【强化学习】如何开启强化学习的大门?

来源:Medium
编译:Tom Ren
最近几年机器学习算法特别是神经网络为AI带来了全新的变革。在这篇文章中我们会用通俗易懂的语言来帮助你理解强化学习的本质,同时给出强化学习的能力范围。在文末还为读者提供了一些强化学习的资源和实现方式的链接,希望能帮助你愉快地开始强化学习的旅程。
何谓强化学习?
我们通常将数据驱动的算法分为三类:监督学习,非监督学习和强化学习。前两类算法已经被广泛用于图像分类和识别等任务中,并取得了很高的准确率,但这似乎与我们所期待的AI有所不同。而这正是强化学习擅长的地方。
强化学习的概念十分简单,很像进化的过程:环境会奖励主体采取的正确行为,而惩罚错误的行为。而最主要的挑战却来自于训练出一种能在数百万种可能性中选择正确行为的能力。
Q学习和深度Q学习
Q学习被广泛应用于强化学习中。主体行为的质量(Quality)取决于其所处的状态。主体往往会采取能够最大化奖励的行为。
具体的数学细节请参阅>>https://en.wikipedia.org/wiki/Q-learning
在这一算法中主体根据环境对于每一个行为的奖励来学习每一个行为的质量(Q值)。环境状态值与对应Q值被存储在一个表格里。当主体与环境发生相互作用时,表格中的Q值就会不断更新,以帮助主体最大化从环境中获得的奖励。
深度Q学习
Q学习对于强化学习很不错,但当环境状态的数量变得很大时,这种算法就无法很好的处理强化学习的问题了。这时就需要深度强化学习来解决。深度学习可以看成是一种具有普适性的近似机器,它可以理解并提出抽象的表示。于是在强化学习中便利用了深度学习来近似Q值,并可以利用梯度下降来方便地得到优化后的Q值。
一个有趣的事实:谷歌有一个关于深度Q学习的专利
https://www.google.com/patents/US20150100530

探索与开发(Exploration vs Exploitation)
通常情况下,强化学习中的主体会记住一条路径却从不会去探索其他的路径。但我们希望它可以尽可能多的探索新的路径,于是便引入了一个名为ε的超参数,它可以用来控制算法分别以多大的比例去探索新的路径,以多大的比例去开拓原有的路径。
经验回放(Experience Replay)
在训练神经网络的过程中数据的不平衡会带来很多问题。如果一个模型通过主体与环境的交互进行训练的话就会产生不平衡的问题。最近的几次训练交互过程将会产生比先前的更显著的影响。
所以我们会将所有的状态和相关的数据都存储下来,而后神经网络将会随机的从中选取相应的交互状态并进行学习,以此来避免数据不均衡的问题。
训练架构
这是深度Q学习的完整架构。需要注意的是【γ】这代表了折扣奖励(Discounted Reward)。这是一个用于控制未来奖励权重的超参数。符号【'】代表下一个次,【s’】就意味着下一个状态。

深度Q学习的训练架构
扩展强化学习

强化学习在大多数情况下都有良好的表现(AlphaGo),但当得到的反馈比较稀疏的情况却会出现问题。主体在很多时候都不会去探索那些长期获益的行为。有时候比起直接去解决问题,主体通过内部动机来对一些行为进行探索也是必须的。这使得主体可以表现出复杂的行为,同时本质上也使得主体有了“计划”行为的能力。分层学习使得这样的抽象学习成为可能。
分层深度Q学习
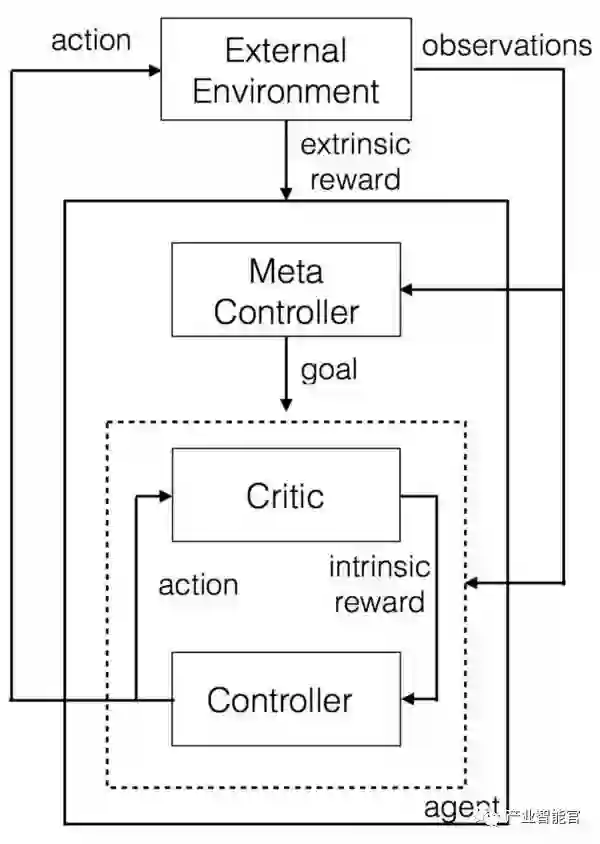
分层深度Q学习
这一架构中有两个Q网络,分别代表控制器和超控制器。超控制器寻找原始的状态并计算出需要实现的目标,而控制器则控制状态向着目标前进,并输出用于解决这一目标的策略。在通过严格的检验后如果目标达成则会给与控制器相应的奖励。当迭代周期完成或者达到目标时控制器便停止工作,并生成一定的奖励给予控制器。随后超控制器会选择新的目标,并重复上面的过程。这其中的‘目标’是用来帮助主体获得最后的奖励。
好了,以上就是强化学习的一些基本概念。大家一定想更深入地了解强化学习,也想尝试一下强化学习啦,下面就是一些给大家提供的资料。
强化学习的入门资料
The Basics of Deep Q Learning.
对于理解强化学习的数学和过程十分有用。
https://www.intelnervana.com/demystifying-deep-reinforcement-learning/
分层学习
Hierarchical Learning paper explanation video from the authors.
https://arxiv.org/pdf/1604.06057.pdf https://www.youtube.com/watch?v=tyRUql_ZR7Q
Deep RL: An Overview 强化学习的手册
包括当今强化学习研究的方方面面,深入浅出的为你展示出强化学习的全貌!
https://arxiv.org/abs/1701.07274
Implementing Deep Q learning with a single python script
https://gist.github.com/EderSantana/c7222daa328f0e885093#file-qlearn-py-L157

Deep Q Learning in action. Output of python script in Point 5
也许是有史以来最简单的深度Q学习的Python实现,简单易读可以作为实践强化学习不错的开始~
-END-

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



