
离线强化学习(Offline RL)作为深度强化学习的子领域,其不需要与模拟环境进行交互就可以直接从数据中学习一套策略来完成相关任务,被认为是强化学习落地的重要技术之一。本文详细的阐述了强化学习到离线强化学习的发展过程,并就一些经典的问题进行了解释和说明。
- 深度强化学习 1.1 深度强化学习简介
强化学习发展的特别早,但一直不温不火,其中Sutton老爷子早在1998年就写了强化学习领域的圣经书籍:An Introduction : Reinforcement Learning ,但也并未开启强化学习发展的新局面。直到2012年,深度学习广泛兴起,大规模的神经网络被成功用于解决自然语言处理,计算机视觉等领域,人工智能的各个方向才开始快速发展,强化学习领域最典型的就是2013年DeepMind公司的Volodymyr Mnih发表Playing Atari with Deep Reinforcement Learning(DQN技术),可以说开启了深度强化学习技术发展的新高潮,2015年该论文的加强版Human-level control through deep reinforcement learning 登上Nature, 以及2016年Nature上的AlphaGo: Mastering the game of Go with deep neural networks and tree search 充分证明了深度强化学习技术的发展潜力。
传统的强化学习和监督学习、非监督学的区别在于,后两者是通过从已标记(Label)和无标记的数据中学习一套规律(我们可以理解为学习一个函数表达式),而前者强化学习则是通过行为交互来学习一套策略,以最大化累计期望奖励,结构如图所示:
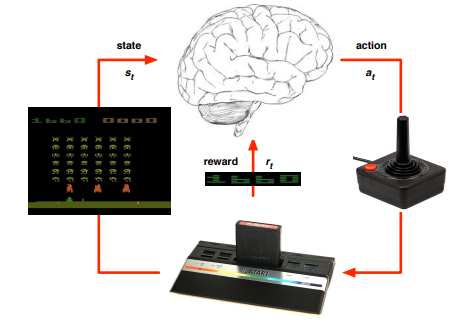
其学习过程可以归纳为通过agent获取环境状态, 根据自身学习到的知识做出action反馈给环境,并得到一个奖励,不断地迭代出一个可以一直玩游戏并且不会死的智能体。原理就是从一个四元组$<s, a,="" r,="" s^{'}="">$中学习出策略,不论出发点在哪里都可以得到一个最优的轨迹(trajectory)模型(不论起点,目前测试中一般通过多个随机seed去测试),具体可以参考博主的另外篇博文深度强化学习简介.
1.1.1 On-Policy和off-Policy区别
On-policy和Off-policy这两个词在强化学习领域非常重要,知乎上有很多关于其讨论强化学习中on-policy 与off-policy有什么区别?,最典型的莫过于李宏毅老师下棋形象例子解释,还可以从以下方式解释:
【补充】两者在学习方式上的区别:若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。两者在采样数据利用上的区别:On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。
其实最经典的莫过于Sutton老爷子Introduction中的解释:
原文:On-policy methods attempt to evaluate or improve the policy that is used to make decisions, whereas off-policy methods evaluate or improve a policy different from that used to generate the data.
此外莫过于Q-learning和sarsa算法的解释图片
最终总结一下两者的优缺点:
on-policy优点是直接了当,速度快,劣势是不一定找到最优策略。off-policy劣势是曲折,收敛慢,但优势是更为强大和通用。
本文之所以解释On-policy或者off-policy的相关内容,目的在于后文讨论以下几个问题:
如何从采样轨迹(trajectory)中高效学习 Off-policy采样效率高,收敛慢,仍然是最重要的解决问题方法 1.1.2 Online和Offline学习的本质 监督学习中通常利用已知(已标记)的数据进行学习,其本质是从数据中总结规律,这和人从学1+1=2基本原理一致,强化学习的过程也是如此,仍然是从数据中学习,只不过强化学习中学习的数据是一系列的轨迹
所以重点来了,这里的数据才是最关键的一部分,这也强化学习中Online和offline学习中的关键, Online一方面是与环境有交互,通过采集数据学习、然后丢弃,而offline则是不用交互,直接通过采集到的轨迹数据学习,这也是off-policy到offline转换的重要原因。
1.2 落地应用的困难? 目前atari, mujoco物理引擎等各类游戏中的模拟数据很轻松拿到,这也就是目前强化学习在游戏领域非常成功的原因之一,也是各种state of the art刷榜的体现,因为游戏数据可以很轻松就100million,总结起来就是
有模拟器,易产生数据,好用!
但强化学习在落地过程中就可能遇到很多问题,比如下图这个大家伙,

总不可能让他产生100 million数据吧(不知道他的额定寿命是多少次),因此产生如下几个问题:
由于样本收集很困难,或者很危险。所以实时的和环境进行交互是不太可能的,那么可否有一种仅利用之前收集的数据来训练的方法去学习策略呢? 不管它是on-policy还是off_policy,我只要经验回放池中的交互历史数据,往大一点就是logg数据库中的数据(此处就不能探索exploration),去拟合函数是否可行? 仅利用轨迹数据学习的策略能否和Online算法的媲美? 所以有这样的方法吗?
答案:有,OfflineRL,此处有矿,赶紧来挖!
