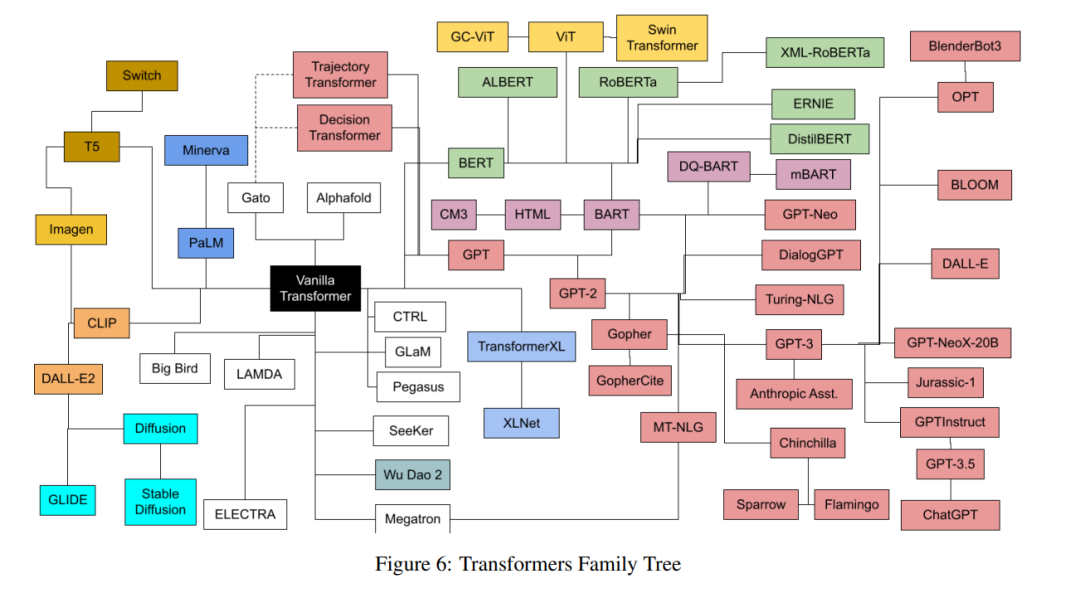
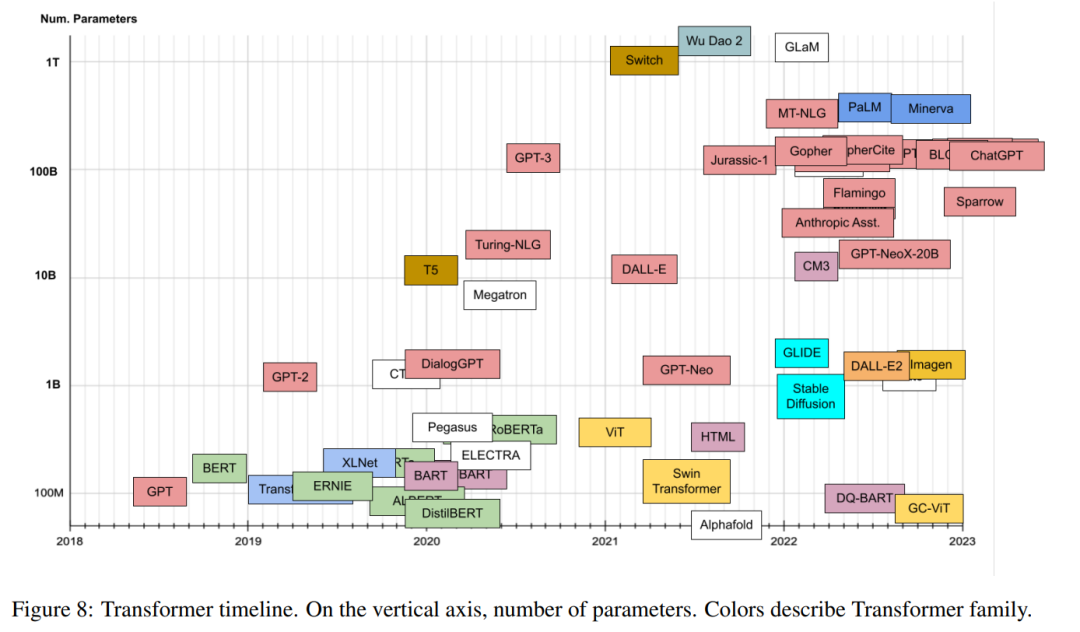
最近OpenAI推出的ChatGPT持续成为热点,背后依赖的GPT-3.5预训练语言模型和指令人类反馈强化学习等技术。ChatGPT背后大模型(也称预训练模型、基础模型等)通常是在大规模无标注数据上进行训练,学习出一种特征和规则,核心是Transformer算法与架构。来自Xavier Amatriain最新的Transformer预训练模型分类,36页pdf详述大模型分类图。

在过去的几年里,我们已经看到了几十种Transformer家族的模型的迅速出现,它们的名字都很有趣,但并不是不言自明的。本文的目标是对最流行的Transformer模型提供一个有点全面但简单的目录和分类。本文还介绍了Transformer模型的最重要方面和创新。
1. 引言
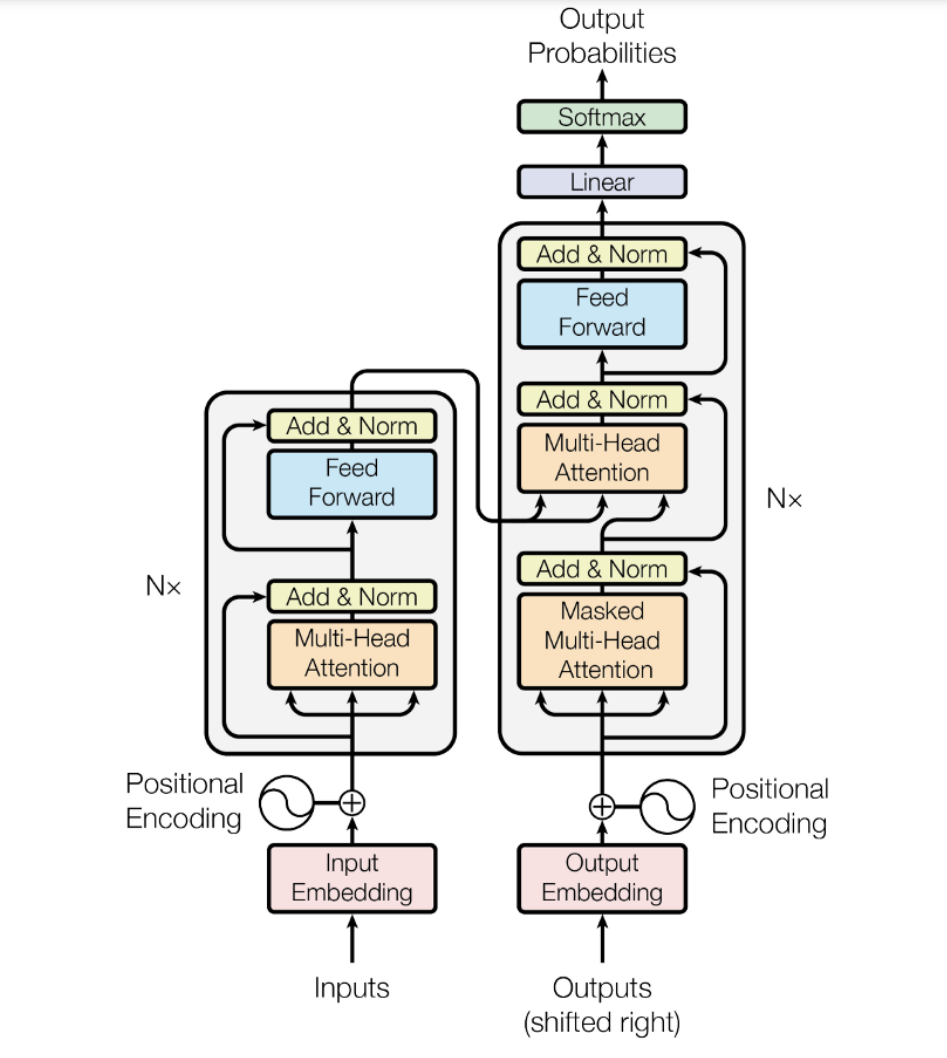
Transformer是一类深度学习模型,由一些架构特征定义。2017年,谷歌的研究人员在现在著名的“Attention is All you Need”论文1和相关的博客post1中首次介绍了它们。Transformer架构是前2 - 3年流行的编码器-解码器模型[2]2的一个具体实例。然而,在那之前,注意力只是这些模型使用的机制之一,这些模型主要基于LSTM(长短期记忆)[3]和其他RNN(递归神经网络)[4]变体。正如标题所暗示的那样,transformer论文的关键见解是,注意力可以用作获得输入和输出之间依赖关系的唯一机制。Transformer架构的所有细节已经超出了本博客的范围。为此,我建议你参考上面的原始论文或精彩的the Illustrated transformers帖子。话虽如此,我们将简要描述最重要的方面,因为我们将在下面的目录中提到它们。让我们从原始论文中的基本架构图开始,并描述一些组件。
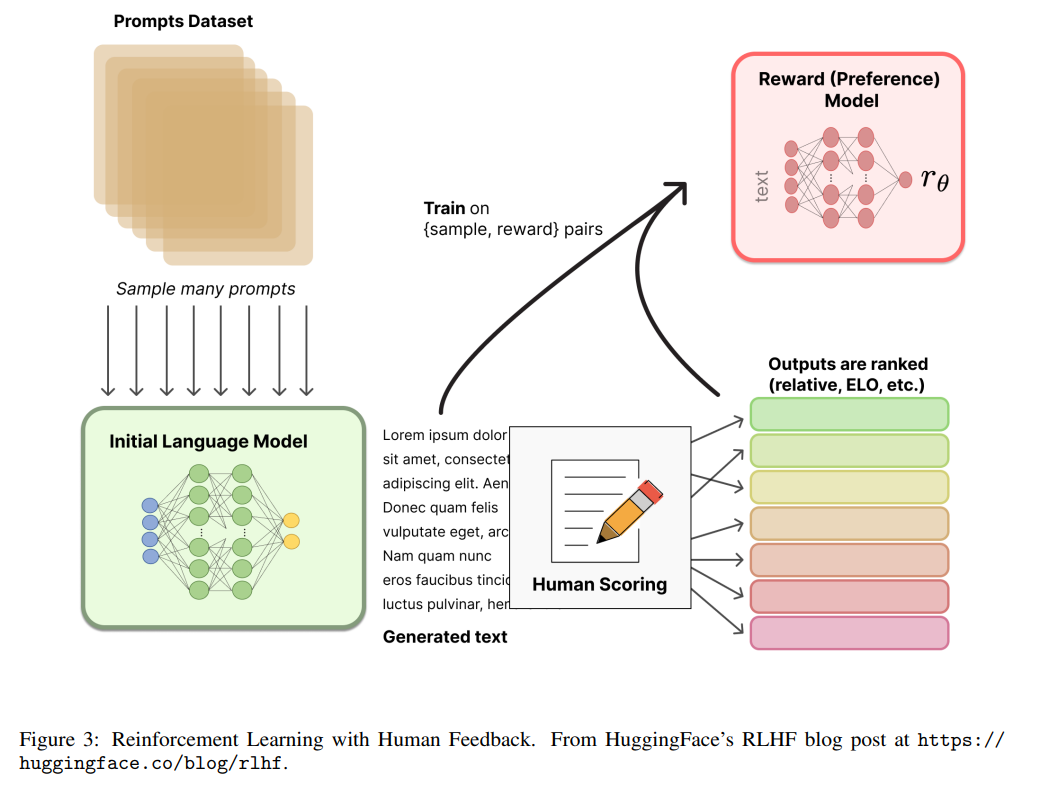
从人类反馈(或偏好)中进行强化学习,即RLHF(或RLHP),最近已经成为AI工具包的一个巨大补充。这一概念已经在2017年的论文“Deep reinforcement learning from human preferences”中提出。最近,它已被应用于ChatGPT和类似的对话代理,如BlenderBot3或Sparrow。这个想法非常简单:一旦语言模型被预训练,我们就可以对对话产生不同的响应,并让人类对结果进行排名。在强化学习的背景下,我们可以使用这些排名(又名偏好或反馈)来训练奖励(见图3)。您可以在Huggingface]14或Weights and Bias15的这两篇精彩文章中阅读更多内容。
2. Transformers分类
希望到目前为止,您已经理解了什么是Transformer模型,以及为什么它们如此流行和有影响力。在本节中,我将介绍迄今为止开发的最重要的Transformer模型的目录。我将根据以下属性对每个模型进行分类:预训练架构、预训练任务、压缩、应用程序、年份和参数数量。让我们简要地定义它们: 预训练架构我们将Transformer架构描述为由Encoder和Decoder组成,对于最初的Transformer也是如此。然而,从那时起,已经取得了不同的进展,揭示了在某些情况下,只使用编码器,只使用解码器,或两者都是有益的。 编码器预训练这些模型也被称为双向编码或自编码,在预训练过程中只使用编码器,通常通过屏蔽输入句子中的单词并训练模型进行重构来完成。在预训练的每个阶段,注意力层可以访问所有输入单词。该模型族对于需要理解完整句子的任务最有用,如句子分类或抽取式问答。 解码器预训练
解码器模型通常被称为自回归模型,在预训练过程中只使用解码器,而预训练通常是为了迫使模型预测下一个单词。注意力层只能访问句子中给定单词之前的单词。它们最适合于涉及文本生成的任务。 Transformer(编码器-解码器)预训练编码器-解码器模型,也称为序列到序列,使用Transformer架构的两部分。编码器的注意力层可以访问输入中的所有单词,而解码器的注意力层只能访问输入中给定单词之前的单词。预训练可以使用编码器或解码器模型的目标来完成,但通常涉及更复杂的东西。这些模型最适合于根据给定输入生成新句子的任务,如摘要、翻译或生成式问答。**预训练任务 **当训练模型时,我们需要为模型定义一个学习任务。上面已经提到了一些典型的任务,例如预测下一个单词或学习重建被掩码的单词。《自然语言处理的预训练模型综述》[10]包括一个相当全面的预训练任务分类,所有这些任务都可以被认为是自监督的:
- 语言建模(LM):预测下一个标记(单向LM的情况下)或前一个和下一个标记(双向LM的情况下)
- 掩码语言建模(MLM):从输入句子中屏蔽一些标记,然后训练模型,用其余标记预测被屏蔽的标记 3.置换语言模型(PLM):与LM相同,但对输入序列进行随机置换。一个置换是从所有可能的置换中随机抽样得到的。然后选择一些token作为目标,并训练模型来预测这些目标。
- 降噪自编码器(DAE):采用部分损坏的输入(例如,从输入中随机采样token,并将其替换为“[MASK]”元素。从输入中随机删除标记,或按随机顺序打乱句子),并旨在恢复原始未失真的输入。
- 对比学习(CTL):通过假设一些观察到的文本对比随机采样的文本更相似,来学习文本对的得分函数。它包括: •深度信息最大化(DIM):最大化图像表示和图像局部区域之间的互信息;替换Token检测(RTD):根据Token的环境预测其是否被替换; 下一个句子预测(NSP):训练模型以区分输入的两个句子是否为训练语料库中的连续片段;和句子顺序预测(SOP):类似于NSP,但使用两个连续的片段作为正例,并使用相同的片段,但其顺序交换为负例在这里,我们将注意Transformer模型的主要实际应用。这些应用大多数将在语言领域(例如,问答、情感分析或实体识别)。然而,如前所述,一些Transformer模型也在NLP之外找到了应用,也包括在目录中。