入门 | 从Q学习到DDPG,一文简述多种强化学习算法
选自towardsdatascience
作者:Steeve Huang
机器之心编译
参与:Edison Ke、路雪
本文简要介绍了强化学习及其重要概念和术语,并着重介绍了 Q-Learning 算法、SARSA、DQN 和 DDPG 算法。

强化学习(RL)指的是一种机器学习方法,其中智能体在下一个时间步中收到延迟的奖励(对前一步动作的评估)。这种方法主要用于雅达利(Atari)、马里奥(Mario)等游戏中,表现与人类相当,甚至超过人类。最近,随着与神经网络的结合,这种算法不断发展,已经能够解决更复杂的任务,比如钟摆问题。
虽然已经有大量的强化学习算法,但似乎并没有什么文章对它们进行全面比较。每次需要决定将哪些算法应用于特定的任务时,都让我很纠结。本文旨在通过简要讨论强化学习的设置来解决这个问题,并简要介绍一些众所周知的算法。
1. 强化学习入门
通常,强化学习的设置由两部分组成,一个是智能体(agent),另一个是环境(environment)。
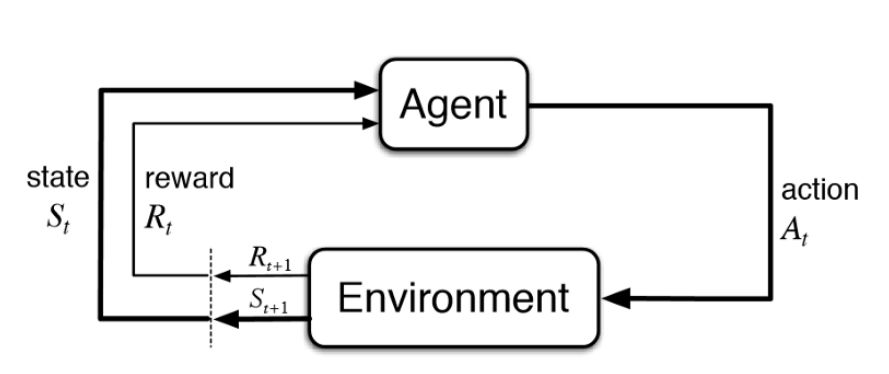
强化学习图示
环境指的是智能体执行动作时所处的场景(例如雅达利游戏中的游戏本身),而智能体则表示强化学习算法。环境首先向智能体发送一个状态,然后智能体基于其知识采取动作来响应该状态。之后,环境发送下一个状态,并把奖励返回给智能体。智能体用环境所返回的奖励来更新其知识,对上一个动作进行评估。这个循环一直持续,直到环境发送终止状态来结束这个事件。
大多数强化学习算法遵循这一模式。下面我将简要介绍强化学习中的一些术语,以方便下一节的讨论。
定义
1. 动作(A):智能体可以采取的所有可能的行动。
2. 状态(S):环境返回的当前情况。
3. 奖励(R):环境的即时返回值,以评估智能体的上一个动作。
4. 策略(π):智能体根据当前状态决定下一步动作的策略。
5. 价值(V):折扣(discount)下的长期期望返回,与 R 代表的短期返回相区分。Vπ(s) 则被定义为策略 π 下当前状态**s**的期望长期返回值。
6. Q 值或行动值 (Q):Q 值与价值相似,不同点在于它还多一个参数,也就是当前动作 a。Qπ(s, a) 指当前状态**s**在策略π下采取动作 a 的长期回报。
无模型(Model-free)vs. 基于模型(Model-based)
这里的模型指的是环境的动态模拟,即模型学习从当前状态 s0 和动作 a 到下一个状态 s1 的转移概率 T(s1|(s0, a))。如果成功地学习了转移概率,那么智能体将知道给定当前状态和动作时,进入特定状态的可能性。然而,当状态空间和动作空间增长(S×S×A,用于表格设置)时,基于模型的算法就变得不切实际了。
另一方面,无模型算法依赖试错来更新知识。因此,它不需要空间来存储所有状态和动作的组合。下一节讨论的所有算法都属于这一类。
在策略(on-policy)vs. 离策略(off-policy)
在策略智能体基于当前动作 a 学习价值,而离策略智能体基于局部最优的贪心行为(greedy action)a* 学习价值。(我们将在 Q-Learning 和 SARSA 算法部分进一步讨论这个问题)
2. 各种算法的说明
2.1 Q-learning 算法
Q-Learning 是基于贝尔曼方程(Bellman Equation)的离策略、无模型强化学习算法:
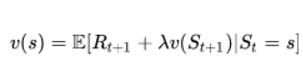
贝尔曼方程
其中,E 代表期望,ƛ 是折扣因子(discount factor)。我们可以将它重写成 Q 值的形式:
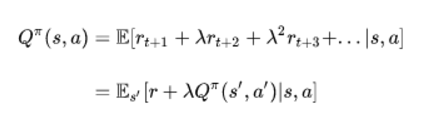
Q 值形式的贝尔曼方程
最优的 Q 值 Q*,可以表示为:
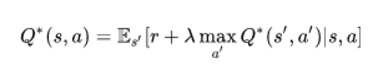
最优 Q 值
目标是最大化 Q 值。在深入探讨优化 Q 值的方法之前,我想讨论两个与 Q-learning 密切相关的值更新方法。
策略迭代法
策略迭代法交替使用策略评估和策略改进。
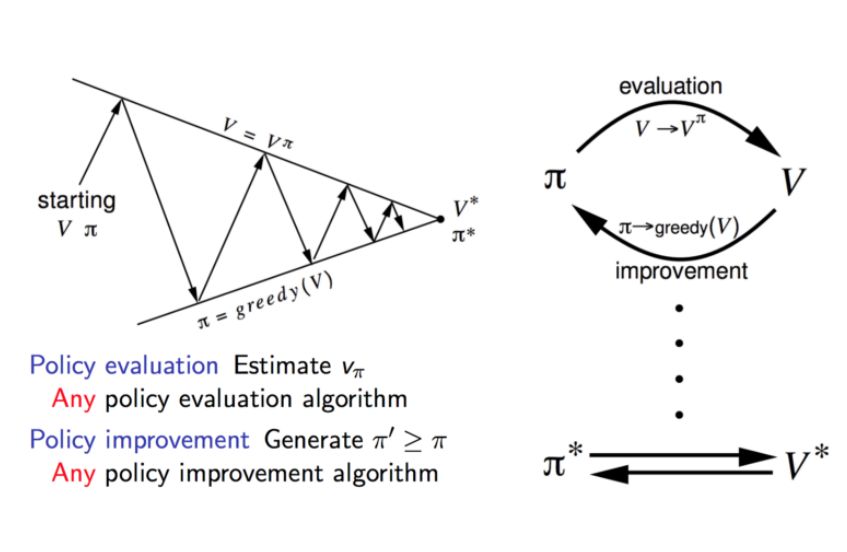
策略迭代法
策略评估会评估从上次策略改进中获得的贪心策略的价值函数 V。另一方面,策略改进通过使每个状态的 V 值最大化的动作来更新策略。更新方程以贝尔曼方程为基础。它不断迭代直到收敛。

策略迭代的伪代码
价值迭代
价值迭代只包含一个部分。它基于最优贝尔曼方程来更新值函数 V。
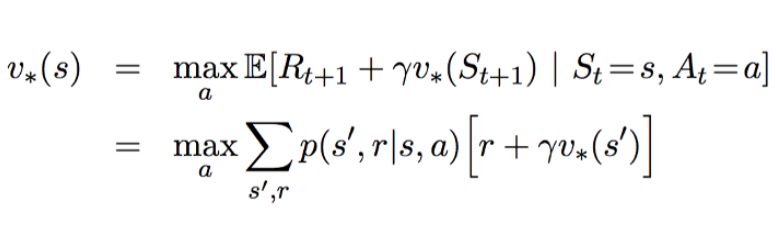
最优贝尔曼方程

价值迭代的伪代码
在迭代收敛之后,通过对所有状态应用最大值函数直接导出最优策略。
注意,这两种方法都需要知道转移概率 p,这表明它是一个基于模型的算法。但是,正如我前面提到的,基于模型的算法存在可扩展性问题。那么 Q-learning 如何解决这个问题呢?

Q-Learning 更新方程
α 指学习速率(即我们接近目标的速度)。Q-learning 背后的思想高度依赖于价值迭代。然而,更新方程被上述公式所取代。因此,我们不再需要担心转移概率。

Q-learning 的伪代码
注意,下一个动作 a』 的选择标准是要能够最大化下一个状态的 Q 值,而不是遵循当前的策略。因此,Q-Learning 属于离策略算法。
2.2 状态-动作-奖励-状态-动作(State-Action-Reward-State-Action,SARSA)
SARSA 很像 Q-learning。SARSA 和 Q-learning 之间的关键区别是 SARSA 是一种在策略算法。这意味着 SARSA 根据当前策略执行的动作而不是贪心策略来学习 Q 值。
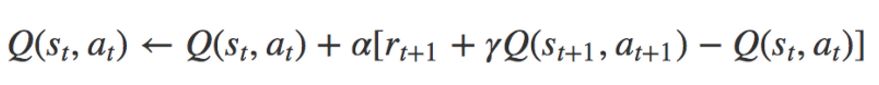
SARSA 的更新方程
动作 a_(t+1) 是在当前策略下的下一个状态 s_(t+1) 执行的动作。

SARSA 的伪代码
从上面的伪代码中,你可能会注意到执行了两个动作选择,它们始终遵循当前策略。相比之下,Q-learning 对下一个动作没有约束,只要它能最大化下一个状态的 Q 值就行了。因此,SARSA 是一种在策略算法。
2.3 深度 Q 网络(Deep Q Network,DQN)
Q-learning 是一种非常强大的算法,但它的主要缺点是缺乏通用性。如果你将 Q-learning 理解为在二维数组(动作空间×状态空间)中更新数字,那么它实际上类似于动态规划。这表明 Q-learning 智能体不知道要对未见过的状态采取什么动作。换句话说,Q-learning 智能体没有能力对未见过的状态进行估值。为了解决这个问题,DQN 引入神经网络来摆脱二维数组。
DQN 利用神经网络来估计 Q 值函数。网络的输入是当前的动作,而输出是每个动作对应的 Q 值。
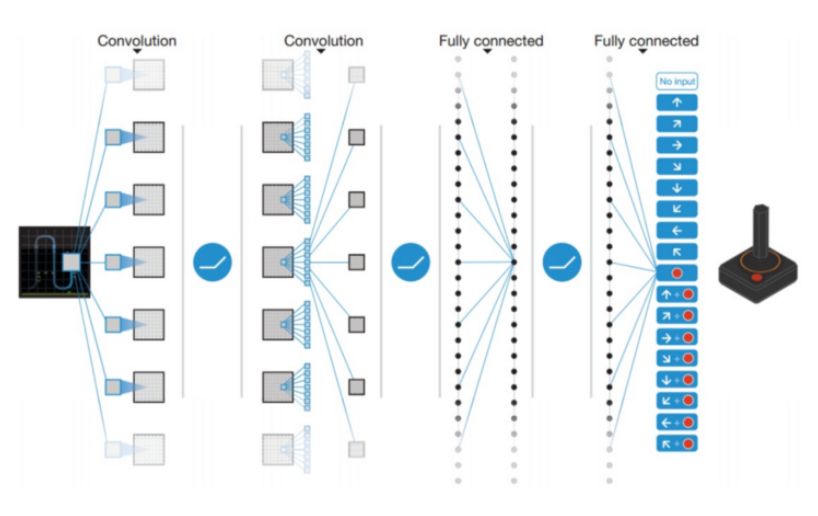
用 DQN 玩雅达利游戏
2013 年,DeepMind 将 DQN 应用于雅达利游戏,如上图所示。输入是当前游戏场景的原始图像,经过包括卷积层和全连接层的多个层,输出智能体可执行的每个动作的 Q 值。
问题归结为:我们如何训练网络?
答案是基于 Q-learning 更新方程来训练网络。回想一下 Q-learning 的目标 Q 值是:
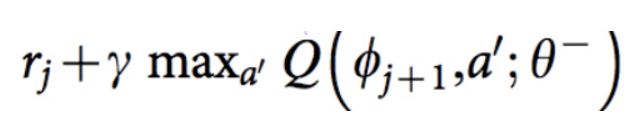
目标 Q 值
ϕ 相当于状态 s,𝜽 代表神经网络里的参数。因此,网络的损失函数可定义为目标 Q 值与网络 Q 值输出之间的平方误差。

DQN 的伪代码
另外两种技术对于训练 DQN 也很重要:
1. 经验回放(Experience Replay):由于典型强化学习设置中的训练样本高度相关,且数据效率较低,这将导致网络更难收敛。解决样本分布问题的一种方法是采用经验回放。从本质上讲,样本转换会被存储,然后从「转换池」中随机选择该转换来更新知识。
2. 分离目标网络(Separate Target Network):目标 Q 网络与用来估值的网络结构相同。根据上面的伪代码,在每个 C 步骤,目标网络都被重置为另一个。因此,波动变得不那么严重,带来了更稳定的训练。
2.4 深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)
虽然 DQN 在高维问题上取得了巨大的成功,例如雅达利游戏,但动作空间仍然是离散的。然而,许多有趣的任务,特别是物理控制任务,动作空间是连续的。而如果你把动作空间分离得太细来趋近连续空间,你的动作空间就太大了。例如,假设自由随机系统的自由度为 10。对于每一个自由度,你把空间分成 4 个部分,你最终就会有有 4¹⁰= 1,048,576 个动作。对于这么大的动作空间来说,收敛也是极其困难的。
DDPG 依赖于「行动者-评论家」(actor-critic)架构。行动者用来调整策略函数的参数𝜽,即决定特定状态下的最佳动作。
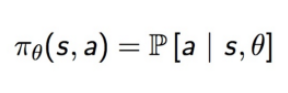
策略函数
而评论家用于根据时间差分(temporal difference,TD)误差来评估行动者估计出来的策略函数。
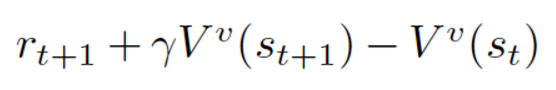
时间差分误差
在这里,小写的 v 表示行动者已经确定的策略。看起来很熟悉对吗?看着像 Q-learning 的更新方程!TD 学习是一种学习如何根据给定状态的未来值来预测价值的方法。Q-learning 是 TD 学习的一种特殊类型,用于学习 Q 值。
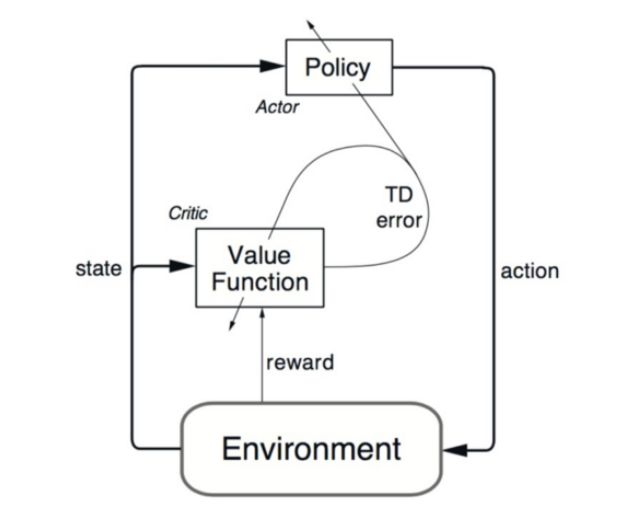
「行动者-评论家」架构
DDPG 还从 DQN 借鉴了经验回放和分离目标网络的思想。DDPG 的另一个问题是它很少对动作进行探索。一个解决方案是在参数空间或动作空间中添加噪声。
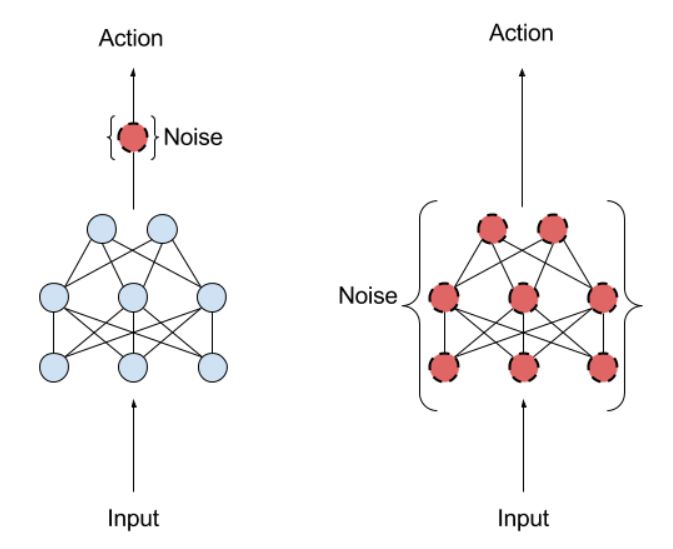
动作噪声(左),参数噪声(右)
OpenAI 这篇博客认为在参数空间上添加噪声比在动作空间上添加要好得多。一个常用的噪声是 Ornstein-Uhlenbeck 随机过程。

DDPG 的伪代码

原文链接:https://towardsdatascience.com/introduction-to-various-reinforcement-learning-algorithms-i-q-learning-sarsa-dqn-ddpg-72a5e0cb6287
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


