率,如此也可以找到当前最优动作,模拟棋局的进行不依赖实际落子,AlphaGo Zero 依赖一个更加小型的模型快速走子,AlphaZero 直接依赖待学习的策略帮助自己走子。这类似于人类棋手的心算,在强化学习场景下我们说这是对环境进行建模,如此我们便可以称其为基于环境的强化学习。 上述是较为复杂的基于模型的强化学习算法,不考虑对环境的建模,基于模型的强化学习可以简单的使用动态规划求解,任务可定义为预测(prediction)和控制(control)。预测的输入是和策略,目的是评估当前策略的好坏,即求解状态价值函数。控制的输入是,目的是寻找最优策略和。对预测任务的求解可简单利用上述与关系的公式,易得的迭代公式:式中的均为已知,只需迭代求解即可,上述方程也称为贝尔曼期望方程(Bellman Expectation Equations)。这里也可以列线性方程组求解,有个状态节点,即有个方程。而对于控制任务,策略是未知、待优化的。在最优策略的求解问题上,有两种方法:值迭代、策略迭代。策略迭代会从一个初始化的策略出发,先进行策略评估,即固定然后使用预测的方法求解最优值函数, 然后进行策略改进,可以简单的利用来贪婪的改进策略, 不停的进行策略评估和策略改进两个步骤,直至收敛。而值迭代方法则利用公式:相比与策略迭代的方法,其并没有进行完成完整的预测操作, 预测操作无论是求解线性方程组或是迭代至收敛,均需要消耗较长时间, 值迭代的方法简化了这一操作,仅根据下一个状态的值,得到当前状态下一个轮次的值。 相比于基于模型的强化学习,无模型的强化学习方法更具有研究价值,也更复杂。我们首先介绍强化学习领域中存在已久的两大类方法:基于值的强化学习(Value-based RL)和基于策略的强化学习(Policy-based RL)。基于值的强化学习方法会学习并贪婪的选择值最大的动作,即。该方法往往得到确定性策略(Deterministic Policy)。而基于策略的强化学习方法则对策略进行进行建模,直接对进行优化。该类方法一般得到随机性策略(Stochastic Policy)。 确定性策略是在任意状态下均选择最优动作,它是将状态空间映射到动作空间的函数。它本身没有随机性质,因此通常会结合-greedy或向动作值中加入高斯噪声的方法来增加策略的随机性。一般基于值的强化学习方法学习到的是确定性策略。随机性策略是在状态下按照一定概率分布选择动作。它本身带有随机性,获取动作时只需对概率分布进行采样即可。一般基于策略的强化学习方法学习到随机性策略。 需要注意的是,上文中提到的策略迭代、值迭代算法与此处基于值的强化学习方法、基于策略的强化学习方法并无对应关系,他们均是基于值函数来完成策略的更新,可以划入基于值的强化学习方法中。 我们最后简要介绍两种基于值的强化学习算法Q-Learning和SARSA(State-Action-Reward-Sate-Action) 并以此为例说明on-policy和off-policy的强化学习。首先介绍他们选择动作的策略-greedy:Q-learning算法与SARSA算法均为无模型的基于值的强化学习算法,由于不知道、,他们均需要通过与环境交互得到奖励值和状态转移的结果,智能体从开始状态到结束状态的一条轨迹,我们称之为episode,episode中一次状态转移我们称为step,每一个step我们都更新一个值:
我们称式(4)为行为策略(Behavior Policy),智能体遵循该策略选择动作与环境进行交互获取数据(奖励值、转移到的状态),与之相对的为目标策略(Target Policy),目标策略依赖行为策略获取的数据进行更新,更新也会同步到行为策略,目标策略是我们优化的对象,也是强化学习模型推断时使用的策略。式 (5) 即为目标策略的更新公式,其中来自于行为策咯,、来自于环境,而则取决于目标策略,SARSA 算法的目标策略同样为-greedy,目标策略与行为策略保持一致,我们称 SARSA 是 on-policy算法。Q-learning 算法的目标策略是,目标策略与行为策略并不一致,我们说 Q-learing 是 off-policy 算法。 两者的伪代码如图4、图5所示。可以看到图4中 来自于,而图5中A′ 来自于上一句代码中-greedy 策略。

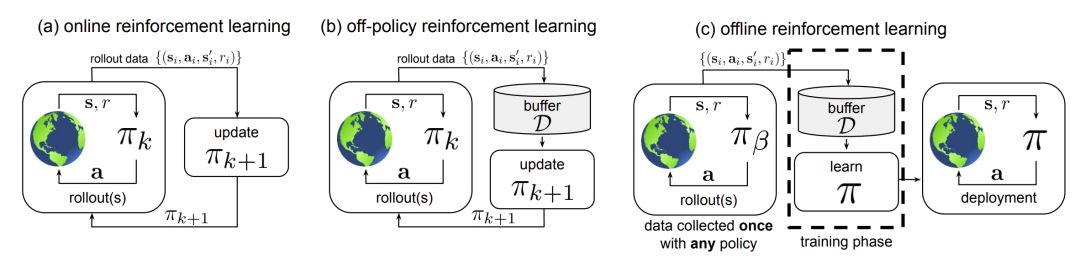
图6 on-policy vs off-policy vs offline RL[8] 行为策略与目标策略的不一致有多种情况,Q-learning 中选择 ϵ-greedy 作为行为策略目的是在数据获取过程中有一定的探索性,而在图6(b)中行为策略与目标策略的不一致在于行为策略会累积一定数据后更新目标策略,或者说目标策略的更新不会马上同步到行为策略中,此时行为策略是旧的目标策略。图(a)则是 on-policy 算法,图(c)是 offline 算法,可以看到仅有简单的数据收集-> 策略学习-> 模型部署过程。
2.3 强化学习基础小结
在上文中,我们首先介绍了强化学习的定义与优化目标,并介绍了重要的两个值函数:状态值函数,状态动作值函数,无论是基于值或是基于策略的强化学习方法中他们均有着重要的作用。在第二节中我们首先简要介绍了基于模型的强化学习,分为预测和控制两种形式,学习控制其本质是为了寻找最优策略,而学习预测是为了对策略找到一种评价标准。在无模型的强化学习方法中,我们首先介绍了基于值的强化学习法方法,并以Q-learning和SARSA为例介绍了on-policy和off-policy。基于策略的强化学习方法的介绍,我们将通过阅读PPO论文进行。
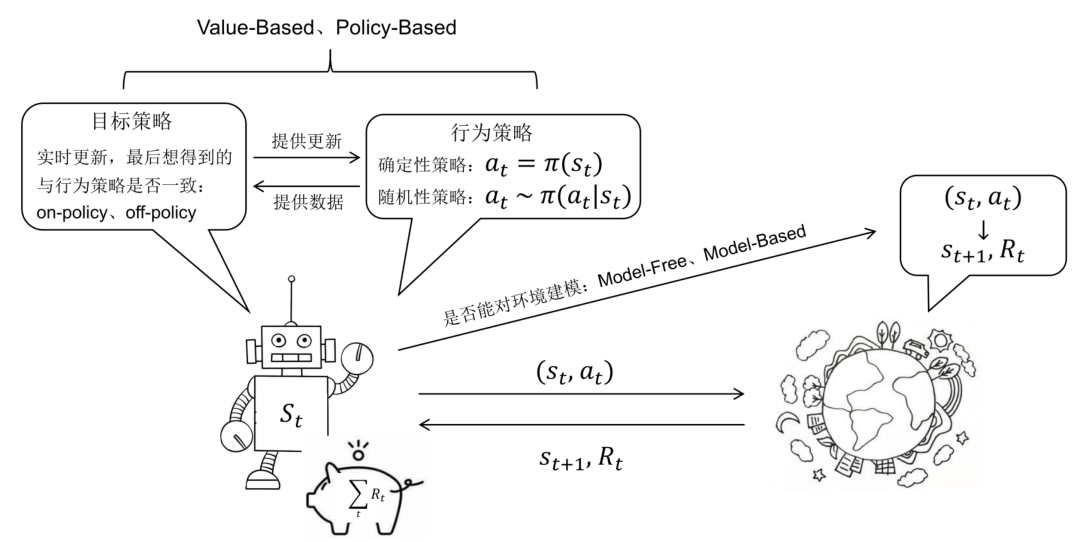
图7 强化学习示意图 3. PPO论文讲解 PPO算法的提出来自于论文《Proximal Policy Optimization Algorithms》,该论文内容只有8页,首先回顾了策略梯度算法的发展,提出了两种形式的PPO算法,并比较了其他强化学习算法的效果。在本章我们首先跟随作者的思路,从最简单的策略梯度算法开始,然后拓展到 Trust Region Policy Optimization(TRPO)算法,进一步得到PPO算法的两种形式:、,最后进行实验验证效果。不同于论文中仅给出公式的做法,我们补全了一些公式的推导过程,并对PPO算法的特点进行了一点讨论。 3.1 策略梯度定理策略梯度定理是策略梯度算法中最简单的形式,论文中给出了策略梯度算法中梯度估计的一般形式:梯度策略算法中,策略被建模为一个神经网络模型,神经网络的参数决定了策略,进而决定了状态动作值函数、状态值函数。上式中为机会方程(Advantage Function),有。引入该变量的意义在于: “Sometimes in RL, we don’t need to describe how good an action is in an abolutesense, but only how much better it is than others on average. That is to say, we want to know the relative advantage of that action. We make this concept precise with the advantage function. ”为了使神经网络根据这一形式进行梯度下降操作,作者构造了如下形式的目标函数,其对求导即可得到上述形式的梯度。 该方法下,模型容易在一次轨迹中进行多步优化,这并不准确,因为一次优化后其轨迹信息理应再次采样,后续的实验中也会证明这一方法容易导致较大的策略迭代,并造成严重影响。 下面我们从基本定义开始推导。最简单的策略梯度定理
策略梯度定理以轨迹的期望收益作为优化目标,即,为了推导方便,此处将会是有穷的、无折扣的累积奖励,但无穷的、有折扣情况下的推导也几乎完全相同。我们首先得到轨迹在下出现的概率因此轨迹出现概率的对数形式为:注意,由于环境对于没有任何依赖,因此,,的梯度均为0。其对梯度求导有:接下来会使用一个对数求导的恒等变换:得到以上中间结论后,可以开始以下推导: 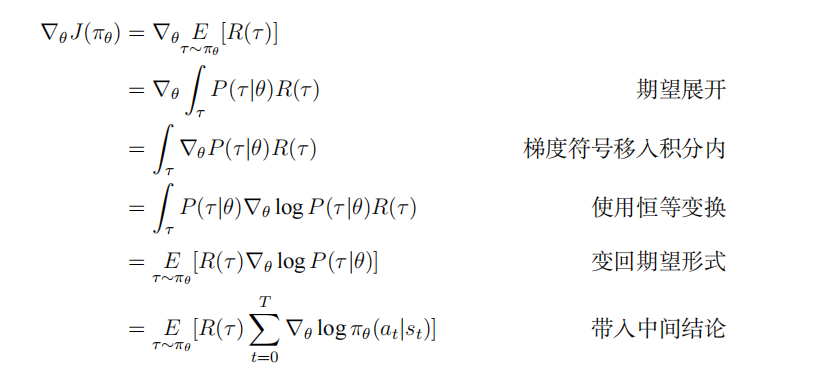
EGLP 引理(Expected Grad-Log-Prob Lemma) ****这已经很接近论文中的形式了,我们继续补充一些技巧进行后面的推导。不妨设随机变量符合概率分布,则 显然因此 即在此基础上,只需要函数只依赖于状态,都有: 因此式(7)可以替换为: 这里使用到的函数一般被称为基线。最常见的是,这样做在理论上意味着:我们并不关注当前状态下执行这个动作的值到底有多高,而是关心该动作相比于所有动作的平均水平相比是好还是坏。在实际实验过程中,这也会让策略学习更快更稳定。因为, ,,若取,则此处是下多次采样得到的轨迹的期望收益,而论文中给出的是单条轨迹下的期望收益值,成功得到论文中形式,也成功介绍了策略梯度算法的大致情况。
3.2 信赖域策略优化算法(Trust Region Policy Opitimization)
由于上述方法中模型迭代步长过大,并且其未在策略变化后重新进行采样,因此作者将上述目标函数修正如下:上式中代表更新之前的参数。对目标函数进行线性近似,对约束进行二次近似后,该问题的求解可以用共轭梯度法有效求解。 这一公式的来历我们参考了论文[10]。策略梯度算法对策略的更新均使用公式:。在这里更新步长非常重要,当步长不合适时,更新的参数所对应的策略是一个更不好的策略,当利用这个更不好的策略进行采样学习时,再次更新的参数会更差,因此很容易导致越学越差,最后崩溃。 在这一节中,我们使用表示策略对应的累积奖励函数,如果可以将新的策略所对应的奖励函数分解成旧的策略所对应的奖励函数加其他项。只要新策略所对应的其他项大于等于零,那么就能保证奖励函数单调不减。 现证明 其中,和分别表示新策略和旧策略。证明过程如下: 
以此去掉时间序列求和操作。得到:这一公式可以直观解为:对原策略下任意状态,其所有动作的机会函数值以被选中概率作权重的加权和均是0(机会函数的定义),新策略就是在保持机会函数值不变的情况下,每个状态都有了新的动作的概率分布使得机会函数的加权和都大于等于0,那么新状态就一定优于旧状态。即保证的时候,就可以保证新策略是比旧策略好的。 但由于近似误差和估计误差的存在,可能会存在一些状态不满足,即。
旧策略的状态分布代替新策略的状态分布在上述公式中含有新策略,同样也含有新策略,这个复杂的依赖关系 让式(10)难以优化,即根据机会函数值调整得到时,势必还要考虑到前面的。以此我们引入TRPO的第一个技巧对状态分布进行处理。我们忽略状态分布的变化,依然采用旧的策略所对应的状态分布。这个技巧是对原代价函数的第一次近似。其实,当新旧参数很接近时,我们将用旧的状态分布代替新的状态分布也是合理的。式(10)变成了:此处作者使用了一个新的符号来表示相对于旧策略新策略产生的奖励。接下来作者参考论文[11]中的结论:当策略网络可微的时候,将和看成关于变量的函数,那么对于有: 该结论可直观的由图8所示。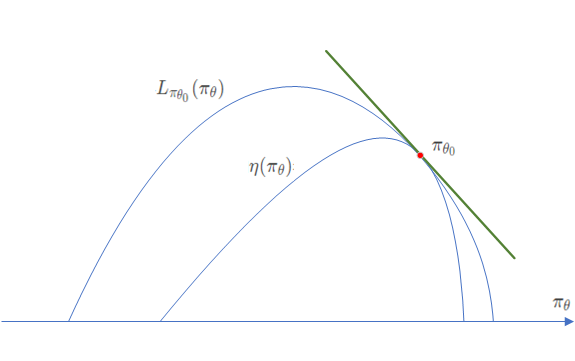
重要性采样
观察这样一个变换:整理得到:上述式子的场景是:服从分布,我们想计算的期望值,但是假设我们不能在分布中采样数据,只能从另外一个分布中去采样数据,可以是任何分布,那么经由上述式子,我们就可以从中采样,再去计算,最后取期望值,就是我们所求的答案。 对于我们首先将 变换成然后将目标函数中的替换为期望, 得到:引入重要性采样操作,将替换为,得到:目标函数成功变换为所求形式,完整的公式为:
3.3 CLIP
对于上述式子,如果令,那么即可得到: 上式为CPI(Conservative Policy Iteration)算法的目标函数,正如其名,CPI算法使用了一种非常保守且复杂的方式对目标函数进行优化[12]。相比之下TPRO算法并未改变目标函数的形式,而是引入约束项,使用拉格朗日对偶法处理之后采用共轭梯度法进行优化,而PPO算法的改进之处同样是解决这一目标函数难以优化的问题:如何控制更新步伐,避免策略更新步伐过大导致效果下降、更新步伐太小导致训练速度缓慢的问题,即使TRPO算法,也仍然遗留了实现困难,求解过程计算量大的缺点。
我们首先来看PPO算法对此问题的第一种优化方式,将上述目标函数修改为如下形式:其中表示将限制范围,那么上式就将限制在之间,一般取,上式也就是PPO的目标函数,论文中对于其进行了绘图表示。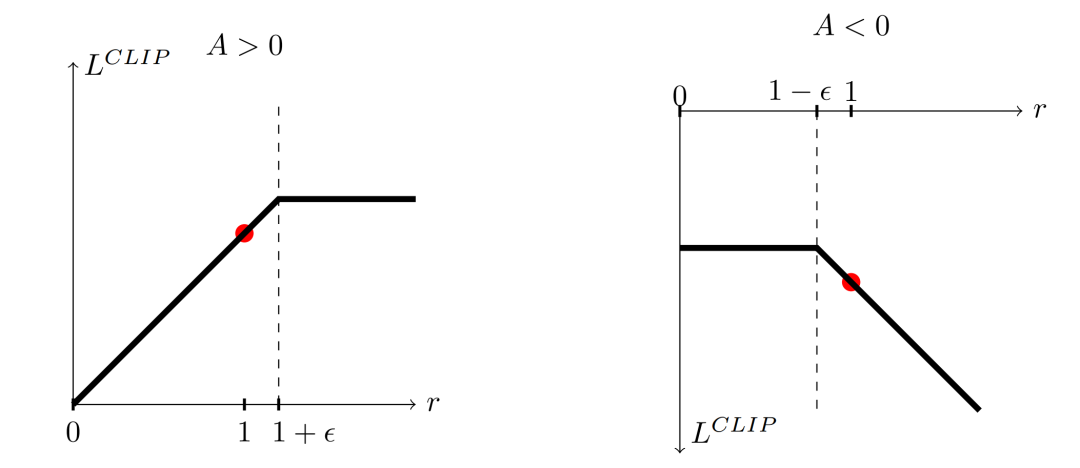
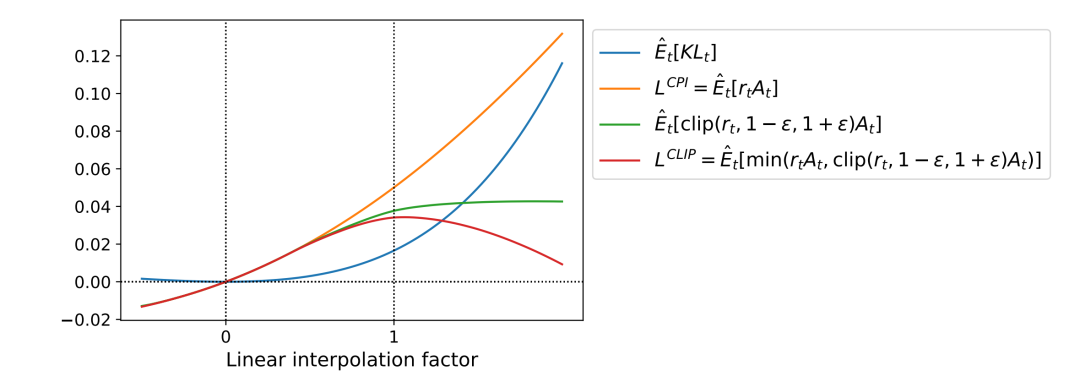
3.4 Adaptive KL Penalty Coefficient
前面讲到采用罚函数法进行参数更新时,主要是罚函数系数的选取比较困难。而现在一种克服方法是自适应调整系数。其优化目标为:计算:
- 若
- 若
算法涉及3个超参数:、、 ,但这三者的敏感性很低,调节并不是很麻烦。效果比CLIP要差,但是可作为一个baseline。采用SGD做一阶优化。
3.5 算法
上一章中第三节介绍了基于TRPO的函数;第四节介绍了基于TRPO的函数。这一节开始介绍完整的PPO算法。PPO算法的完整目标函数: 式中为2个超参数,为信息熵增加探索率,为训练Critic网络的损失函数。这里采用作为替代函数。优势函数的估计基于以下式子:其中。 论文随后给出PPO算法伪代码如下:
3.6 实验
3.6.1 不同目标函数的对比
作者在7个模拟机器人任务上测试了标准策略梯度、、作为目标函数的训练效果,以随机初始化的策略效果作为0,最好的结果作为1,每个目标函数在每个任务上均运行3次,取平均值作为目标函数的评分。实验结果如下所示:

3.6.2 连续空间下与其他算法的对比
作者将TRPO算法、交叉熵、标准策略梯度算法(使用Adam优化,每一个batch后Adam算法的步长根据类似于的方式自适应调整)、A2C、带有置信域的A2C算法在连续空间问题下进行对比。效果如下图所示: 
3.6.3 连续空间下示例
为了展示PPO算法在在高维连续控制问题下的效果,作者训练了一个3D模拟机器人,主要任务包括:向前运动、目标追逐、跌倒爬起,该任务使用作为目标函数训练得到机器人的运动策略。其在三个任务上的学习曲线如下图所示: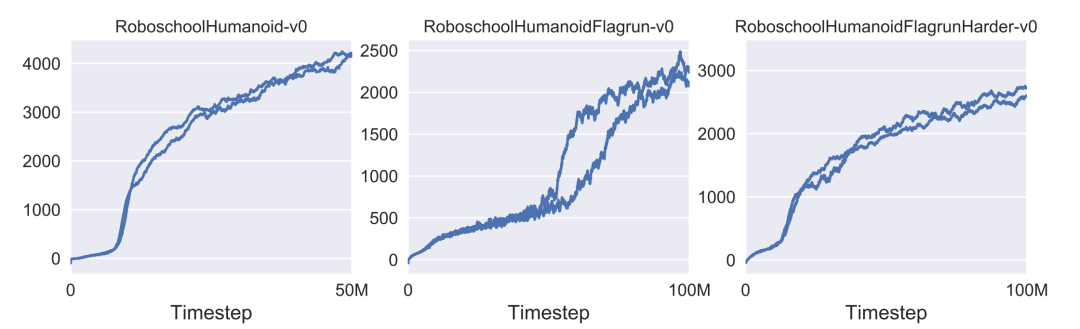

3.6.4 雅达利(游戏)中与其他算法的对比
作者在雅达利发行的49款游戏上测试了PPO以及其他算法的效果,如下表所示:

图16 雅达利游戏中效果3.7 论文总结 PPO 算法在 TRPO 的基础上提出了两种优化后的形式、,并经过大量实验证明了其良好的效果。相比于 TRPO 算法,两种形式均重点解决 TRPO 约束项影响迭代步伐、求解繁琐、实现困难的特点,它们均将约束项转为惩罚项,解决了有约束的优化问题求解繁琐的特点,针对迭代步长过大的问题,将之限制在[1−ϵ, 1 + ϵ]范围内,则自适应地调整惩罚性系数,同样达到了限制步长的效果,与TRPO相比,它们对约束项的处理更加简单优雅,实现也更方便,性能也得到了提升。4 总结与思考PPO 算法自 2017 年提出后,以其实现相对简单、效果优良的特点,在 OpenAI 强化学习相关工作中出现频率极高,在游戏、机器人控制等实际应用领域成功证明其性能,截至目前仍然是基于策略的强化学习算法中最前沿的算法,即使 OpenAI 已经解散其机器人研究组,PPO 算法却又意外的在 NLP 领域大放异彩,其与 GPT-3 的结合成功产生了让人惊艳无比的 ChatGPT,笔者不禁思考,这种 RLHF(Reinforcement Learning Human Feedback)范式下究竟是什么让 ChatGPT 如此强大,是作为 Human Feedback 的高质量语料,还是 PPO 算法中蕴含的策略,还是 GPT-3 中未充分挖掘的大模型潜力?目前高质量数据逐渐成为商业公司的专属,国内大模型的研发也落后于美国,模型提出后缺乏后续维护,没有长期坚持下去形成自己的技术路线,不注重研究的 diversity。而国外部分顶尖研究组已经与 OpenAI 等大公司形成紧密的联系,在相关研究上有着很大的优势,ChatGPT 的出现已经对很多 NLP 研究领域造成了巨大的冲击,面对美国在大模型上的封锁,我国缺乏由商业公司主导的大模型,国内研究组只能另辟蹊径,但大模型的出现到产生 ChatGPT 一般的成果需要漫长的技术积累,若不立刻行动起来,我国与美国在大模型上的差距恐怕会越拉越大。参考文献[1] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. CoRR, abs/1707.07012, 2017.[2] OpenAI. Learning dexterity: a human-like robot hand to manipulate physical objects with unprecedented dexterity. Web Page, 2018. Last Accessed December 23, 2022.[3] Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak,Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680, 2019.[4] OpenAI. Openai five defeats dota 2 world champions. Web Page, 2018. Last Accessed December 23, 2022.[5] OpenAI. Openai spinning up. Web Page, 2018. Last Accessed December 23, 2022.[6] CSDN. 【强化学习笔记】强化学习中的 v 值和 q 值. Web Page, 2022. Last Accessed December 23, 2022.[7] David Silver. Lectures on reinforcement learning.URL:https://www.davidsilver.uk/teaching/, 2015.[8] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. CoRR,abs/2005.01643, 2020.[9] OpenAI. Openai implement code. Web Page, 2018. Last Accessed December 23, 2022.[10] John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In Francis Bach and David Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 1889–1897, Lille, France, 07–09 Jul 2015. PMLR.[11] Lucian Buşoniu, Damien Ernst, Bart De Schutter, and Robert Babuška. Approximate reinforcement learning: An overview. In 2011 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL), pages 1–8. IEEE, 2011.[12] S. Kakade and J. Langford, Approximately Optimal Approximate Reinforcement Learning. Proceedings of the Nineteenth International Conference on Machine Learning: , 2002.
作者简介
陈一帆, 就读于哈尔滨工业大学社会计算与信息检索研究中心,对话技术(DT)组,大四本科生,师从张伟男教授。研究方向为对话式推荐系统。

本期责任编辑:赵森栋本期编辑:赵 阳

