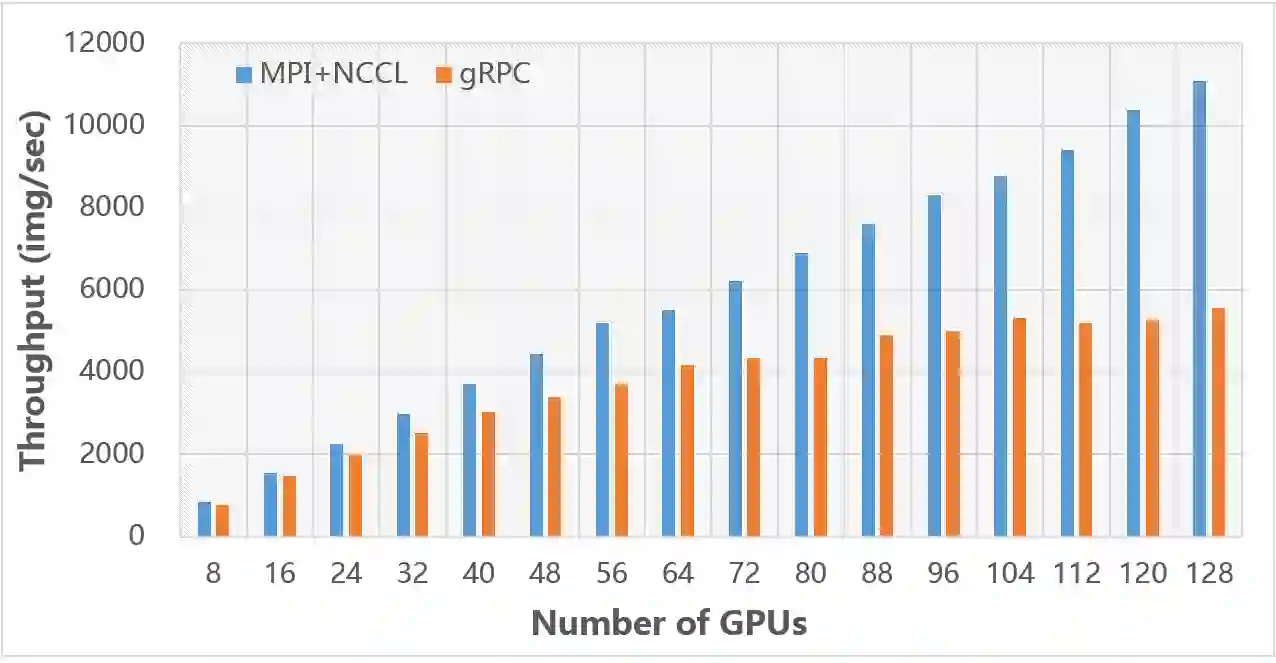
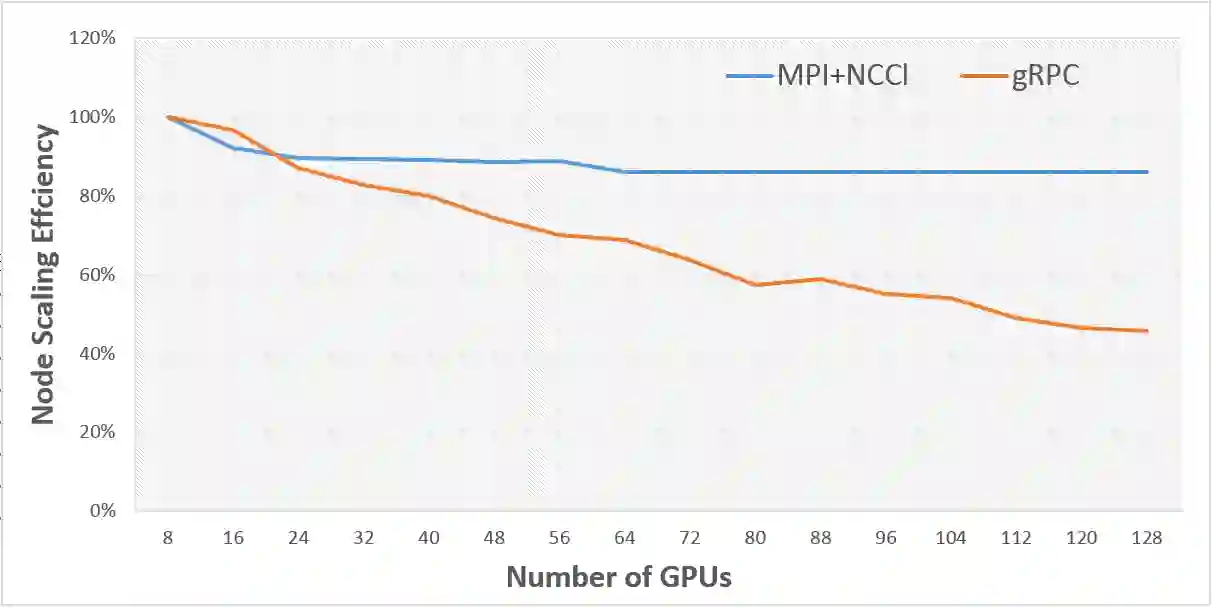
In existing visual representation learning tasks, deep convolutional neural networks (CNNs) are often trained on images annotated with single tags, such as ImageNet. However, a single tag cannot describe all important contents of one image, and some useful visual information may be wasted during training. In this work, we propose to train CNNs from images annotated with multiple tags, to enhance the quality of visual representation of the trained CNN model. To this end, we build a large-scale multi-label image database with 18M images and 11K categories, dubbed Tencent ML-Images. We efficiently train the ResNet-101 model with multi-label outputs on Tencent ML-Images, taking 90 hours for 60 epochs, based on a large-scale distributed deep learning framework,i.e.,TFplus. The good quality of the visual representation of the Tencent ML-Images checkpoint is verified through three transfer learning tasks, including single-label image classification on ImageNet and Caltech-256, object detection on PASCAL VOC 2007, and semantic segmentation on PASCAL VOC 2012. The Tencent ML-Images database, the checkpoints of ResNet-101, and all the training codehave been released at https://github.com/Tencent/tencent-ml-images. It is expected to promote other vision tasks in the research and industry community.
翻译:在现有的视觉代表学习任务中,深层革命神经网络(CNNs)往往在图像上培训,用图像网络等单个标签附加附加说明的图像。然而,单标签无法描述一个图像的所有重要内容,一些有用的视觉信息在培训过程中可能会被浪费。在这项工作中,我们提议对有线电视新闻网进行配有多个标记的图像培训,以提高受过训练的CNN模型的视觉代表质量。为此,我们建立了一个大型多标签图像数据库,有18M图像和11K类,称为Tentcent ML-Images。我们高效率地在Tentent ML-Imagages上用多标签产出来培训ResNet-101模型,在Tentent ML-Imags上用90小时进行多标签产出,在大规模分布式深层学习框架(即TFTFplus)的基础上,为有多个标记的图像网络信息,以提高CNNML-Images检查站的视觉代表的质量。为此,我们通过三个传输学习任务,包括图像网络的单一标签图像分类和Caltech 256,对PC 2007年 PASAL VOC的物体探测任务进行了目标探测,并在PASal-101 Smantennistrual-stal-stational-lagilmreal-stational-stational/Smreal-stations destal delpalmaxilpalpal.