深度强化学习入门,这一篇就够了!
王小新 编译整理
量子位 出品 | 公众号 QbitAI
对于大脑的工作原理,我们知之甚少,但是我们知道大脑能通过反复尝试来学习知识。我们做出合适选择时会得到奖励,做出不切当选择时会受到惩罚,这也是我们来适应环境的方式。如今,我们可以利用强大的计算能力,在软件中对这个具体过程进行建模,这就是强化学习。
最近,Algorithmia博客上的一篇文章,从基础知识、决策过程、实际应用、实践挑战和学习资源五个方面,详细地介绍了强化学习。
基础知识
我们可以用电子游戏来理解强化学习(Reinforcement Learning, RL),这是一种最简单的心智模型。恰好,电子游戏也是强化学习算法中应用最广泛的一个领域。在经典电子游戏中,有以下几类对象:
代理(agent,即智能体),可自由移动,对应玩家;
动作,由代理做出,包括向上移动和出售物品等;
奖励,由代理获得,包括金币和杀死其他玩家等;
环境,指代理所处的地图或房间等;
状态,指代理的当前状态,如位于地图中某个特定方块或房间中某个角落;
目标,指代理目标为获得尽可能多的奖励;
上面这些对象是强化学习的具体组成部分,当然也可仿照得到机器学习的各部分。在强化学习中,设置好环境后,我们能通过逐个状态来指导代理,当代理做出正确动作时会得到奖励。如果你了解马尔科夫决策过程(https://en.wikipedia.org/wiki/Markov_decision_process),那就能更好理解上述过程。
下图的迷宫中,有一只老鼠:

想象下你是那只老鼠,为了在迷宫中尽可能多地收集奖励(水滴和奶酪),你会怎么做?在每个状态下,即迷宫中的位置,你要计算出为获得附近奖励需要采取哪些步骤。当右边有3个奖励,左边有1个奖励,你会选择往右走。
这就是强化学习的工作原理。在每个状态下,代理会对所有可能动作(上下左右)进行计算和评估,并选择能获得最多奖励的动作。进行若干步后,迷宫中的小鼠会熟悉这个迷宫。
但是,该如何确定哪个动作会得到最佳结果?
决策过程
强化学习中的决策(Decision Making),即如何让代理在强化学习环境中做出正确动作,这里给了两个方式。
策略学习
策略学习(Policy Learning),可理解为一组很详细的指示,它能告诉代理在每一步该做的动作。这个策略可比喻为:当你靠近敌人时,若敌人比你强,就往后退。我们也可以把这个策略看作是函数,它只有一个输入,即代理当前状态。但是要事先知道你的策略并不是件容易事,我们要深入理解这个把状态映射到目标的复杂函数。
用深度学习来探索强化学习场景下的策略问题,这方面有一些有趣研究。Andrej Karpathy构建了一个神经网络来教代理打乒乓球(http://karpathy.github.io/2016/05/31/rl/)。这听起来并不惊奇,因为神经网络能很好地逼近任意复杂的函数。
乒乓球
Q-Learning算法
另一个指导代理的方式是给定框架后让代理根据当前环境独自做出动作,而不是明确地告诉它在每个状态下该执行的动作。与策略学习不同,Q-Learning算法有两个输入,分别是状态和动作,并为每个状态动作对返回对应值。当你面临选择时,这个算法会计算出该代理采取不同动作(上下左右)时对应的期望值。
Q-Learning的创新点在于,它不仅估计了当前状态下采取行动的短时价值,还能得到采取指定行动后可能带来的潜在未来价值。这与企业融资中的贴现现金流分析相似,它在确定一个行动的当前价值时也会考虑到所有潜在未来价值。由于未来奖励会少于当前奖励,因此Q-Learning算法还会使用折扣因子来模拟这个过程。
策略学习和Q-Learning算法是强化学习中指导代理的两种主要方法,但是有些研究者尝试使用深度学习技术结合这两者,或提出了其他创新解决方案。DeepMind提出了一种神经网络(https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf),叫做深度Q网络(Deep Q Networks, DQN),来逼近Q-Learning函数,并取得了很不错的效果。后来,他们把Q-Learning方法和策略学习结合在一起,提出了一种叫A3C的方法(https://arxiv.org/abs/1602.01783)。
把神经网络和其他方法相结合,这样听起来可能很复杂。请记住,这些训练算法都只有一个简单目标,就是在整个环境中有效指导代理来获得最大回报。
实际应用
虽然强化学习研究已经开展了数十年,但是据报告指出,它在当前商业环境中的落地还十分有限(https://www.oreilly.com/ideas/practical-applications-of-reinforcement-learning-in-industry)。这里面有很多方面原因,但都面临一个共同问题:强化学习在一些任务上的表现与当前应用算法仍有一定差距。
过去十年中,强化学习的大部分应用都在电子游戏方面。最新的强化学习算法在经典和现代游戏中取得了很不错的效果,在有些游戏中还以较大优势击败了人类玩家。
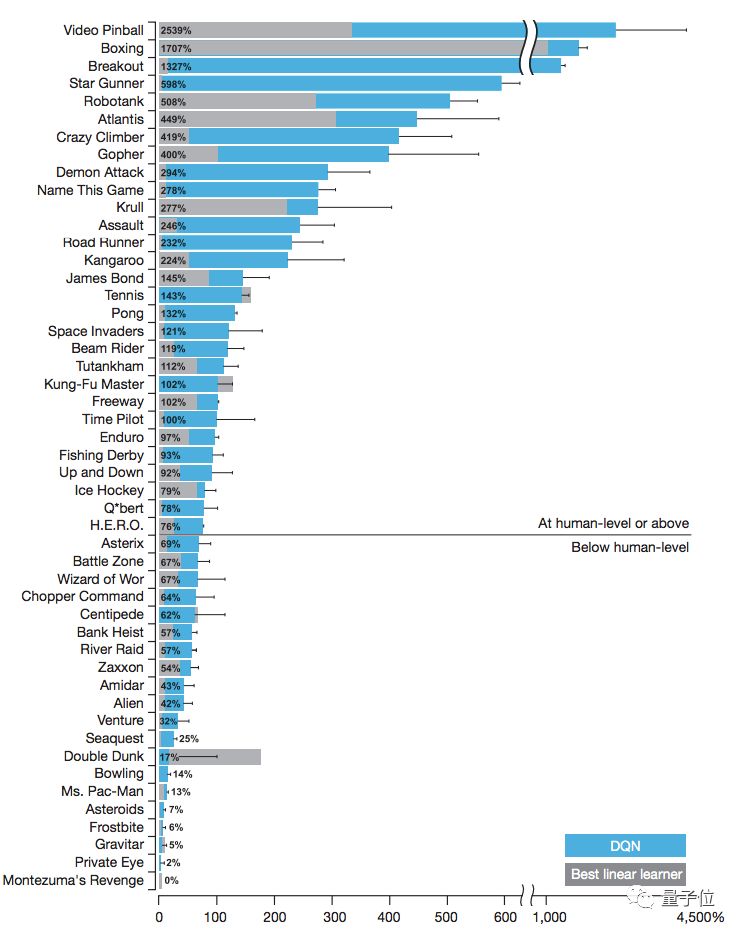
上图源自DeepMind的DQN论文。在超过一半的测试游戏中,论文中的代理能够优于人类测试基准,通常为人类水平的两倍。但在一些游戏中,这个算法的表现差于人类水平。
强化学习在机器人和工业自动化方面也有一些成功的实际应用。我们可以把机器人理解成环境中的代理,而强化学习已被证明是一种可行的指导方案。值得一提的是,Google还使用强化学习来降低数据中心的运营成本。
强化学习在医疗和教育方面也有望得到应用,但目前的大多数研究还处于实验室阶段。
实践挑战
强化学习的应用前景十分光明,但是实践道路会很曲折。

第一是数据问题。强化学习通常需要大量训练数据才能达到其他算法能高效率达到的性能水平。DeepMind最近提出一个新算法,叫做RainbowDQN,它需要1800万帧Atari游戏界面,或大约83小时游戏视频来训练模型,而人类学会游戏的时间远远少于算法。这个问题也出现在步态学习的任务中。
强化学习在实践中的另一个挑战是领域特殊性(domain-specificity)。强化学习是一种通用算法,理论上应该适用于各种不同类型的问题。但是,这其中的大多数问题都有一个具有领域特殊性的解决方案,往往效果优于强化学习方法,如MuJuCo机器人的在线轨迹优化。因此,我们要在权衡范围和强度之间的关系。
最后,在强化学习中,目前最迫切的问题是设计奖励函数。在设计奖励时,算法设计者通常会带有一些主观理解。即使不存在这方面问题,强化学习在训练时也可能陷入局部最优值。
上面提到了不少强化学习实践中的挑战问题,希望后续研究能不断解决这些问题。
学习资源
函数库
1、RL-Glue:提供了一个能将强化学习代理、环境和实验程序连接起来的标准界面,且可进行跨语言编程。
地址:http://glue.rl-community.org/wiki/Main_Page
2、Gym:由OpenAI开发,是一个用于开发强化学习算法和性能对比的工具包,它可以训练代理学习很多任务,包括步行和玩乒乓球游戏等。
地址:https://gym.openai.com/
3、RL4J:是集成在deeplearning4j库下的一个强化学习框架,已获得Apache 2.0开源许可。
地址:https://github.com/deeplearning4j/rl4j
4、TensorForce:一个用于强化学习的TensorFlow库。
地址:https://github.com/reinforceio/tensorforce
论文集
1、用通用强化学习算法自我对弈来掌握国际象棋和将棋
题目:Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
地址:https://arxiv.org/abs/1712.01815
这篇文章有13位作者,提出了AlphaZero方法。在这篇论文中,作者将先前的AlphaGo Zero方法推广到一个单一的AlphaZero算法,它可以在多个具有挑战性的领域实现超越人类的性能,同样利用的是“白板”强化学习(“白板”指的是所有知识均由感官和经验得来,即从零开始的学习)。从随机下棋开始,除了游戏规则外,没有输入任何领域知识,AlphaZero在24小时内实现了在国际象棋、将棋和围棋上超越人类水平的表现,并且在这三种棋上都以令人信服的成绩击败了当前的世界冠军程序。
2、深化强化学习综述
题目:Deep Reinforcement Learning: An Overview
地址:https://arxiv.org/abs/1701.07274
这篇论文概述了深度强化学习中一些最新精彩工作,主要说明了六个核心要素、六个重要机制和十二个有关应用。文章中先介绍了机器学习、深度学习和强化学习的背景,接着讨论了强化学习的核心要素,包括DQN网络、策略、奖励、模型、规划和搜索。
3、用深度强化学习玩Atari游戏
题目:Playing Atari with Deep Reinforcement Learning
地址:https://arxiv.org/abs/1312.5602
这是DeepMind公司2014年的NIPS论文。这篇论文提出了一种深度学习方法,利用强化学习的方法,直接从高维的感知输入中学习控制策略。该模型是一个卷积神经网络,利用Q-learning的变体来进行训练,输入是原始像素,输出是预测未来奖励的价值函数。此方法被应用到Atari 2600游戏中,不需要调整结构和学习算法,在测试的七个游戏中6个超过了以往方法并且有3个超过人类水平。
4、用深度强化学习实现人类水平的控制
题目:Human-Level Control Through Deep Reinforcement Learning
地址:https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
这是DeepMind公司2015年的Nature论文。强化学习理论根植于关于动物行为的心理学和神经科学,它可以很好地解释代理如何优化他们对环境的控制。为了在真实复杂的物理世界中成功地使用强化学习算法,代理必须面对这个困难任务:利用高维的传感器输入数据,推导出环境的有效表征,并把先前经验泛化到新的未知环境中。
讲座教程
1、强化学习(Georgia Tech, CS 8803)
地址:https://www.udacity.com/course/reinforcement-learning—ud600
官网介绍:如果你对机器学习感兴趣并且希望从理论角度来学习,你应该选择这门课程。本课程通过介绍经典论文和最新工作,带大家从计算机科学角度去探索自动决策的魅力。本课程会针对单代理和多代理规划以及从经验中学习近乎最佳决策这两个问题,来研究相应的高效算法。课程结束后,你将具备复现强化学习中已发表论文的能力。
2、强化学习(Stanford, CS234)
地址:http://web.stanford.edu/class/cs234/index.html
官网介绍:要实现真正的人工智能,系统要能自主学习并做出正确的决定。强化学习是一种这样的强大范式,它可应用到很多任务中,包括机器人学、游戏博弈、消费者建模和医疗服务。本课程详细地介绍了强化学习的有关知识,你通过学习能了解当前面临问题和主要方法,也包括如何进行泛化和搜索。
3、深度强化学习(Berkeley, CS 294, Fall 2017)
地址:http://rll.berkeley.edu/deeprlcourse/
官网介绍:本课程需要一定的基础知识,包括强化学习、数值优化和机器学习。我们鼓励对以下概念不熟悉的学习提前阅读下方提供的参考资料。课堂上开始前会简单回顾下这些内容。
4、用Python玩转深度强化学习(Udemy高级教程)
地址:https://www.udemy.com/deep-reinforcement-learning-in-python/
官网介绍:本课程主要介绍有关深度学习和神经网络在强化学习中的应用。本课程需要一定的基础知识(包括强化学习基础、马尔可夫决策、动态编程、蒙特卡洛搜索和时序差分学习),以及深度学习基础编程。
最后,原文地址在此:https://blog.algorithmia.com/introduction-to-reinforcement-learning/



