【强化学习】强化学习+深度学习=人工智能
强化学习观点:人工智能=强化学习
强化学习是一种人工智能的通用框架:
RL 是针对一个拥有行动能力的 agent 而言的
每个行动影响了 agent 的未来状态
使用标量值回报信号来度量成功
一言以蔽之:选择行动来最大化未来回报。我们最终的目标是寻求得到可以解决所有人类层级的任务的单一的 agent,这也是智能 agent 的本质。
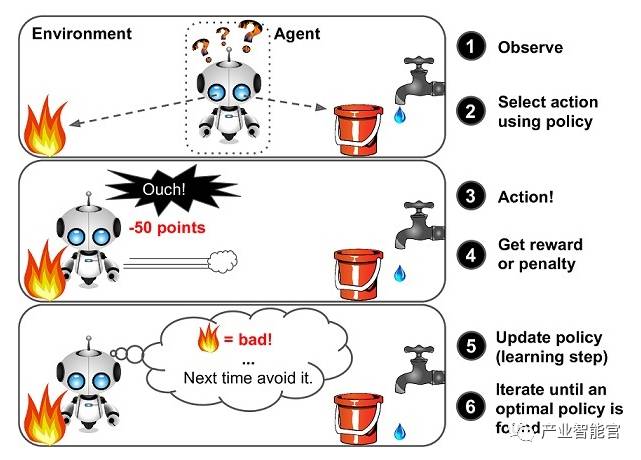
agent 和环境
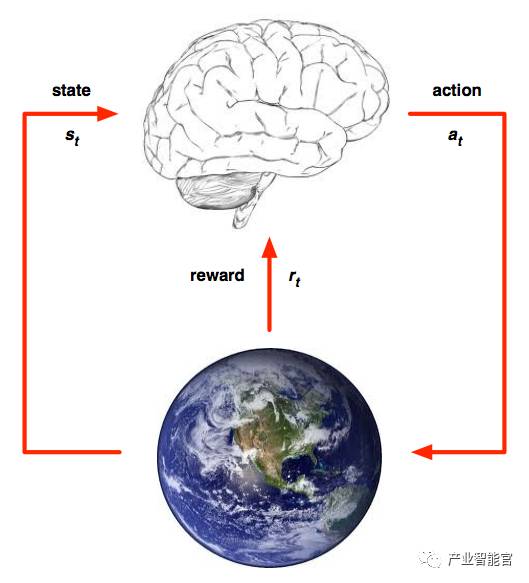
RL 结构
在每个时间步 t,agent:
接受状态 st
接受标量回报 rt
执行行动 at
环境:
接受行动 at
产生状态 st
产生标量回报 rt
策略 policy 和估值 value 函数
策略 π 是给定状态下选择行动的行为函数:
a=π(s)估值函数 Qπ(s, a) 是从状态 s 开始在策略 π 下采取行动 a 的期望全回报:
Qπ(s, a) = E[rt+1+γrt+2+γ2rt+3+...|s, a]
说白了,估值就是评估在状态 s 时采取行动 a 的好坏。
强化学习的几个方向
基于策略的 RL
直接搜索最优策略 π*
目标就是得到最大未来回报的策略
基于值的 RL
估计最优值函数 Q*(s, a)
在任何策略下可获得的最大值
基于模型的 RL
构建一个环境的迁移模型
使用该模型进行规划(通过查找规则)
深度强化学习
自然的,有这样的一个问题,我们能不能将深度学习用在强化学习上?
使用深层网络来表示估值函数/策略/模型
端对端的方式优化估值函数/策略/模型
这样就可以使用随机梯度下降来实现函数的优化
贝尔曼 Bellman 方程
估值函数可以递归展开:
Qπ(s, a)
= E[rt+1 + γrt+2 + γ2 rt+3 + ... | s, a]
= Es' [r + γQπ(s', a') | s, a]最有值函数 Q*(s, a) 可以递归展开为:
Q∗(s, a) = Es'[r + γ maxa' Q∗(s', a') | s, a]估值迭代算法可以解贝尔曼方程:
Qi+1(s, a) = Es' [r + γ maxa' Qi(s', a') | s, a]
深度 Q-学习
通过权重 w 的深层 Q-网络来表示估值函数:Q(s, a, w) ≈ Qπ(s, a)
定义 Q值的均方误差 MSE 作为目标函数:
目标 T=r + γ maxa'Q(s', a', w)
L(w) = E[(T-Q(s,a,w))2]
所以得到下面的 Q-学习的梯度:
∂L(w)/∂w = E[(T-Q(s,a,w)) ∂Q(s,a,w)/∂w]使用 ∂L(w)/∂w 对目标函数使用 SGD 进行端对端优化
深度强化学习的稳定性问题
使用神经网络进行简易的 Q-学习会震荡或者发散,原因如下:
数据是序列化的
时间连续的样本是相关的,不是独立的分布
Q-值微小的变动会剧烈地影响策略
策略可能会震荡
数据分布会从一个极端摇摆到另一个极端
回报和 Q-值的值范围未知
简易的 Q-学习的梯度在反向传播的时候会非常不稳定
深度 Q-网络 DQN
DQN 给出了基于值的深度强化学习一个稳定的解
使用经验回放
打破数据之间的关联,将我们拉回独立同分布的配置下
从所有过去的策略中进行学习
固定目标 Q-网络
避免了震荡
将 Q-网络和目标之间的关联打破
剪切回报或者规范化网络到一个可行的范围内
健壮的梯度
稳定深度强化学习 1:经验回放
为了移除关联,从 agent 自身的经验中构建数据集合:
根据 ε-贪婪策略选择行动 at
将迁移 (st, at, rt+1, st+1)存入经验内存 D 中
从 D 中采样随机 minibatch 的迁移 (s, a, r, s')
优化Q-网络和Q-学习之间的 MSE:
L(w) = Es,a,r,s'∼D[(r + γ maxa'Q(s', a', w) − Q(s, a, w))2]
稳定深度强化学习 2:固定目标 Q-网络
为了避免震荡,固定在 Q-学习目标中使用的参数
使用老的固定的参数 w-计算 Q-学习目标:
r + γ maxa'Q(s', a', w-)优化 Q-网络和 Q-学习目标间的 MSE
L(w) = Es,a,r,s'∼D[(r + γ maxa'Q(s', a', w-) − Q(s, a, w))]周期性地更新固定参数:w- ← w
稳定深度强化学习 3:回报/值范围
DQN 剪切回报在 [-1, +1] 范围内
保证 Q-值不会变得太大
确保梯度有良好的条件 well-conditioned
不能够区分小的或者大的回报
使用强化学习来玩 Atari 游戏
这确实是一个很自然的应用。
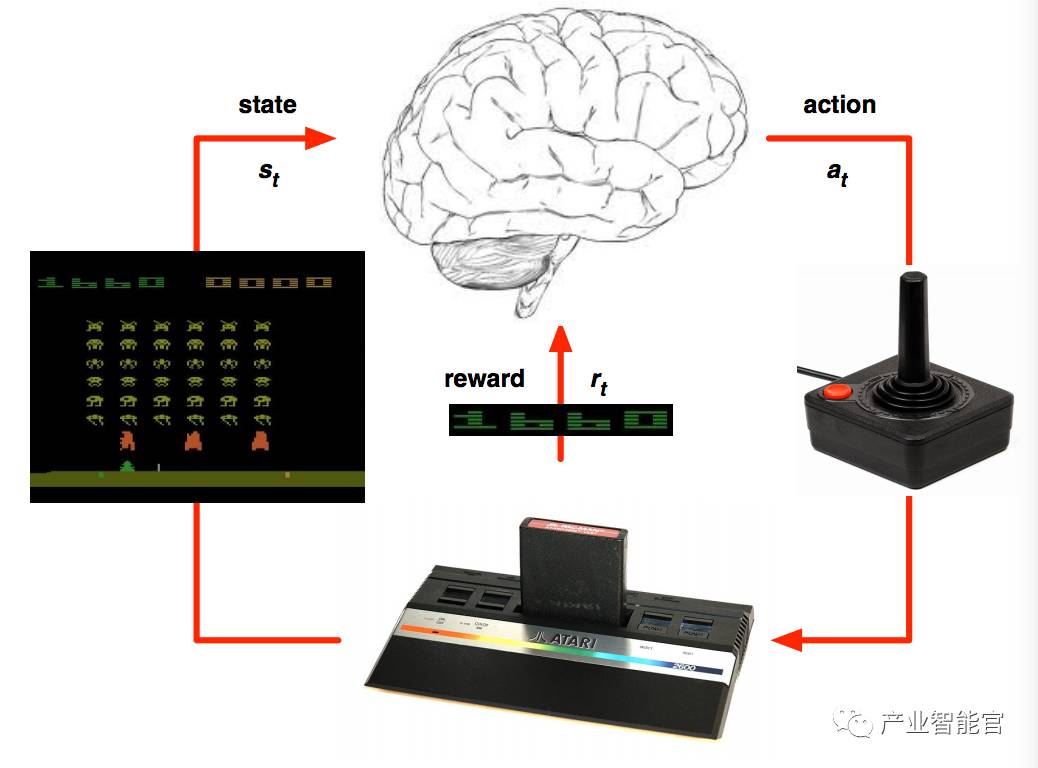
Atari 游戏
DQN 用在 Atari 游戏中
从像素 s 中端对端学习值 Q(s, a)
输入状态 s 就是来自过去 4 帧的原始像素的栈
输出是对应于 18 个的手柄或者按钮位置的 Q(s, a)
回报则在那个步骤根据分值进行改变
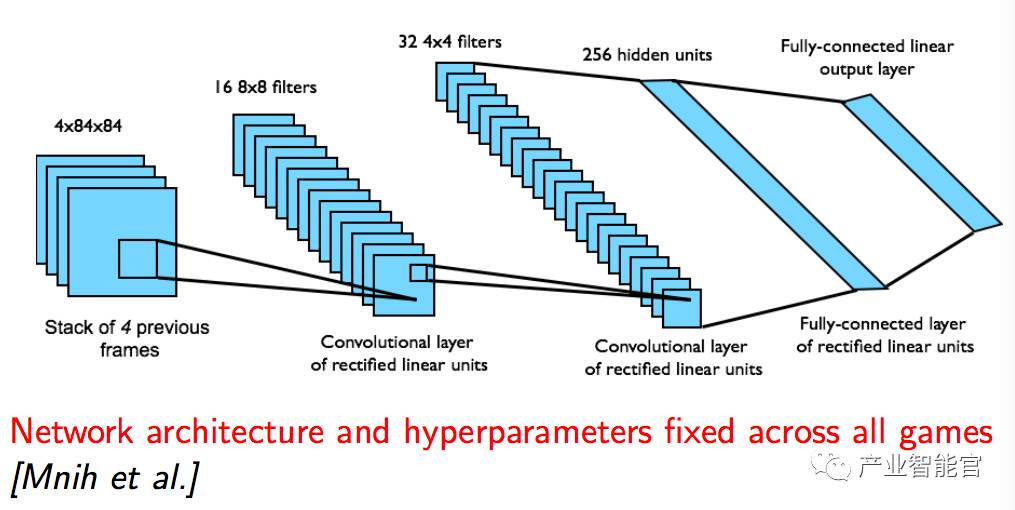
Minh et al.
DQN 在 Atari 游戏中的结果
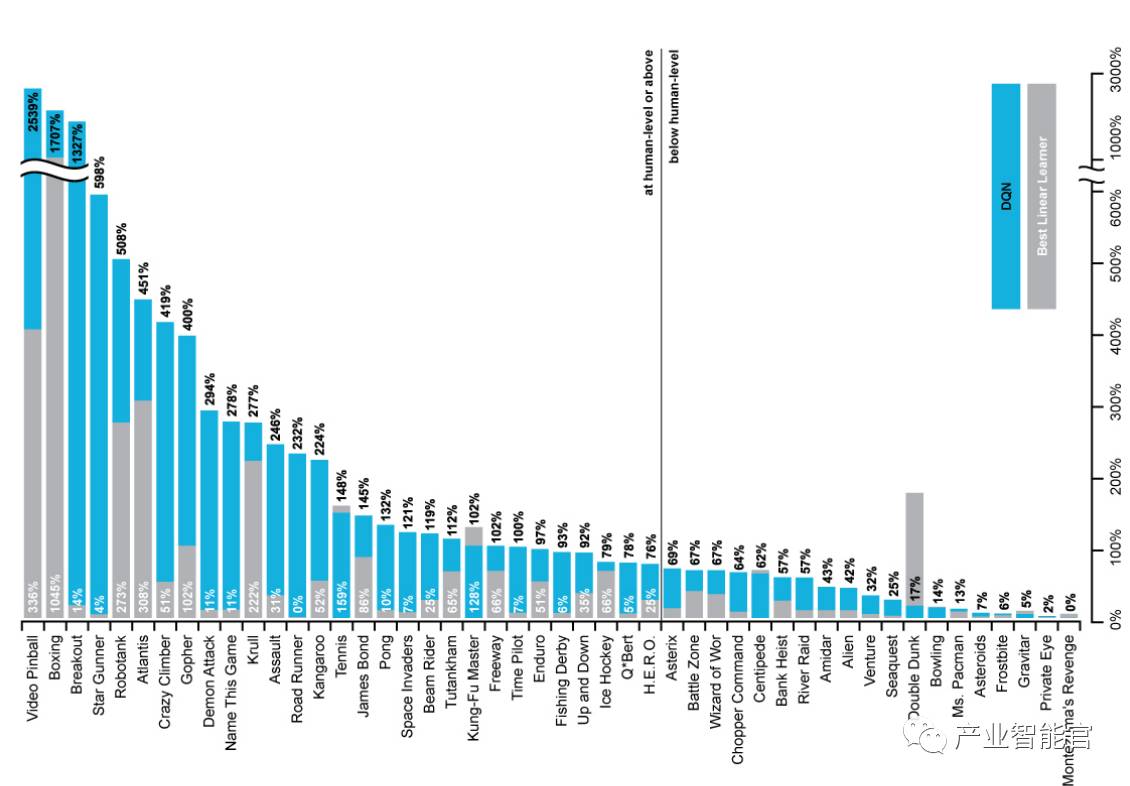
results
Demo 省略
DQN 起到多大作用
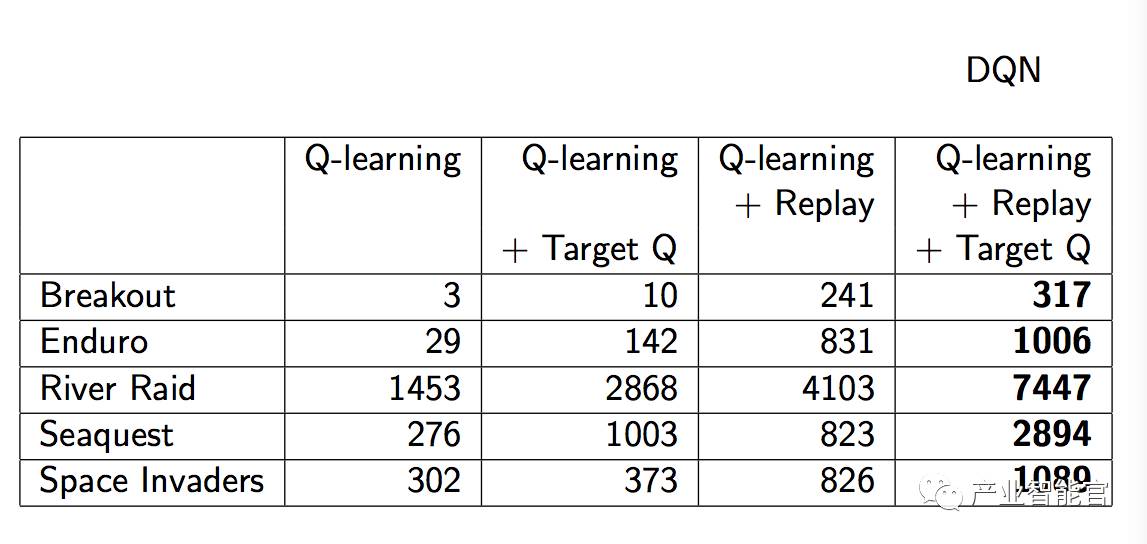
DQN improvements
规范化 DQN
规范化 DQN 使用真实(非剪切)的回报信号
网络输出一个在稳定范围内的标量值,
U(s, a,w) ∈ [−1, +1]输出被重新规范值范围并被转化成 Q-值,
Q(s, a,w, σ, π) = σU(s, a,w) + ππ, σ 会调整成确保 U(s, a,w) ∈ [−1, +1]
网络参数 w 被调整来确保 Q-值是一个常量
σ1U(s, a,w1) + π1 = σ2U(s, a,w2) + π2
Demo 省略(规范化的 DQN 在 PacMan 中的表现)
Gorila(GOogle ReInforcement Learning Architecture)
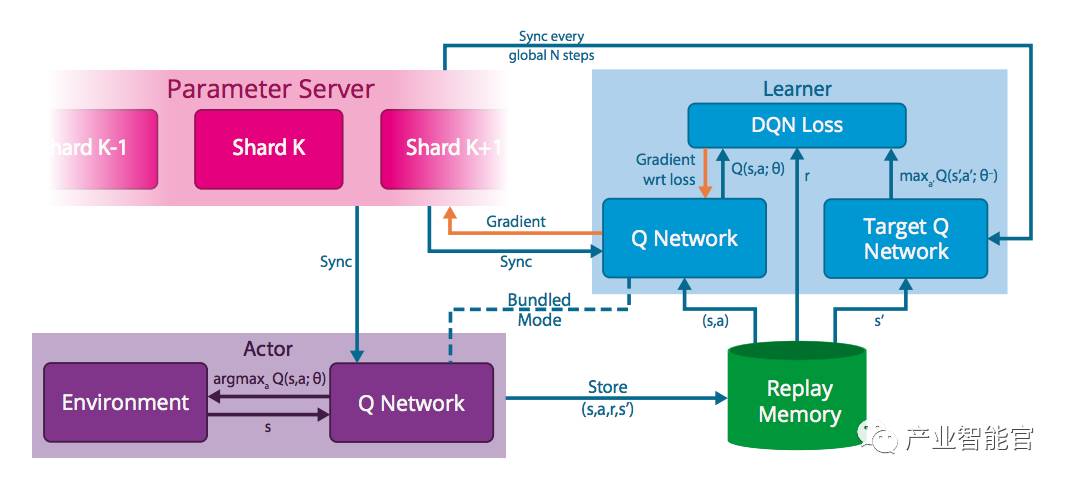
Gorila 架构
并行行动:产生新的交互
分布式回放记忆:保存上面产生的交互
并行学习:从回放的交互中进行梯度计算
分布式神经网络:用上面产生的梯度来更新网络
稳定深度强化学习 4:并行更新
Vanilla DQN 在并行时表现得不稳定。我们使用下面的方式克服这个问题:
丢弃陈旧的(stale)梯度
丢弃利群点梯度 g > µ + kσ
AdaGrad 优化技术
Gorila 结果
使用 100 并行行动器和学习器
Gorila 显著地超过了 Vanilla DQN 的性能:49 个 Atari 游戏中的 41 个游戏中
Gorila 达到了 2 倍与 Vanilla DQN 的分数:49 个 Atari 游戏中的 22 个游戏中
Gorila 达到同样的性能却比 Vanilla DQN 快 10 倍:49 个 Atari 游戏中的 38 个游戏中
Gorila DQN 在 Atari 中的结果:
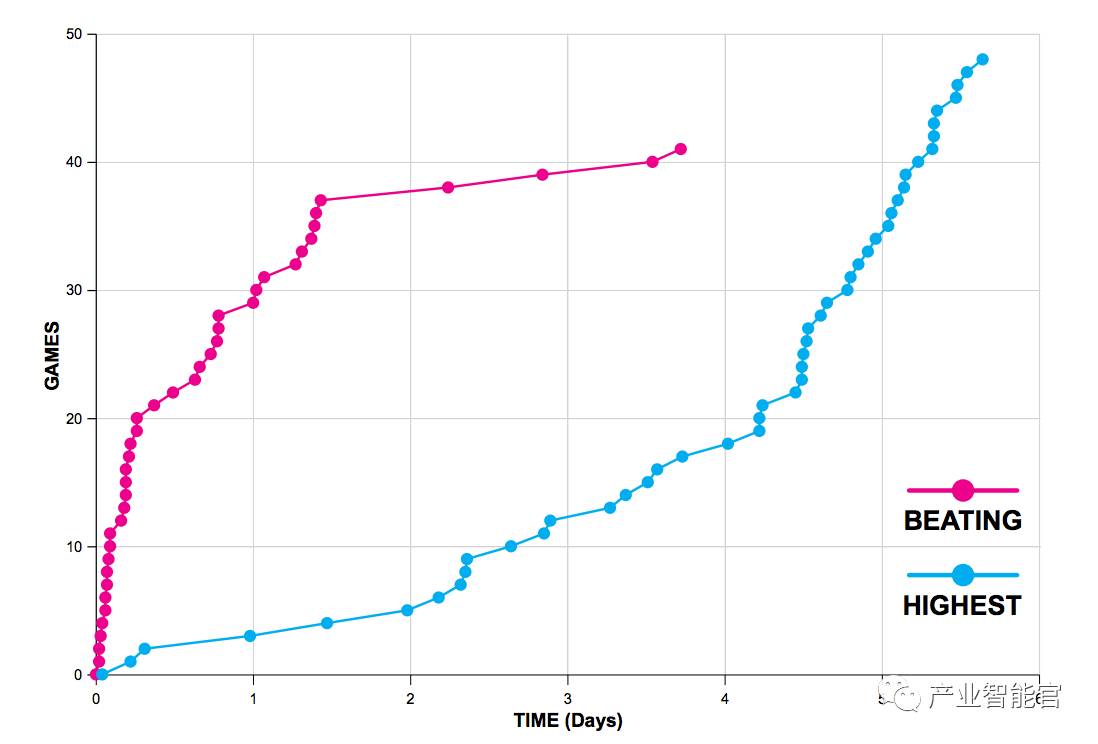
Paste_Image.png
连续行动的确定性策略梯度
使用权重为 u 的深度网络 a = π(s, u) 表示确定性策略
定义目标函数为全部折扣回报
J(u) = E[r1 + γr2 + γ2 r3 + ...]端对端通过 SGD 来优化目标函数
∂J(u)/∂u = Es[(∂Qπ(s, a)/∂a) (∂π(s, u)/∂u)]在提高 Q 最大的方向更新策略
即通过行动器 actor 来反向传播评价(critic)
确定性 Actor-Critic 模型
使用两个网络:actor 和 critic
critic 通过 Q-学习来估计当前策略的值
∂L(w)/∂w = E[(r + γQ(s', π(s'), w) − Q(s, a,w)) ∂Q(s, a,w)/∂w]actor 按照提高 Q 的方向更新策略
∂J(u)/∂u = Es[∂Q(s, a, w)/∂a ∂π(s, u)/∂u]
确定性深度 Actor-Critic
简易的 actor-critic 使用神经网络会震荡或者发散
DDAC 给出了一个稳定解决方案
对 actor 和 critic 都使用经验回放
使用目标 Q-网络来避免震荡
∂L(w)/∂w = Es,a,r,s'∼D [(r + γQ(s', π(s'), w−) − Q(s, a, w)) ∂Q(s, a, w)/∂w]
∂J(u)/∂u = Es,a,r,s'∼D [∂Q(s, a, w)/∂a ∂π(s, u)/∂u]
DDAC 进行连续行动控制
从原始像素 s 进行控制策略的端对端学习
输入状态 s 是最近 4 个帧的原始像素的栈
两个分隔开的卷积网络用于 Q 和 π
物理行为在 MuJoCo 中模拟
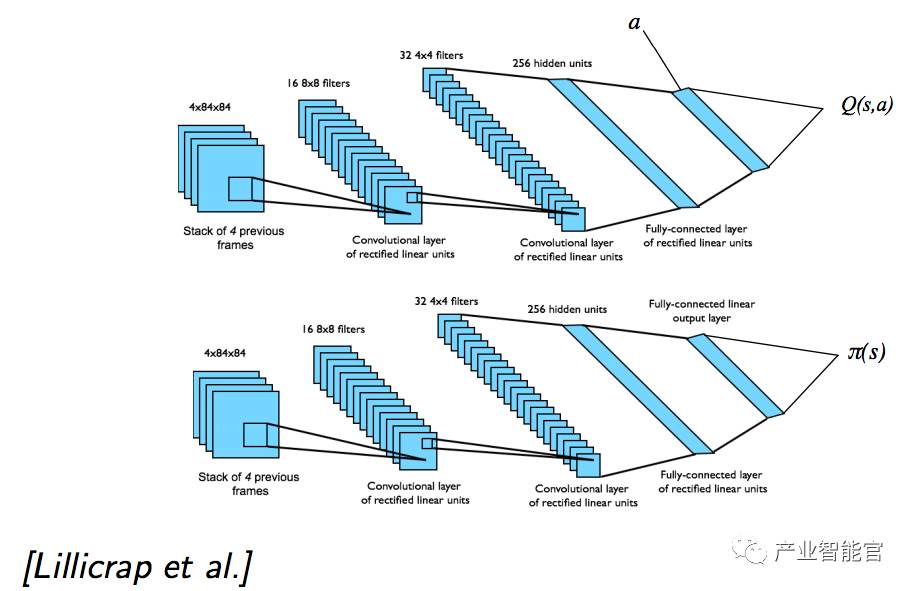
DDAC 架构
DDAC demo 略
基于模型的强化学习
其目标是学习一个环境转移模型:
p(r, s'| s, a)
使用转移模型进行规划
例如,通过转移模型来查找最优的行动
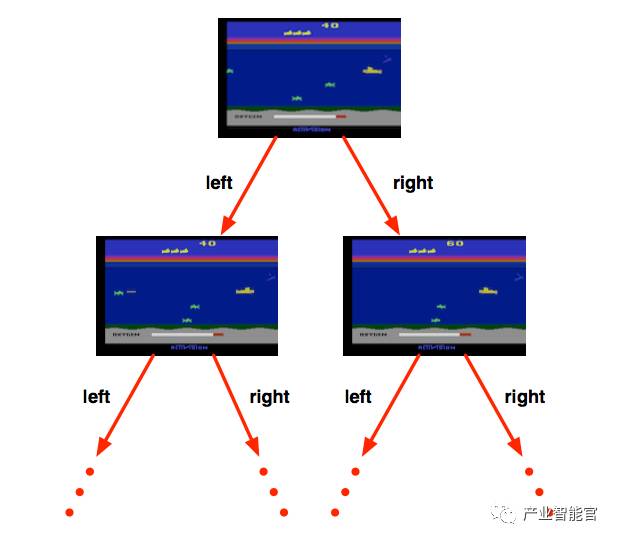
Model-Based RL
深度模型
使用深度网络来表示转移模型 p(r, s'| s, a)
定义目标函数衡量模型的好坏
比如,重构下一状态的比特数目 (Gregor et al.)
通过 SGD 来优化目标函数
DARN Demo 略
基于模型的强化学习的挑战
复合错误:
转移模型转移路径符合的错误
长的状态转移路径的结尾,回报可能完全错误
基于模型的强化学习在 Atari 中失效
深度估值/策略网络可以隐式地进行规划
网络每层执行任意一步计算
n层网络可以向前看 n 步
到底是否需要转移模型呢?
深度学习应用在围棋中
Monte-Carlo 搜索
Monte-Carlo 搜索(MCTS)模拟未来的转移路径
构建很大的拥有数百万位置的查找搜素树
目前最好的 19 X 19 的围棋程序就是使用 MCTS 技术 (Gelly et al.)
卷积网络
12-层卷积网络用来训练预测专家走法
原始卷积网络(只看一个位置,不含搜索)
等价于拥有 105 位置的搜索树 MoGo 的性能 (Maddison et al.)

Paste_Image.png
结论
强化学习给出了一种通用的人工智能框架
强化学习问题可以通过端对端深度学习技术来解决
单一的 agent 现在已经能解决很多具有挑战性的任务
强化学习+深度学习=人工智能
强化学习的场景
1、控制物理系统:行走、飞行、驾驶、游泳、……
2、与用户进行交互:客户维护retain customers、个性化频道personalisechannel、用户体验优化optimiseuser experience、……
3、解决问题:规划scheduling、带宽分配bandwidth allocation、电梯控制、认知无线电cognitive radio、电力优化power optimisation、……
4、玩游戏:棋类、扑克、围棋、Atari 游戏、……
5、学习序列化算法:注意力attention、记忆memory、条件计算conditional computation、激活activation
强化学习应用举例
强化学习有很多应用,除了无人驾驶,AlphaGo,玩游戏之外,还有下面这些工程中实用的例子:
1. Manufacturing
例如一家日本公司 Fanuc,工厂机器人在拿起一个物体时,会捕捉这个过程的视频,记住它每次操作的行动,操作成功还是失败了,积累经验,下一次可以更快更准地采取行动。
2. Inventory Management
在库存管理中,因为库存量大,库存需求波动较大,库存补货速度缓慢等阻碍使得管理是个比较难的问题,可以通过建立强化学习算法来减少库存周转时间,提高空间利用率。
3. Dynamic pricing
强化学习中的 Q-learning 可以用来处理动态定价问题。
4. Customer Delivery
制造商在向各个客户运输时,想要在满足客户的所有需求的同时降低车队总成本。通过 multi-agents 系统和 Q-learning,可以降低时间,减少车辆数量。
5. ECommerce Personalization
在电商中,也可以用强化学习算法来学习和分析顾客行为,定制产品和服务以满足客户的个性化需求。
6. Ad Serving
例如算法 LinUCB (属于强化学习算法 bandit 的一种算法),会尝试投放更广范围的广告,尽管过去还没有被浏览很多,能够更好地估计真实的点击率。
再如双 11 推荐场景中,阿里巴巴使用了深度强化学习与自适应在线学习,通过持续机器学习和模型优化建立决策引擎,对海量用户行为以及百亿级商品特征进行实时分析,帮助每一个用户迅速发现宝贝,提高人和商品的配对效率。还有,利用强化学习将手机用户点击率提升了 10-20%。
7. Financial Investment Decisions
例如这家公司 Pit.ai,应用强化学习来评价交易策略,可以帮助用户建立交易策略,并帮助他们实现其投资目标。
8. Medical Industry
动态治疗方案(DTR)是医学研究的一个主题,是为了给患者找到有效的治疗方法。 例如癌症这种需要长期施药的治疗,强化学习算法可以将患者的各种临床指标作为输入 来制定治疗策略。

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
数字化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。随着变革范围不断扩大,一切都几乎变得不确定,即使是最精明的领导者也可能失去方向。面对新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)颠覆性的数字化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位。
如果不能在上述三个层面保持领先,领导力将会不断弱化并难以维继:
重新进行行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建你的企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造新的自己:你需要成为怎样的人?要重塑自己并在数字化时代保有领先地位,你必须如何去做?
子曰:“君子和而不同,小人同而不和。” 《论语·子路》
云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。
在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。
云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
人工智能通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
新一代信息技术(云计算、大数据、物联网、区块链和人工智能)的商业化落地进度远不及技术其本身的革新来得迅猛,究其原因,技术供应商(乙方)不明确自己的技术可服务于谁,传统企业机构(甲方)不懂如何有效利用新一代信息技术创新商业模式和提升效率。
“产业智能官”,通过甲、乙方价值巨大的云计算、大数据、物联网、区块链和人工智能的论文、研究报告和商业合作项目,面向企业CEO、CDO、CTO和CIO,服务新一代信息技术输出者和新一代信息技术消费者。
助力新一代信息技术公司寻找最有价值的潜在传统客户与商业化落地路径,帮助传统企业选择与开发适合自己的新一代信息技术产品和技术方案,消除新一代信息技术公司与传统企业之间的信息不对称,推动云计算、大数据、物联网、区块链和人工智能的商业化浪潮。
给决策制定者和商业领袖的建议:
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机
器智能,为企业创造新商机;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及创造
性思维等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多
样性的文化也非常重要。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。
重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)正在经历从“概念”到“落地”,最终实现“大范围规模化应用,深刻改变人类生活”的过程。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com


