【干货】强化学习介绍
【导读】由于Alpha Go的成功,强化学习始终是人们谈论的焦点。现在Thomas Simonini在国外blog网站上发布了系列强化学习教程,以下是本系列的第一篇,简单介绍了强化学习的基本概念,感兴趣的同学也可以直接到原网站查看:https://medium.freecodecamp.org/@thomassimonini
作者 | Thomas Simonini
编译 | 专知
整理 | Yongxi
An introduction to Reinforcement Learning
我们基于TensorFlow制作了一门深度强化学习的视频课程【1】,主要介绍了如何使用TensorFlow实现强化学习问题求解。
强化学习是机器学习的一种重要分支,通过“agent ”学习的方式,得出在当前环境下所应该采取的动作,并观察得到的结果。
最近几年,我们见证了了许多研究领域的巨大进展,例如包括2014年的“DeepMind and the Deep Q learning architecture”【2】,2016年的“beating the champion of the game of Go with AlphaGo”【3】,2017年的“OpenAI and the PPO”【4】
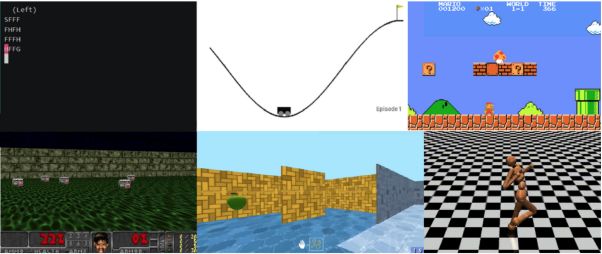
在这个系列文章中,我们将关注于深度学习问题中各类不同的求解方法。包括Q-learning,Deep Q-learning,策略梯度,Actor Critic,以及PPO。
在第一篇文章中,你将会学到:
强化学习是什么,为什么说“奖励”是最重要的思想。
强化学习的三个方法。
深度强化学习中的“深度”是什么意思?
在进入深度学习实现的主题之前,一定要把这些元素弄清楚。
强化学习背后的思想是,代理(agent)将通过与环境(environment)的动作(action)交互,进而获得奖励(reward)。

从与环境的交互中进行学习,这一思想来自于我们的自然经验,想象一下当你是个孩子的时候,看到一团火,并尝试接触它。
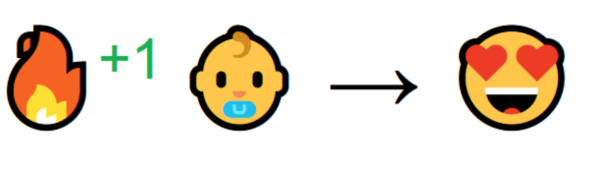
火很温暖,你感觉很开心(奖励+1)。你就会觉得火是个好东西。
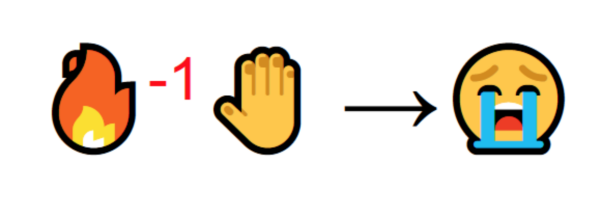
可一旦你尝试去触摸它。哎呦!火把你的手烧伤了(惩罚-1).你才明白只有与火保持一定距离,才会产生温暖,才是个好东西,但如果太过靠近的话,就会烧伤自己。
这一过程是人类通过交互进行学习的方式。强化学习是一种可以根据行为进行计算的学习方法。
强化学习的过程
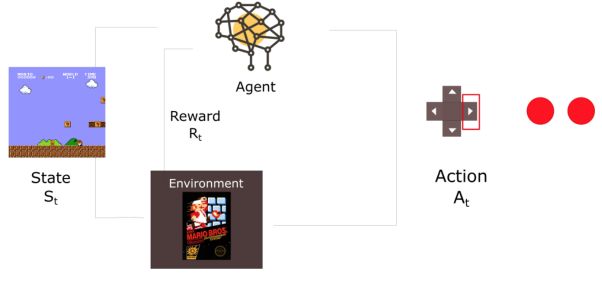
举个例子,思考如何训练agent 学会玩超级玛丽游戏。这一强化学习过程可以被建模为如下的一组循环过程。
agent从环境中接收到状态S0。(此案例中,这句话意思是从超级玛丽游戏中得到的第一帧信息)
基于状态S0,agent执行A0操作。(右移)
环境转移至新状态S1。(新一帧)
环境给予R1奖励。(没死:+1)
强化学习循环输出状态、行为、奖励的序列。整体的目标是最大化全局reward的期望。
奖励假设是核心思想
在强化学习中,为了得到最好的行为序列,我们需要最大化累积reward期望。
每个时间步的累积reward可以写作:
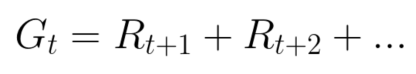
等价于:
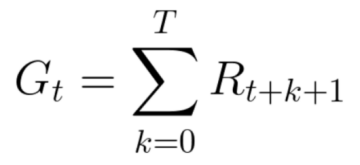
然而,在现实世界中,我们不能仅仅加入奖励。这种奖励来的太快,且发生的概率非常大,因此比起长期奖励来说,更容易预测。

另一个例子中,agent 是老鼠,对手是猫,目标是在被猫吃掉之前,先吃掉最多的奶酪。
从图中可以看到,吃掉身边的奶酪要比吃掉猫旁边的奶酪,要容易许多。
由于一旦被猫抓住,游戏即将结束,因此,猫身边的奶酪奖励会有衰减。
我们对折扣的处理如下所示(定义gamma为衰减比例,在0-1之间):
Gamma越大,衰减越小。这意味着agent 的学习过程更关注于长期的回报。
另一方面,更小的gamma,会带来更大的衰减。这意味着我们的agent 关心于短期的回报。
衰减后的累计奖励期望为:
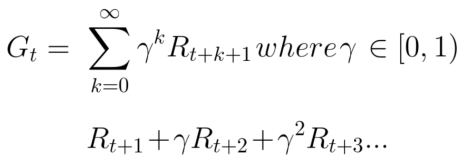
每个时间步间的奖励将与gamma参数相乘,获得衰减后的奖励值。随着时间步骤的增加,猫距离我们更近,因此为未来的奖励概率将变得越来越小。
事件型或者持续型任务
任务是强化学习问题中的基础单元,我们可以有两类任务:事件型与持续型。
事件型任务
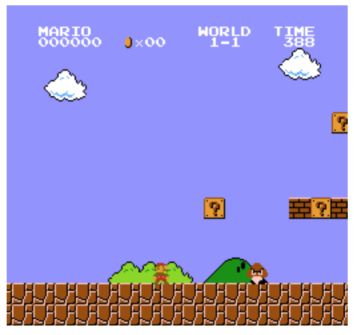
在这一情况中,我们有一个起始点和终止点(终止状态)。这会创建一个事件:一组状态、行为、奖励以及新奖励。
对于超级玛丽的情况来说,一个事件从游戏开始进行记录,直到角色被杀结束。
持续型任务
持续型任务意味着任务不存在终止状态。在这一案例中,agent 将学习如何选择最好的动作,并与环境同步交互。
例如,通过agent 进行自动股票交易。在这个任务中,并不存在起始点和终止状态,直到我们主动终止之前,agent 将一直运行下去。
蒙特卡洛与时间差分学习方法
接下来将学习两种方法:
蒙特卡洛方法:在事件结束后收集奖励,进而计算未来奖励的最大期望。
时间差分学习:在每一个时间步进行估计计算。
蒙特卡洛方法
当时间结束时(agent 达到“终止状态”),agent 将看到全部累积奖励,进而计算它将如何去做。在蒙特卡洛方法中,奖励只会在游戏结束时进行收集。
从一个新游戏开始,agent 将会随着迭代的进行,完成更好的决策。

举例如下:

如果我们在如上环境中:
总是从相同位置开始
当被猫抓到或者移动超过20步时,事件终止。
在事件的结尾,我们得到一组状态、行为、奖励以及新状态。
agent 将对整体奖励Gt求和。
基于上面的公式对V(st)求和
根据更新的认知开始新的游戏
随着执行的事件越来越多,agent 学习的结果将越来越好。
时间查分学习:每步更新
对于时序差分学习,不需要等到每个事件终止便可以根据未来奖励的最大期望估计进行更新。
这种方法叫做TD(0)或者单步TD方法(在每个步骤间隔进行值函数更新)。
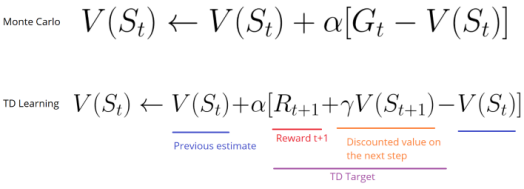
TD方法在每一步进行值函数评估更新。在t+1时,立刻观察到奖励Rt+1,并得到当前的评估值V(st+1)。
TD 的目标是得到评估值,并根据单步的估计值完成前一个估计值V(st)更新。
探索/开发间的平衡
在继续了解其他细节之前,我们必须介绍一个非常重要的主题:探索与开发之间的平衡。
探索是为了发现环境的更多信息
开发是为了根据已知信息去最大化奖励值。
记住,我们agent 的目标是为了最大化累积奖励的期望,然而,我们可能陷入到一个常见的陷阱中。

在游戏中,老鼠可以获得无限的小奶酪(1次获得1个),但在迷宫的上部,有一个超大的奶酪包裹(1次可获得1000个)。
然而,如果我们只关注于奖励,agent 将永远无法达到奶酪包裹处。并且,它将会仅去探索最近的奖励来源,即使这个奖励特别小(开发,exploitation)。
但如果agent 进行一点小小的探索工作,就有可能获得更大的奖励。
这就是探索与开发的平衡问题。我们必须定义出一个规则,帮助agent 去解决这个平衡。我们将在未来文章中通过不同策略去解决这一问题。
强化学习的三种方法
现在我们定义了强化学习的主要元素,接下来将介绍三种解决强化学习问题的方法,包括基于值的方法、基于策略的方法与基于模型的方法。
基于值的方法
在基于值的强化学习方法中,目标是优化值函数V(s)。
值函数的作用是,告诉我们在每个状态下,未来最大化的奖励期望。
值是每个状态条件下,从当前开始,在未来所能取得的最大总回报的值。
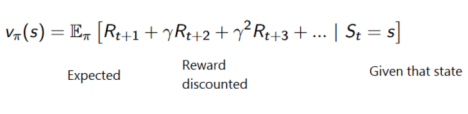
agent 将使用值函数去在每一步选择采用哪个状态。
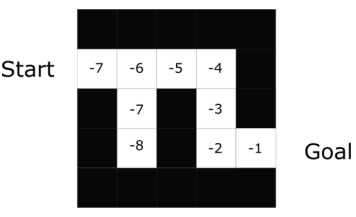
在迷宫问题中,在每一步将选择最大值:-7,-6,-5等等。
基于策略的方法
在基于策略的强化学习方法中,我们希望能直接优化策略函数π(s) 。
策略的定义是,在给定时间的agent 行为。

通过学习到策略函数,可以让我们对每个状态映射出最好的相关动作。
两种策略:
确定策略:在给定状态下总是返回相同动作。
随机策略:输出一个动作的概率分布。
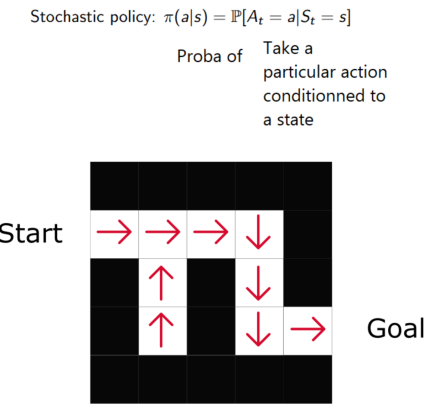
如同我们看到的,策略直接指出了每一步的最优行为。
基于模型的方法
在基于模型的强化学习中,我们对环境建模,这意味着我们创造了环境的模型。
问题是,每种行为都需要不同的模型表示,这就是为什么在接下来的文章中并没有提及此类方法的原因。
深度强化学习的介绍
深度强化学习采用深度神经网络以解决强化学习问题。
在例子中,在下一篇文章我们将采用Q-learning与深度Q-learning。
你将会看到显著地不同,在第一种方法中,我们将使用一个传统算法那去创建Q值表,以帮助我们找到每种状态下应采用的行为。第二种方法中,我们将使用神经网络(得到某状态下的近似奖励:Q 值)。
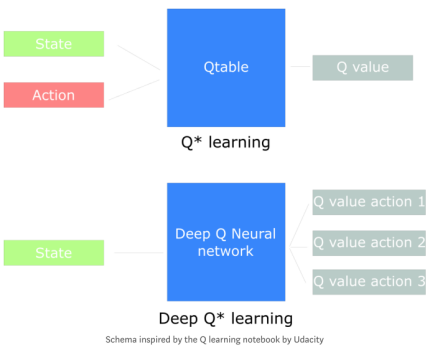
这篇文章里有很多信息,在继续进行之前,一定要真正掌握住基础知识。
重点:这篇文章是这一免费的强化学习博文专栏的第一部分。关于更多的资源,见此链接【5】.
下一次我们将基于Q-learning训练agent 去玩Frozen Lake 游戏。
https://youtu.be/q2ZOEFAaaI0
https://deepmind.com/research/dqn/
https://deepmind.com/research/alphago/
https://blog.openai.com/openai-baselines-ppo/
https://simoninithomas.github.io/Deep_reinforcement_learning_Course/
原文链接:
https://medium.freecodecamp.org/an-introduction-to-reinforcement-learning-4339519de419
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




